INTRO
C++ is a general-purpose low-level programming language based on C language. While C is a procedural programming language that executes codes top-to-bottom, C++ allows object-oriented programming as well; thus, C++ is called a hybrid language. C++, an extension of C language, guarantees a wide range of applications from various features.
Compiled Language
There are two different categories of program languages based on its execution: compiled language and interpreted language.
An interpreter allows a computer to reads the source code written in English and execute directly, mostly benefitting from cross-platform support that can run the program on a different system and architecture. Python is one of the best examples of an interpreted language. However, a compiler generates an object file written in machine-friendly code by translating from English-written source code.
C++ language is a compiled language that doesn’t support cross-platform, but it processes faster than interpreted language due to its optimization to the current system.
Compiler
C++ language categorizes its compiler version by the year of standard released by the International Organization for Standardization(ISO); C++11 and C++17 is the most renowned version. This document introduces C++ language based on the C++11 compiler at minimum.
Preprocessor
A preprocessor is responsible for optimizing the source code before the compiler translates to binary code. A command for a preprocessor is called preprocessor directive and has octothorpe # at its prefix.
| DIRECTIVES | EXAMPLE | DESCRIPTION |
|---|---|---|
#include |
#include <iostream> |
Includes header file to the script. |
#define |
#define SQUARE |
Defines new macro for the project. |
#pragma |
#pragma once |
Provides additional options for the compiler. |
A preprocessor does not read C++ language source code nor follows C++ language syntax. It only processes its directives, removes comments, and provides optimized source code to the compiler. A preprocessor directive isn’t necessary but makes the coding easier and convenient. The preprocessor resides within the compiler program.
INSTALL
A compiler for C++ is essential when developing with C++ programming language, and there are various C++ compilers available designed by different companies and organizations. The compilation method may differ depending on the compiler, but it doesn’t matter for general users as every compiler observes the same ISO standard that defines the working mechanism.
An integrated development environment (IDE) is a software development program that provides a source code editor and program build tools, compiling source codes to an executable program. This chapter introduces the installation and configuration of an IDE for a C++ language project.
Visual Studio
Visual Studio is the most renowned IDE for Windows OS developed by Microsoft, which uses the MSVC compiler. There are three editions for Visual Studio, and the free community edition is enough for development. The IDE provides various components to support different languages as well; for C++ programming, select the “Desktop development with C++” workload.
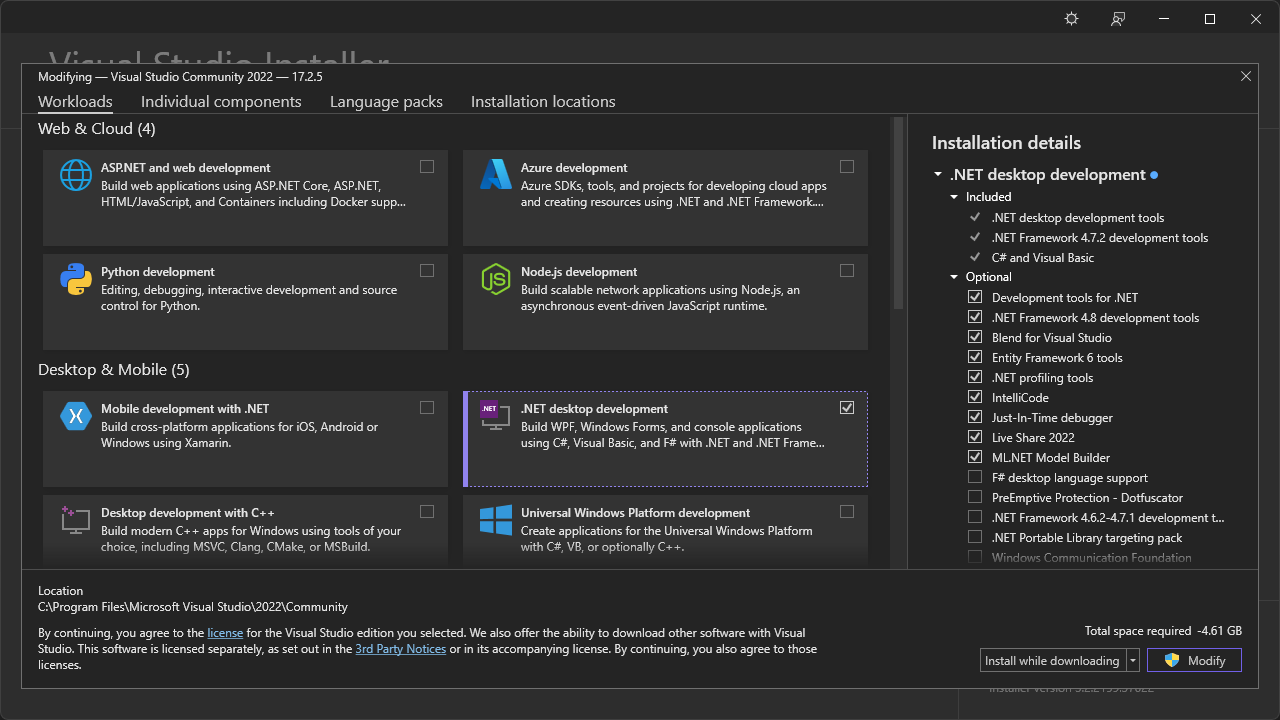
Visual Studio will start with the window shown below. To create a new project for C++ language, select the “Create a new project” button.
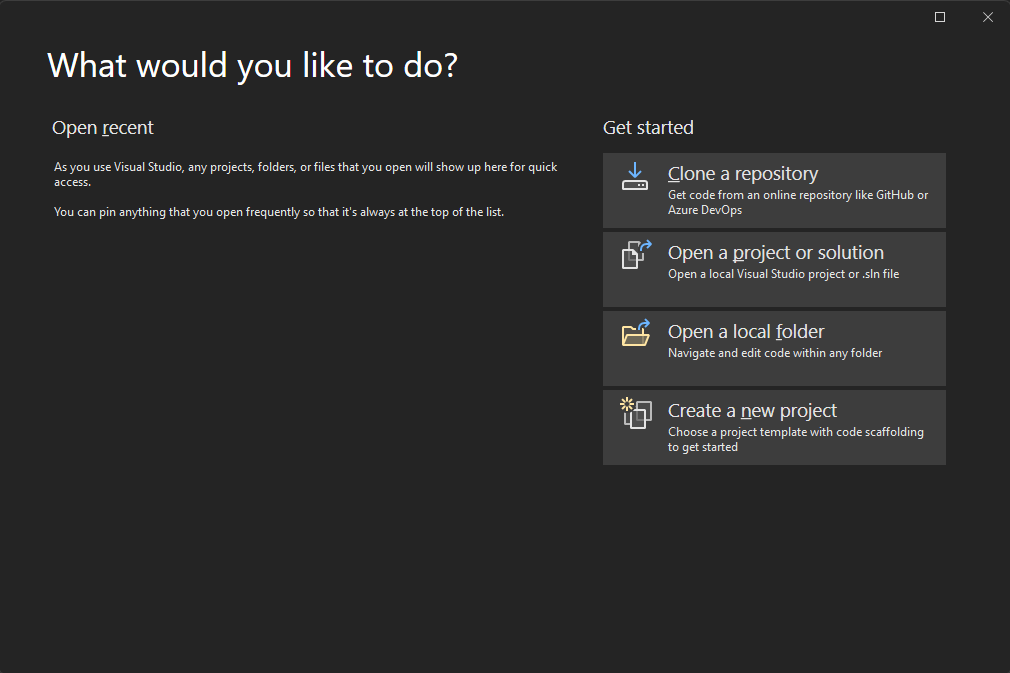
Since C++ can create various applications, there are many different kinds of projects available from Visual Studio as well. To create a C++ project, follow the procedure below:
- Select the language as C++ and choose the “Console App” option.
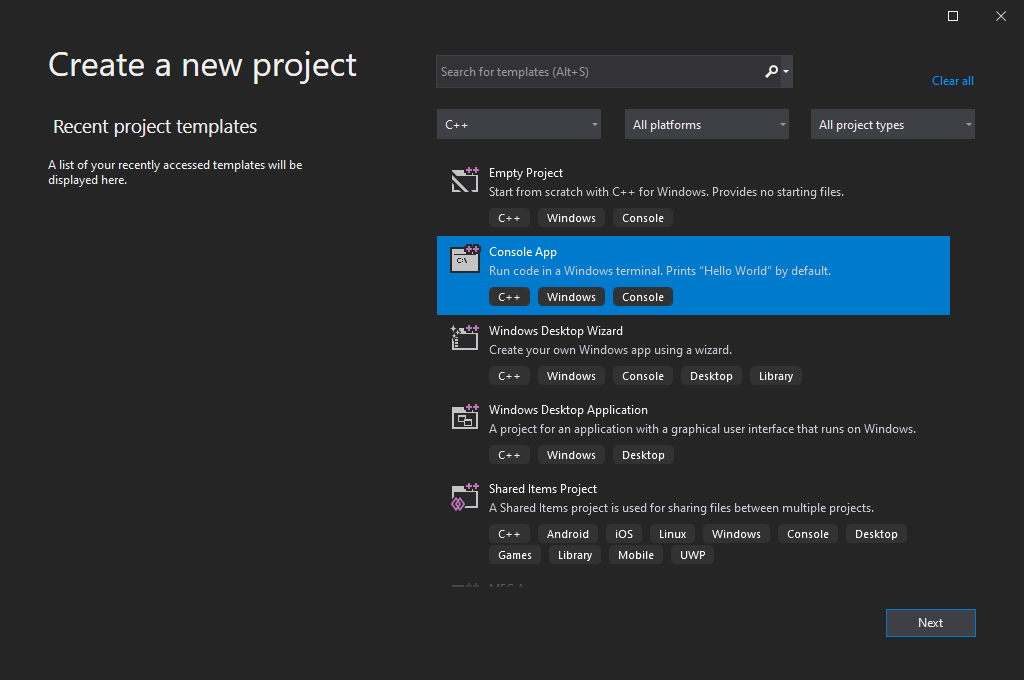
- Designate names for the project and solution. Here, the project is a
.vcxprojextension file that manages its source codes and compilation options, and the solution is a.slnextension file that can contain multiple projects. It is recommended to open the solution file on Visual Studio unless you only want to open a single project.
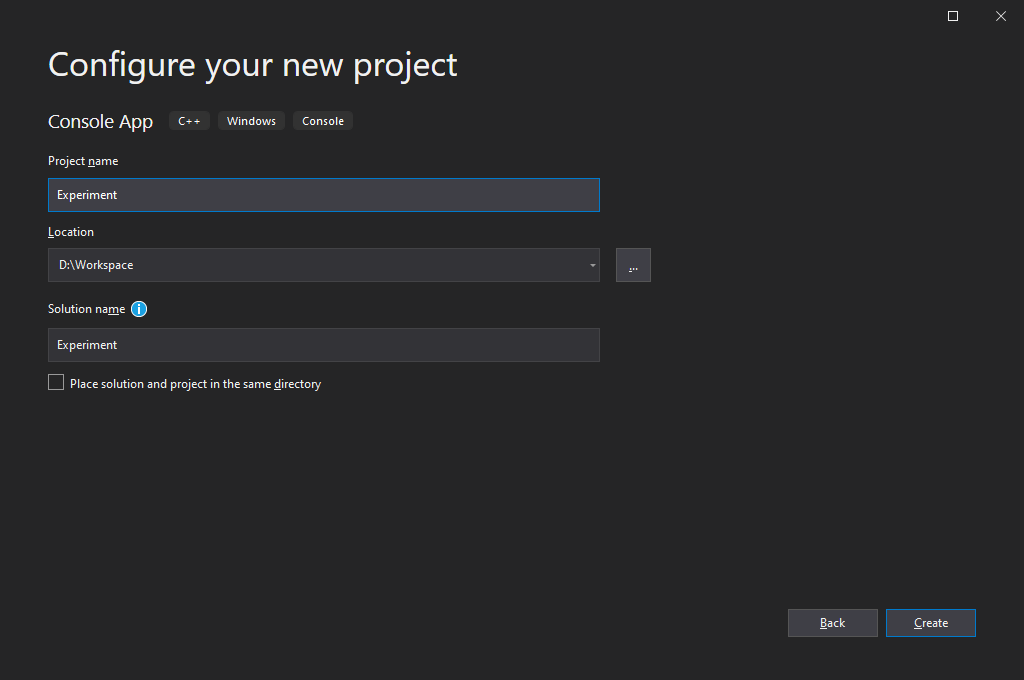
- Use the project automatically prepared by Visual Studio.
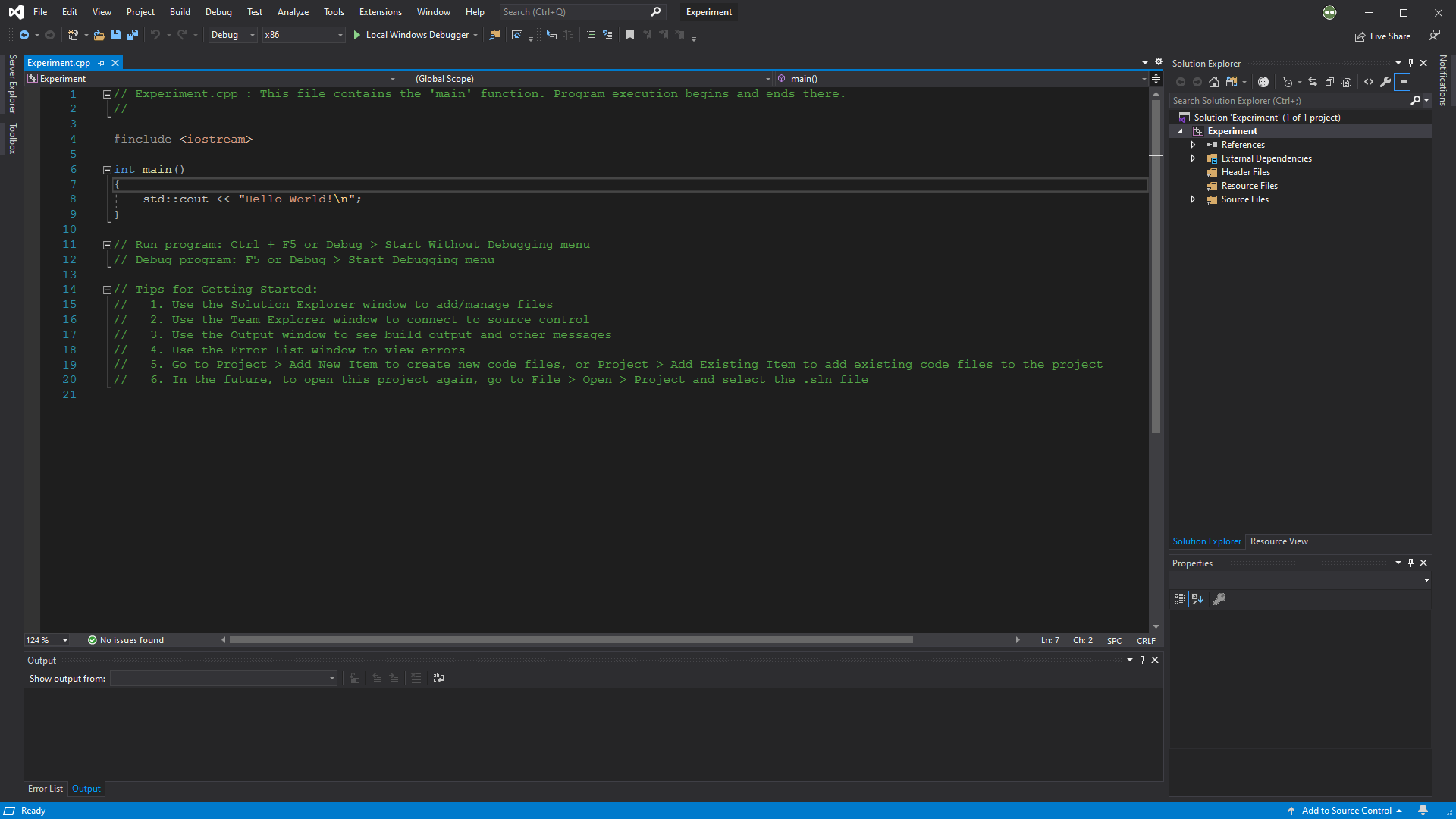
The three-step procedure above for creating a C++ console application is the simplest method. To create an empty C++ project, refer to the installation section on the PRGMING_C document.
Visual Studio can run a C++ language program in two different ways: debugging mode (F5) and without debugging mode (Ctrl+F5). Debugging mode is used to inspect the problem and visualize the process, otherwise run without debugging is recommended.
Xcode
Xcode is the most renowned IDE for macOS developed by Apple, which uses the clang compiler. Xcode supports various languages, and just like Visual Studio, Xcode has a project option for C++ language.
Start Xcode, then create a new project by selecting File > New > Project....
There are various projects available for developing an application for Apple’s product. To create a C++ project, follow the procedure below:
- Since the computer is macOS, select the macOS tab, then the Command Line Tool to execute a terminal-based program.
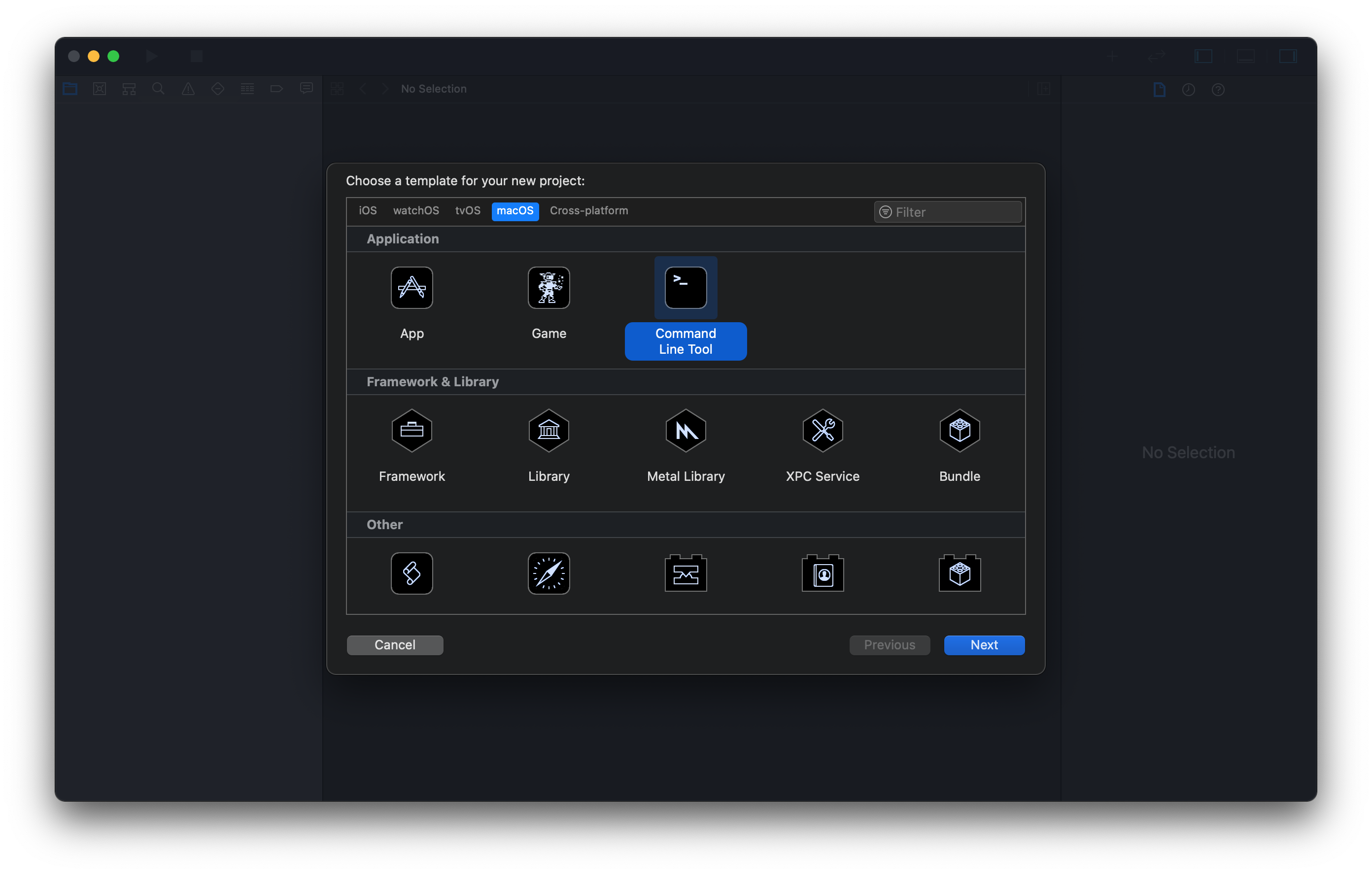
- Name a project in the Product Name and select the Language as C++.
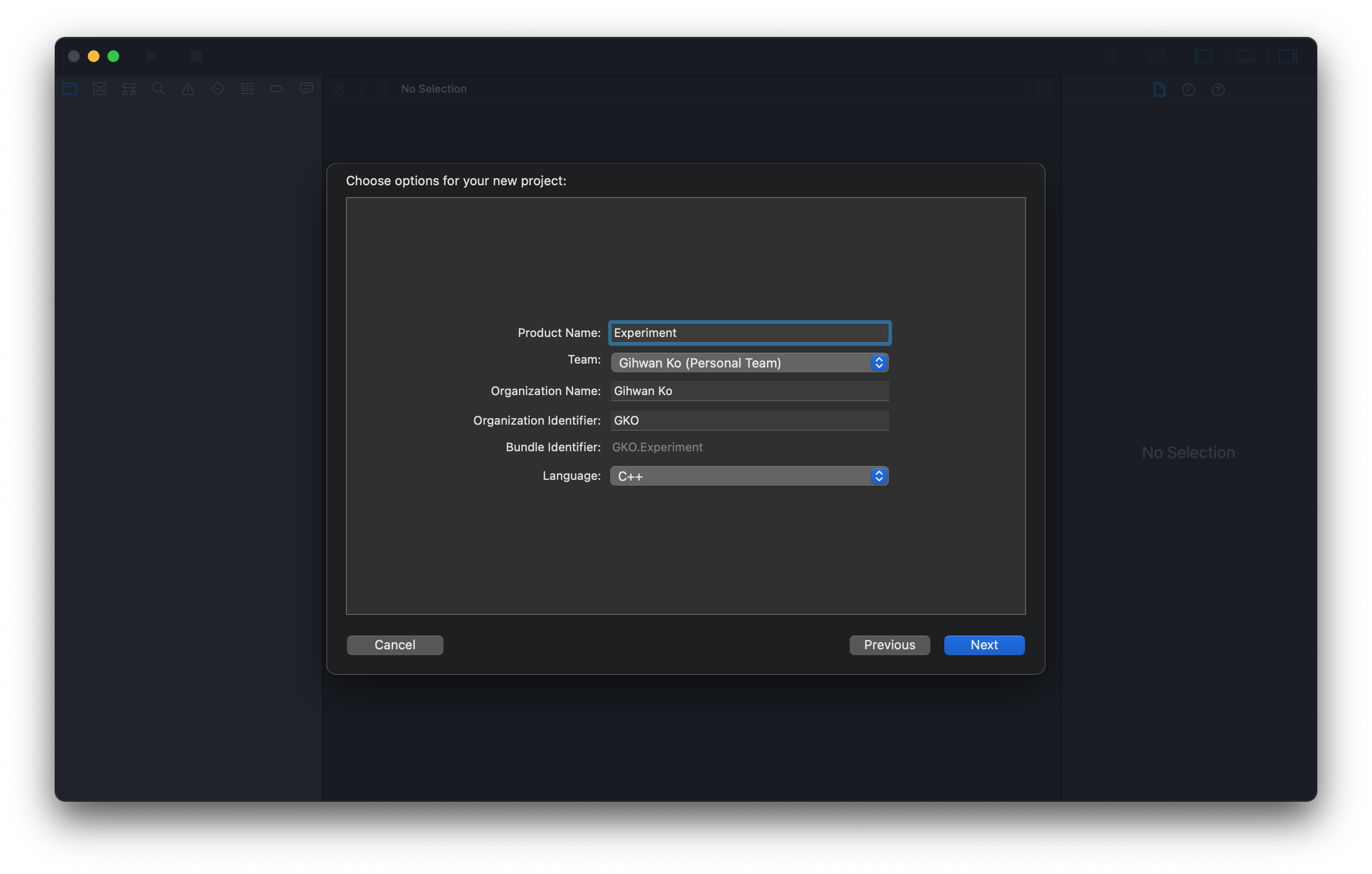
- Designate a path for the project.
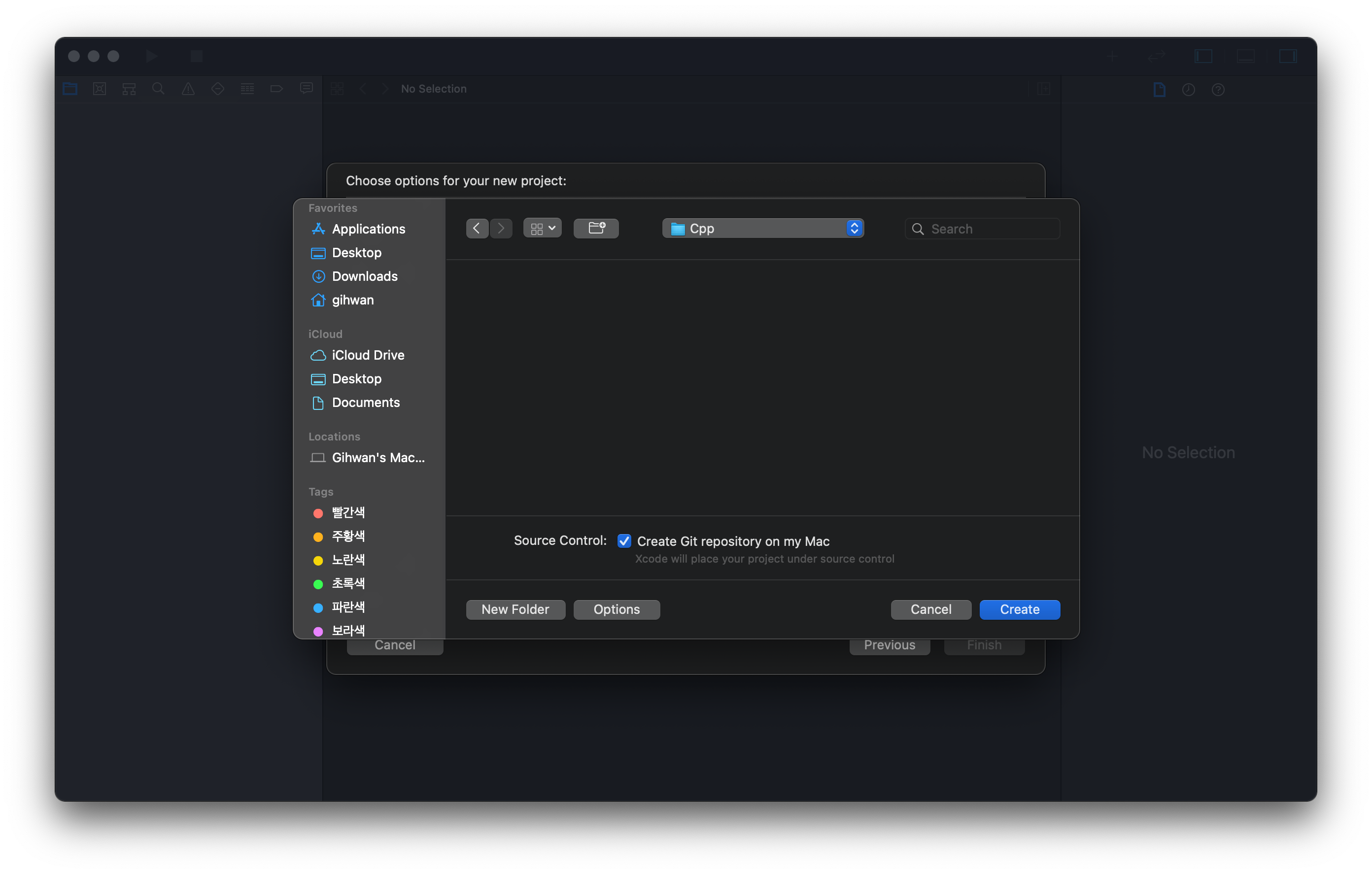
- The left panel shows there is the
main.cppsource file under theExperimentfolder with minimum codes required to run the program.
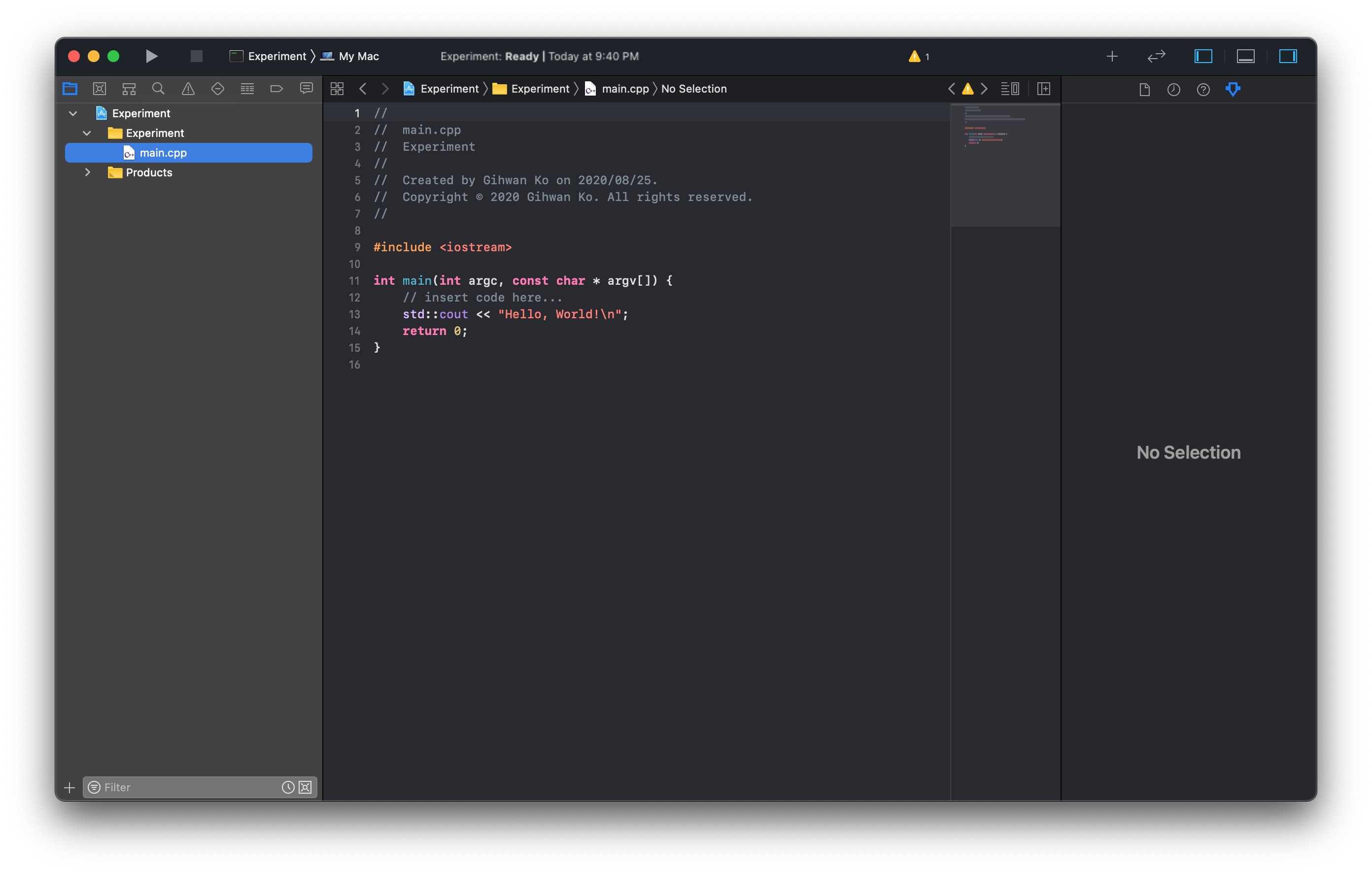
Xcode can run a C++ language program in two different ways: debugging mode and without debugging mode. Hotkey for both are ⌘+R and whether to debug or not is configured on project setting. Debugging mode is used to inspect the problem and visualize the process, otherwise run without debugging is recommended.
Terminal
Linux OS has G++ (GNU Compiler Collection for C++) compiler installed by default but without an IDE. However, IDE is not essential when compiling a source code, which is possible on a terminal as well. With the increasing number of projects starting to use a single-board computer (SBC) like Raspberry Pi, knowing how to develop software in Linux OS became crucial.
This section uses the code from Figure 10. Creating a C++ project on Xcode (step 4) to the main.cpp source file to show how to compile on Linux OS.
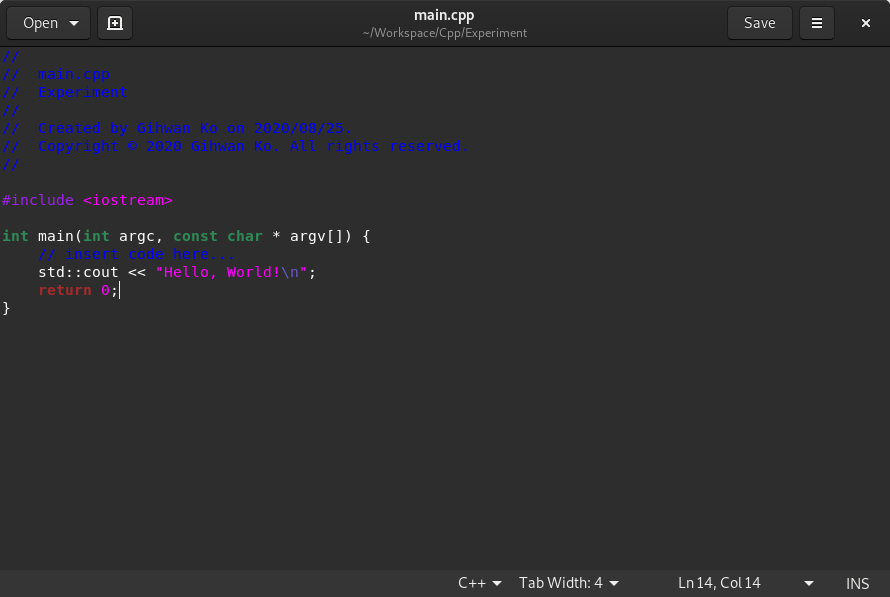
Suppose the main.c source file is at ~/Workspace/Cpp/Experiment directory.
Run a terminal and move to the directory where the source file is; change the current directory with the cd command. Enter the following command to compile the source code with GCC compiler.
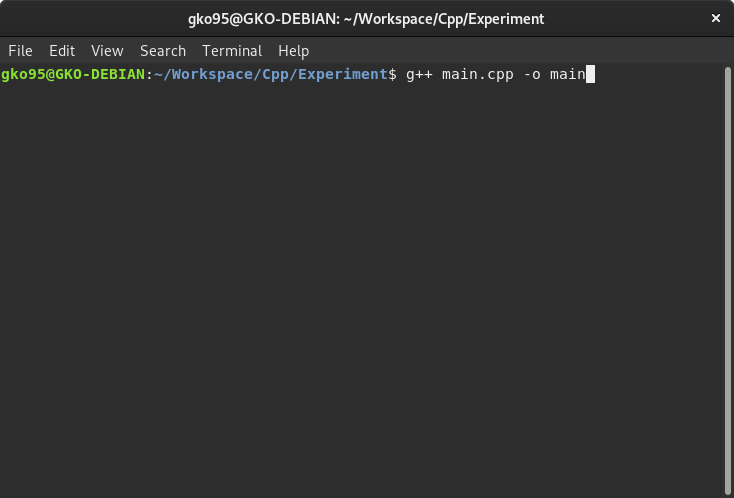
The command is ordering to compile the main.cpp source file and outputs (-o) the main object file. It is one of the simple commands of GCC compiler, and linking external libraries is also possible by adding more options.
The directory now has an object file called main, compiled from the source code.
To execute an object file from a terminal, place ./ followed by the file name.
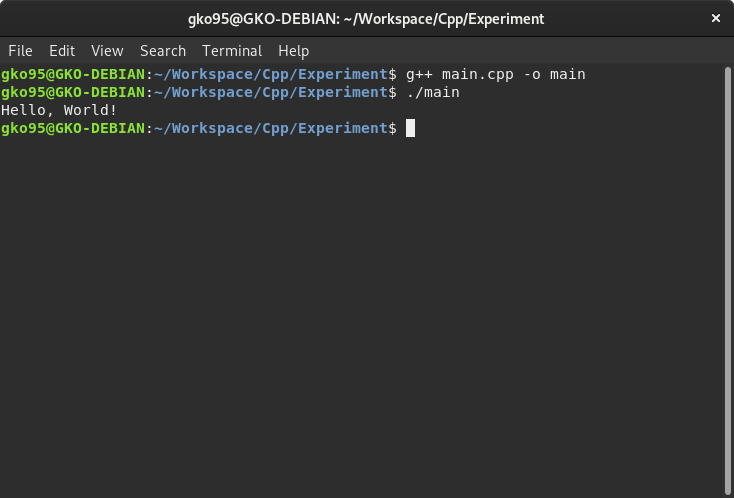
Here, the command ./ represents the current directory. Without this command, a terminal wouldn’t be able to find the main file unless the directory is specified by the environment variable.
BASIC
Every programming language has its own rules to be observed and fundamental data that works as a basis of the program. Failed to observe this causes either error or unexpected results. As for the beginning of the practical coding, this chapter will introduce basic knowledge of C++ language coding.
Header File
A header file is a .h (C compatible) or .hpp (C++ exclusive) extension file responsible for letting the script know the existence of data or functionalities. Commonly paired with a .c source file, header files can let the other source files to use the data and functionalities defined by its pair.
C++ language has header files for the source codes already compiled for developers to use, aka. a library. These libraries that come along with a compiler is called the standard library. Following are the header files for some of the C standard library:
| HEADER FILES | SYNTAX | DESCRIPTION |
|---|---|---|
iostream |
#include <iostream> |
Defines standard input/output function:operator >>, operator << |
string |
#include <string> |
Defines text-based string processing functions:append(), length() |
cmath |
#include <cmath> |
Defines common mathematical functions:exp(), cos() |
chrono |
#include <chrono> |
Defines date and time-handling functions:system_clock(), duration() |
There are two different ways of including a header file to the source code: angled brackets <> and double quotations "".
#include <iostream>
#include "header.hpp"
The difference between these twos is where the preprocessor should search for the header file from:
-
#include <header.hpp>- search directories pre-designated by the system, compiler, or IDE; this syntax is used to include a system header.
-
#include "header.hpp"- search from the current local directories where the source file is located. If failed to find the header, automatically search from pre-designated directories, just like
#include <header.hpp>does; this syntax is used to include a user-defined header.
Precompiled Header
A precompiled header is a header file that compiles into an intermediate form that is faster to process for a compiler. Because it reduces compilation time, a precompiled header is used on the project that includes many header files or a header file with enormous data.
However, using a precompiled header is not always beneficial because it takes more time to prepare for compilation. For a header file that is small or subject to change frequently, a precompiled header is unnecessary.
| PRECOMPILED HEADER | COMPILER |
|---|---|
stdafx.h |
Visual Studio 2015 (msvc14) and below |
pch.h |
Visual Studio 2017 (msvc15) and above |
Statement Terminator
The “statement” in programming represents a code that executes or processes data. In C++ language, every statement needs to end with a statement terminator denoted by a semicolon ;.
One of the common mistakes made by C++ language beginners is the absence of a statement terminator. Therefore, developers need to keep this in mind when programming with languages based on C (such as C++ and C#).
Comment
Comment in a programming language is not executed and is commonly used to write down information related to the programming on source codes. There exist two comments in C++ language: line comment and block comment.
-
- Line comment
- a comment worth a single line of code, declared by
//.
-
- Block comment
- a comment with multiple lines of code, declared by
/* */.
/*
BLOCK COMMENT:
multiple line of comment can be placed here.
*/
// LINE COMMENT: for a single line of code.
Identifier
An identifier is a name used to identify data in programming. In other words, it is just a user-defined name. C++ language has the following rules when naming an identifier:
- Only alphabet, number, and underscore
_is allowed. - First letter cannot start with a number.
- Blank space is prohibited.
Namespace
The namespace is a code space that distinguishes from the others to guarantee the uniqueness of identifiers. It is the same concept as placing files (data) with the same name in different folders (namespace).
The namespace keyword declares the namespace and stores the data inside the code block {}. Use the scope resolution operator :: to access the data inside the namespace. However, namespaces must not share the same name with other namespaces.
int variable;
namespace namespace1 {
int function1() {...}
}
namespace namespace2 {
int variable, fucntion() {...}
}
// CALLING FUNCTION LOCATED IN DIFFERENT NAMESPACE.
namespace1::function();
namespace2::function();
// CALLING VARIABLE LOCATED IN AND OUT OF NAMESPACE.
variable;
namespace2::variable;
Global Namespace
The global namespace is a code space that doesn’t belong to any namespace. Data from the global namespace is accessed by placing the scope resolution operator before its identifier.
::variable;
The scope resolution operator is a counterpart of the path separator / in the UNIX operating system that also represents the root directory when placed leftmost.
# UNIX DIRECTORY & PATH SEPARATOR (/)
/Users/gihwanko/Documents
// C++ NAMESPACE & SCOPE RESOLUTION (::)
::std::endl
The above syntax is identical to std::endl not included in any namespace.
using Keyword
The using keyword makes accessing data inside the namespace simple. Technically, data becomes available without needing to specify the namespace. The keyword can either simplify individual data (using declaration) or the whole namespace (using directive).
// USING DECLARATION: INDIVIDUAL DATA
using namespace1::function();
// USING DIRECTIVE: THE WHOLE NAMESPACE
using namespace namespace2;
However, the overuse of the using keyword has the potential to cause a naming collision as the compiler cannot tell which data the code is referencing.
Input & Output
C++ language has input and output for a text-based terminal available from the std namespace in the iostream header file, using extraction >> and insertion operator << respectively.
| INPUT/OUTPUT | SYNTAX | DESCRIPTION |
|---|---|---|
std::cin |
std::cin >> variable; |
Insert data to the variable from a console. |
std::cout |
std::cout << "Hello World!"; |
Prints data on a console |
int variable;
std::cout << "Enter the value: "
std::cin >> variable;
std::cout << "Hello World!" << variable << std::endl;
Enter the value: 10
Hello World!10
New-Line Manipulator
A new-line manipulator std::endl is the C++ Standard Library that ends and begins a new line.
std::cout << "Hello" << std::endl << "World!";
Hello
World!
Data Type
A data type is one of the crucial factors which determines the type and byte size of the data. A well-implemented data type can make a program efficient on both memory and processing time. C++ language has several numbers of built-in data type as follows:
| IDENTIFIER | DATA TYPE | DESCRIPTION |
|---|---|---|
int |
Integer | 32-bits precision integer number. Size: 4 bytes |
float |
Floating point number | Real number with a decimal point. Size: 4 bytes |
double |
Double-precision float | Float with a doubled precision and memory. Size: 8 bytes |
char |
Character: '' |
A single character, such as 'A' or '?'.Size: 1 byte |
string |
String: "" |
A series of characters, available from the std namespace.Size: N/A (varies by the length) |
bool |
Boolean | Non-zero represents true while zero is false.Size: 1 byte |
auto |
Automatic | Automatically selected by the compiler. Useful for declaring new variable with complex data type. |
void |
Void | Non-specific data type. Size: 1 byte |
sizeof() Operator
The sizeof() function returns allocated memory size of the type or data in bytes.
sizeof(int); // SIZE: 4 BYTE
sizeof(char); // SIZE: 1 BYTE
Variable
Variable is a container for data that can be assigned using the assignment operator =. C++ language must designate a variable with one of the data types, which can only have data with that data type.
The example code below tells a compiler the existence of the variable integer variable. The variable has also allocated memory at the same time to store a value, called definition in programming.
/* DEFINITION OF THE "variable" VARIABLE */
int variable = 3;
A variable may not have any variable but let a compiler know its existence, called declaration in programming.
/* DECLARATION OF THE "variable" VARIABLE */
int variable;
According to the ISO standard for C++, the definition and declaration are the same in general. The detailed documentation is on § 3.1.2 as follows:
A declaration is a definition unless it declares a function without specifying the function’s body (8.4), it contains the extern specifier (7.1.1) or a linkage-specification25 (7.5) and neither an initializer nor a function- body, it declares a static data member in a class definition (9.2, 9.4), it is a class name declaration (9.1), it is an opaque-enum-declaration (7.2), it is a template-parameter (14.1), it is a parameter-declaration (8.3.5) in a function declarator that is not the declarator of a function-definition, or it is a typedef declaration (7.1.3), an alias-declaration (7.1.3), a using-declaration (7.3.3), a static_assert-declaration (Clause 7), an attribute- declaration (Clause 7), an empty-declaration (Clause 7), a using-directive (7.3.4), an explicit instantiation declaration (14.7.2), or an explicit specialization (14.7.3) whose declaration is not a definition.
Below is a list of cases when a declaration is not a definition in C++ language.
- Forward declaration of a function and class
- Declaration of parameters for a function and template
usingdeclaration and directivealiasdeclarationexterndeclarationtypedefdeclaration- Et cetera
Printing the declared variable above will still show a value, indicating it stores the data despite not having assigned yet. A defined variable does not need to specify the data type as a compiler already knows what type of data it stores. Programming languages, in general, locates assigned data (ex. variable) on the left and assignee (ex. a constant value or another variable) on the right. Otherwise will cause an error or function improperly.
Initialization
Initialization is the first assignment to a variable where it commonly occurs in the definition process.
/* VARIABLE INITIALIZATION */
int variable = 3;
Many believe a definition is equivalent to “declaration + initialization” due to the example code above, but this is a huge misunderstanding. As previously mentioned, a declaration is also considered as a definition in general. The code below is also a definition but without initializing any value.
/* VARIABLE DEFINITION; BUT WITHOUT INITIALIZATION */
int variable;
Local & Global Variable
There are three types of variable in C++ language:
-
Local variable is a variable defined within the code block, such as namespaces, functions, and classes. A local variable releases data when escapes from the code block and unavailable to use outside. It may have the same name as other variables defined outside the code block.
int main() { // Insert code here... /* LOCAL VARIABLE */ int variable; return 0; } -
Global variable is a variable that does not belong to any code blocks within the script. A global variable can be used with local variables inside other code blocks without any special syntax. Be cautious when using a global variable as it can cause an error related to variable confliction.
/* GLOBAL VARIABLE */ int variable; int main() { // Insert code here... return 0; } -
Static variable is a variation of a local variable that retains the data even after escaping from the code block. The data last left off is continued when re-entering the code block. The
statickeyword declares a static variable.int main() { // Insert code here... /* STATIC VARIABLE */ static int variable; return 0; }
Constant Variable
A constant variable is a variable that cannot change its value after initialization. The const keyword declares variable as a constant.
/* CONSTANT DEFINITION */
const int variable = 1;
Data Type Casting
Data type casting force-changes data type stored in a variable into other desired type. Casting the small size data to a compatible but larger size data type is called implicit casting. Implicit casting is a natural data type conversion automatically done by a compiler as no data loss occurs.
short A = 1; // 2 BYTES INTEGER
int B = A; // 4 BYTES INTEGER
On the other hand, explicit casting risks data loss/corruption upon converting data type. Traditional C-style casting syntax uses parenthesis () as follows:
float A = 1.9; // 4 BYTES FLOAT
int B = (int)A; // 4 BYTES INTEGER - INCOMPATIBLE: only returns its integer value.
1
However, starting from C++11 introduced four new operators for casting to complement what traditional syntax lacked. Hence, C++ recommends using these four operators when converting data type.
static_cast Operator
The static cast operator is casting for a general implicit and explicit data type conversion.
int variable = 3;
static_cast<double>(variable);
constant_cast Operator
The constant_cast operator is casting exclusively for converting data type or changing the value of the constant variable, using call by reference introduced in the C++: POINTER chapter.
const int A = 3; // OLD: A = 3
int *B = const_cast<int *>(&A);
*B = 1; // NEW: A = 1
dynamic_cast Operator
The dynamic_cast operator is casting for processing polymorphism. Refer to the C++: OBJECT-ORIENTED PROGRAMMING chapter for the detail as it is about converting the class and object.
derivedClass *A = new derivedClass;
baseClass *B = dynamic_cast<baseClass *>(A);
reinterpret_cast Operator
The reinterpret_cast operator is casting for data type conversion of the pointer introduced in the C++: POINTER chapter.
int *variable = 3
reinterpret_cast<double *>(variable)
Beware, use the reinterpret_cast operator with caution as it has a high potential for data loss compared to the other three.
Operator
An operator is the simplest form of the data processing unit that manipulates the value of operands. It is placed before, after, or between the operands.
Arithmetic Operator
The arithmetic operator mainly focuses on processing numeric data types. Following is a list of arithmetic operators used by numeric data type:
| NAME | OPERATOR | DESCRIPTION |
|---|---|---|
| Addition | + |
- |
| Subtraction | - |
- |
| Multiplication | * |
- |
| Division | / |
When both operands are integer: an integer dividend without a remainder. When at least one operand is real (float or double): a real dividend (float or double). |
| Remainder (Modulus Division) | % |
Remainder only returns an integer. |
For easier readability, you may place blank spaces between numbers and operators which does not affect its output.
Assignment Operator
The assignment operator is another operation used within numeric data types. Following is a list of assignment operators used by numeric data type:
| OPERATOR | EXAMPLE | EQUIVALENT |
|---|---|---|
+= |
x += 1 |
x = x + 1 |
-= |
x -= 1 |
x = x - 1 |
*= |
x *= 1 |
x = x * 1 |
/= |
x /= 1 |
x = x / 1 |
%= |
x %= 1 |
x = x % 1 |
Although not an assignment operator, the similar increment and decrement operator has identical meaning as follows:
| OPERATOR | EXAMPLE | DESCRIPTION |
|---|---|---|
++ prefix |
x = y++ |
x = y; y = y+1; |
++ suffix |
x = ++y |
y = y+1; x = y; |
-- prefix |
x = y-- |
x = y; y = y-1; |
-- suffix |
x = --y |
y = y-1; x = y; |
Relational Operator
The relational operator is used to compare the relation of two values, returning either true or false boolean value. Following is a list of relational operators:
| OPERATOR | DESCRIPTION |
|---|---|
< |
Lesser than |
<= |
Lesser than or equal to |
> |
Greater than |
>= |
Greater than or equal to |
== |
Equal to |
!= |
Not equal to |
Logical Operator
The logical operator consist of AND, OR, and NOT logic. Consider true and false as binary counterpart of 1 and 0.
| OPERATOR | LOGIC | DESCRIPTION |
|---|---|---|
&& |
AND | true when all arguments are true, else false. |
|| |
OR | true when at least one argument is true, else false. |
! |
NOT | Changes true to false and vice versa. |
Escape Character
Escape character \ is used to escape from a sequence of characters and execute certain operations within text-based data. In the introduction on string data type, \n is used to change to a new line.
printf("Hello\nWorld!!");
Hello
World!
| New line | Horizontal tab | Backslash | Backspace | Single quote | Double quote |
|---|---|---|---|---|---|
\n |
\t |
\\ |
\b |
\' |
\" |
CONDITIONAL AND LOOP
Conditional and iteration (or loop) statements are two of the most commonly used in programming. The “statement” in programming represents a code that executes or processes data. This chapter introduces a list of conditional and iteration statements in C++ language programming.
if Statement
Conditional if statement runs code if the condition holds. When the condition evaluates true, the indented codes are carried out but otherwise ignored.
if (condition)
{
statements;
}
// SIMPLIFIED STATEMENT
if (condition) statement;
The if statement can locate inside another if statement, called “nested if”. Use a code block {} to distinguish between if statements to avoid possible misinterpretation made by a compiler.
if (condition)
{
if (condtion)
{
statements;
}
}
else Statement
A conditional else statement cannot be used alone and must be followed by an if condition. The statement contains code that executes when evaluated false.
if (condition)
{
statements;
}
else
{
statements;
}
else if Statement
A conditional else if statement is a combination of else and if conditions; when the first condition evaluates false, the else if statement provides a new condition different from the previous one.
if (condition) {
statements;
}
else if (condition) {
statements;
}
else {
statements;
}
However, this statement is different from the chain of else-if conditional statement as that is a combination of two sets of conditions. On the other hand, else if conditional statement is a continuation of an existing evaluation instead of starting new conditioning.
Ternary Operator
A conditional statement can be simplified using the ternary operator shown below:
condition ? return_true : return_false;
The vocabulary ternary indicates the statement takes three arguments. The ternary operator should not be overused as it reduces readability but useful on variable assignment.
switch Statement
Conditional switch statement evaluates whether a variable matches a value assigned to the case keyword and executes the corresponding code if true. After execution, the break statement must locate to prevent further evaluation of the next case keyword.
If no condition matches, the statement automatically executes codes under the default keyword that is mandatory. The default keyword does not require the break statement as opposed to the case keyword.
switch (argument)
{
case value1:
statements;
break;
case value2:
statements;
break;
default:
statements;
}
Multiple case keywords may share the same code as follows:
switch (argument)
{
case value1:
default:
statements;
break;
case value2:
case value3:
statements;
break;
case value4:
statements;
break;
}
break Statement
The break statement is to end a loop prematurely. When encountered in the loop, the break statement escapes from the current loop but does not escape from the nesting loop.
continue Statement
The continue statement skips the rest of the code below in the loop and jumps back to the conditioning part. It maintains the iteration rather than escaping from it like the break statement.
while Loop
A while loop statement repeatedly executes statements inside (aka. iterate) as long as the condition holds. The loop ends once the condition evaluates false.
while (condition)
{
statements;
}
// SIMPLIFIED STATEMENT
while (condition) statement;
do-while Statement
The do-while loop statement is similar to the while loop statement, but the former executes code first then evaluates, and the latter is vice versa.
do
{
statements
} while (condition);
for Loop
The for loop statement repeatedly executes statements inside (aka. iterate) as long as the condition holds. Its local variable changes as specified on each iteration, which commonly uses integer increment.
for (variable; condition; increment) {
statements;
}
// SIMPLIFIED STATEMENT
for (variable; condition; increment) statement;
Range-based for Loop
C++11 introduced a new variation of the for loop that iterates execution while in range. The range is generally given by the Sequence Container, which is the data that can sequence its elements individually.
for (variable : range) {
statements;
}
// SIMPLIFIED STATEMENT
for (variable : range) statement;
Refer to the next chapter, C++: CONTAINER, to know more about the container data in C++ language.
CONTAINER
C++ has containers that can store a collection of data, and the one that sequences data in order is called a sequence container; an array and vector are the most renowned. This chapter focuses on a sequence container commonly used in C++ language.
Array
An array is a container for data of the same data type in sequence. Declare an array by designating its size of how much data it can store using a bracket [].
/* ARRAY DEFINITION */
int arr[size];
A variable is not allowed when defining the size of an array (except a constant). The size of an array is static, meaning it cannot change after the definition.
Assign values in order within a pair of curly bracket {} to initialize an array:
/* INITIALIZATION 1 */
int arr[size] = {value1, value2, ... };
/* INITIALIZATION 2: SIZE IS SET TO THE NUMBER OF ELEMENTS */
int arr[] = {value1, value2, ... };
Upon initialization, the number of initialized values should not exceed its declared size, though it may be smaller, which fills leftover with 0 or NULL value.
Calling an array itself does not show the whole elements inside; instead, it returns the memory address the array data is assigned to (aka. pointer) and is equivalent to the memory address of its first element.
int arr[3] = {value1, value2, value3};
arr; // >> OUTPUT: 0139F854
&arr[0]; // >> OUTPUT: 0139F854
&arr[1]; // >> OUTPUT: 0139F858 ( = 0139F854 + 4 BYTES from integer data type)
This concept is explained later in the next chapter C++: POINTER in detail.
Because of this characteristic, an array cannot assign multiple values at once besides initialization. Access each element using a bracket [] with an index starting from 0.
int arr[3];
/* ASSIGNMENT TO INDIVIDUAL ELEMENT */
arr[0] = value1;
arr[1] = value2;
arr[2] = value3;
Length of Array
When using the sizeof() on the array, it returns the total number of bytes allocated. Since allocated memory size is relevant to the data type, use the following expression to acquire the number of elements:
int arr[3];
sizeof(arr)/sizeof(int); // >> OUTPUT: 3 ( = LENGTH OF ARRAY)
In other words, the length of an array is found by dividing its allocated bytes by its data type size.
Multi-dimensional Array
A multi-dimensional array stores another array as its element. These arrays used as elements must share the same length and data type. A multi-dimensional array can initialize without defining a size but limited to its first boundary only.
/* INITIALIZATION 1 */
int arr[size1][size2] = { {value11, value12, ... }, {value21, value22, ...}, ... };
/* INITIALIZATION 2 */
int arr[][size2] = { {value11, value12, ... }, {value21, value22, ...}, ... };
Array Class
*Reference: [cplusplus.com
class](http://www.cplusplus.com/reference/array/)*
The array class is one of the C++ Standard Library that can also provide C-style array as introduced above, but with better accessibility and handling such as sequencing. Include the <array> header to use an array class.
#include <array>
// ARRAY DECLARATION: C++ STANDARD LIBRARY
std::array<int, 3> arr;
Since there is no performance difference between the array declared by both C-style and C++ Standard Library, developers are free to choose whatever they are confident. However, the ranged-based for loop statement has to use an array class.
Vector Class
*Reference: [cplusplus.com
class](http://www.cplusplus.com/reference/vector/)*
The vector class is a sequence container like an array but with a feature that can change its size dynamically; vector stores the data in a separate memory space that must allocate manually by developers. Thankfully, memory management is all done by the system, hence no need to worry about allocation.
#include <vector>
// DECLARATION
std::vector<int> vec;
The benefit of using the vector class is the container size can change flexibly (and dynamically) due to its memory allocation property. However, vectors are slower than arrays when it comes to performance.
FUNCTION
C/C++ language is executed based on a single function called the main() function. Understanding the concept of functions is crucial in C/C++ languages and can increase efficiency by creating custom functions, called functional programming. This chapter will be introducing the guide on how to create and use functions in C++ language for functional programming.
Function
A function is a reusable independent block of code that can process the data and present newly processed data once it’s called, allowing dynamic program scripting. A function is distinguished by parenthesis after its name; function().
int variable = {0, 3, 5, 9};
printf(sizeof(variable));
// USING "printf()" AND "sizeof()" FUNCTION THAT RETURNS THE LENGTH OF A LIST OBJECT.
The function requires two components for a definition:
- Code block
{}: a space for codes that execute when called. - Data type: a type of data to return when exiting the function.
/* FUNCTION DEFINITION */
int function()
{
return 1 + 2;
}
/* CALING A FUNCTION */
function(); // >> OUTPUT: 3
Because C/C++ programming executes from top to bottom sequentially, a function won’t be executable unless it is defined firsthand. However, locating every function definition on top of the script will make it difficult to manage for a larger project.
A function prototype, aka a forward declaration, let the compiler know the existence of a function before the definition. As mentioned in the C: BASIC § Variable section, a forward declaration is not a definition. The prototype is not essential but mostly locates on top of the script, replacing a code block {} to semicolon ;.
/* FUNCTION PROTOTYPE (AKA. FORWARD DECLARATION) */
int function();
/* CALLING A FUNCTION */
function(); // >> 출력: 3
/* FUNCTION DEFINITION */
int function()
{
return 1 + 2;
}
Defining a function inside another function (aka nested function) is invalid in C/C++ language.
return Statement
The return statement is a function-exclusive statement that returns the value processed by a function. Once encountering a return statement, the function ends immediately despite having remaining codes.
If the function is a void data type, the return; statement alone without any data will exit the function.
Parameter & Argument
Following is a difference between parameter and argument mentioned when discussing function:
-
- Argument
- An argument is a value or object passed to a function parameter.
-
- Parameter
- A parameter is a local variable assigned with an argument. Meaning, parameters are only available inside the function. Parameters is declared inside a parenthesis
().
Although parameters and arguments are a different existence, two terms are used interchangeably as both stores the same data.
| OPERATOR | SYNTAX | DESCRIPTION |
|---|---|---|
= |
arg=value |
A parameter that has default value when no argument is passed. Must locate after normal parameter. |
Examples below show how parameter and argument work in function:
/* FUNCTION PROTOTYPE */
int function(int arg1, float arg2);
/* CALLING A FUNCTION */
function(1); // >> OUTPUT: 3.0
function(1, 3.0); // >> OUTPUT: 4.0 (extract an integer from 1 + 3.14)
/* FUNCTION DEFINITION */
int function(int arg1, float arg2 = 2.0)
{
return arg1 + arg2;
}
Passing a container such as an array cannot be done using the syntax above and requires a different method. There are two syntaxes available: defining a parameter as an array or as a memory address (pointer).
void function(int arg[]);
int arr[3] = {value1, value2, value3};
function(arr); // PASSING ARRAY TO FUNCTION ARGUMENT
// ACCEPT ARGUMENT AS AN ARRAY
void function(int arg[])
{
statements;
return;
}
void function(int *arg);
int arr[3] = {value1, value2, value3};
function(arr); // PASSING ARRAY TO FUNCTION ARGUMENT
// ACCEPT ARGUMENT AS A POINTER
void function(int *arg) {
statements;
return;
}
The latter method is possible due to the characteristic where calling an array itself returns the memory address of the first element. Incrementing the pointer will shift to the next element since the memory is allocated in sequence.
Function Overloading
The function overloading is the concept where functions with the same name behaving differently based on the number of arguments and their data type. While these functions may have a different definition, the returned data type must be the same.
float function(int arg1, float arg2); // PROTOTYPE OF OVERLOADED FUNCTION 1
float function(float arg1, float arg2); // PROTOTYPE OF OVERLOADED FUNCTION 2
function(1, 3.0); // >> OUTPUT: 4.0
function(1.0, 3.0); // >> OUTPUT: -2.0
// DEFINITION OF OVERLOADED FUNCTION 1
float function(int arg1, float arg2) {
return arg1 + arg2;
}
// DEFINITION OF OVERLOADED FUNCTION 2
float function(float arg1, float arg2) {
return arg1 - arg2;
}
Entry Point
An entry point is the startup function where program execution begins; they do not need forward declaration nor needs to be called. There can be only one entry point in the project; having more than one entry point or none will result in an error.
main() Function
As the only entry point available in traditional C++ console application, a project must have one and only main() function within the project. Creating multiple main() functions or not having any main() function will cause error on running the program.
int main(int argc, char **argv) {
return 0;
}
While this article didn’t include the main() function on the example codes, every code besides global variables and function definitions must be inside the entry point.
According to the C++ language standard, the main() function must return an integer; the EXIT_SUCCESS (equivalent to an integer 0) or the EXIT_FAILURE.
The compiler implicitly fills in the return 0; statement at the end of the entry point if not presented in the function.
The main() function has the following parameters:
argc: the number of arguments (abbrev. of argument count)argv: the list of argument values (abbrev. of argument vector); alternatively can be declared aschar *argv[]
These arguments are apparent when running the program on a terminal:
./app.exe option1 option2
| ARGUMENTS | VALUE |
|---|---|
argv[0] |
./app.exe |
argv[1] |
option1 |
argv[2] |
option2 |
The argc parameter always has a value greater than zero since the first element of the argv is the name of the program.
Meanwhile, Windows OS has an exclusive entry point called the wmain() function that supports various languages by using wide-character arguments encoded in UTF-8 Unicode (size varying from 1~4 bytes).
/* C LANGUAGE ENTRY POINT SUPPORTING WIDE-CHARACTER: wmain() */
int wmain(int argc, wchar_t **argv) {
return 0;
}
The wmain() function was introduced because C language originated from UNIX operating system interface based on ASCII encoding. Using the main() function on Windows OS won’t recognize certain characters, such as Greek, Cyrillic, due to encoding compatibility.
WinMain() Function
Reference: https://docs.microsoft.com/en-us/windows/win32/api/winbase/nf-winbase-winmain
The WinMain() function is an entry point for the application framework, such as Win32 and MFC Library.
int WinMain(HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPSTR lpCmdLine,
int nCmdShow)
{
/* ENTERS MESSAGE LOOP:
WILL EXIT BY "return MSG.wParam;" */
// QUIT WinMain() if failed to enter message loop.
return 0;
}
The core functionality of the WinMain() function is entering a message retrieval-and-dispatch loop called Message Loop. For more information on how framework application works, refer to the LIBRARY_MFC.md article.
Receiving the WM_QUIT message will terminate the Loop and exit the application by returning its wParam parameter. Failed to enter the Loop will continue to return 0; statement, exiting the application program immediately.
DllMain() Function
Reference: https://docs.microsoft.com/en-us/windows/win32/dlls/dllmain
The DllMain() function is an entry point for the dynamic link library.
int DllMain(_In_ HINSTANCE hinstDLL,
_In_ DWORD fdwReason,
_In_ LPVOID lpvReserved)
{
return 0;
}
Recursion Function
A recursive function is a function that calls itself (recursion). Factorial in mathematic is the best example of recursive function implementation.
/* EXAMPLE: FACTORIAL "!" */
int factorial(int num) {
// BASE CASE: a case when to escape from the recursion.
if (num == 1)
return (1);
else
return (num * factorial(num-1));
}
Recursion can occur indirectly by multiple functions calling one to another, then back to the beginning.
Callback Function
The callback function, aka. “call-after” function, is a function passed as an argument to other functions. The calling function runs the callback function by calling the parameter, thus named as the “callback” function.
The following is the example for the callback function, which is explained in the C++: POINTER § Function Pointer section.
/* CALLING FUNCTION */
int calling(float (*function)(int, float), int arg)
{
// CALLING CALLBACK FUNCTION
float var = function(arg, 3.0);
return var;
}
/* CALLBACK FUNCTION */
float function(int arg1, float arg2) {
return arg1 + arg2;
}
// THEREFORE...
FUNC(&function, 1, 3.0); // >> OUTPUT: 4.0
POINTER
This article has mentioned a new “pointer” data type since the C++: CONTAINER chapter. The pointer is one of the crucial concepts in C language, allowing more complex programming. This chapter describes what the pointer is in C language and revisits the array and function.
Pointer
The pointer is a data type that stores the allocated memory address of a variable instead of its value. A 32-bit and 64-bit operating system have a pointer that is 8 and 16 bytes long. A variable can store a pointer as well; while the data type is required when defining, an asterisk * must locate between the data type and identifier.
/* POINTER DECLARATION */
int* ptr;
printf("%p", ptr); // WARNING C4700: UNINTIALIZED LOCAL VARIABLE 'ptr' USED
Memory address can be called from a non-pointer variable as well using the ampersand operator &.
/* INTEGER VARIABLE DEFINITION */
int variable = 365;
printf("%p", &variable);
1014eb010
Since the hexadecimal memory address should not be written by hand, the only way to assign the pointer is by the existing memory address. Beware, the data type must match on assignment to the variable.
While a memory address is expressed in eight bytes (32-bit architecture) or sixteen bytes (64-bit architecture) of hexadecimal, a single memory is limited to hold data of one byte. The char data type is enough with a single byte, but the int integer or float floating-point number requires four bytes of memory space. However, since the pointer only returns the first memory address of overall memory space, the compiler won’t know whether the data is complete when the data type is not specified.
/* VARIABLE INITIALIZATION */
int variable = 365;
// POINTER VARIABLE OF THE SAME TYPE
int *ptr1 = &variable;
printf("%p\n", ptr1); // >> OUTPUT: 0x1014eb010 (ADDRESS)
printf("%d\n", *ptr1); // >> OUTPUT: 365 (VALUE)
// POINTER VARIABLE OF THE DIFFERENT TYPE
char *ptr2 = &variable;
printf("%p\n", ptr2); // >> OUTPUT: 0x1014eb010 (ADDRESS)
printf("%d\n", *ptr2); // >> OUTPUT: 109 (VALUE)
As seen above, it is possible to return the value assigned to the pointer by placing the dereference operator *. While a pointer declaration also used an asterisk, they are different existence but only sharing the same symbol.
| OPERATOR | VARIABLE | RETURN |
|---|---|---|
Address-on Operator & |
Non-pointer | Memory address |
Contents-of Operator * |
Pointer | Value |
If the variable value changes, the value dereferenced from the pointer also changes since it shares the same memory address, also known as “call by reference”.
Null Pointer
A null pointer is a pointer that points to nothing. Since C++ language may cause an error such as memory access violation because of the pointer, assign the nullptr keyword for safe usage.
int* ptr = nullptr; // >> OUTPUT: 00000000
Void Pointer
A void pointer is a pointer with no specific data type (thus, void). It has the advantage of being able to point to any data type with help from data type conversion, such as the reinterpret_cast operator.
/* VOID POINTER DECLARATION */
void* ptr;
int variable = 365;
ptr = &variable;
std::cout << *(reinterpret_cast<int*>(ptr));
365
Function Pointer
The function pointer is a void pointer that points to a function. Similar to a pointer to an array representing the first element memory address, a function pointer points to the first line of the function code. Initialize the function pointer using the following syntax:
/* FUNCTION DEFINITION */
int function(int arg1, float arg2) {
statements;
return 0;
}
int main() {
// Insert codes here...
/* FUNCTION POINTER INITIALIZATION */
int (*ptr)(int, float) = function;
ptr(1, 3.14);
return 0;
}
The function pointer should match the data type and parameters of the function when initializing. Failed to do so will result in a compilation error. While calling with a parenthesis like function() returns data from the return statement, without a parenthesis like function returns a memory address instead.
Reference
The reference is a variable that processes data of another existing variable. By having two variables share a single memory, it is considered as aliasing a variable.
/* THE "ref" VARIABLE REFERENCES THE "variable" VARIABLE. */
int variable;
int &ref = variable;
ref = 3; // >> RESULT: variable = ref = 3
The reference is equivalent to a constant pointer to the variable, with constant pointer declaration * applied by the compiler automatically.
/* REFERENCE USING A CONSTANT POINTER */
int variable;
const int* ref = &variable;
*ref = 3; // >> RESULT: variable = *ref = 3
Initialization is mandatory since the reference uses a constant pointer, and the variable that referenced once cannot re-reference another variable. The call by reference in programming is referring to this reference.
DYNAMIC MEMORY
Memory management in C++ language is a significant task. Dynamic memory allocation provides higher memory efficiency but requires a clear understanding of the pointer as it is deeply involved. Here, the memory indicates random access memory (RAM), the primary memory in a computer.
Stack Structure
The stack is a linear LIFO (Last-In-First-Out) data structure; the first entered data is last to be freed from the memory structure. It is the main memory structure used by the compiler that automatically allocates and deallocates data upon declaration and destruction of data, such as variables and functions. The drawback of stack-based memory is poor memory management.
The characteristic of the stack memory is apparent when dealing with a local variable, which is unable to use outside the code block.
Queue Structure
The queue is a linear FIFO (First-In-First-Out) data structure. The data that entered first is released first from the memory structure. The best example of a queue-based memory structure is serial communication, such as USB and ethernet.
Dynamic Allocation
Despite its fast memory allocation, the stack memory is difficult for memory management due to its sequential structure. Additionally, the purpose of a stack-based memory used by the compiler is not for storing data but rather to “process data,” hence have limited capacity on RAM. However, the compiler can also access the heap memory region located in the same RAM. Although slower than the stack, it has the benefit of easier management and lasting data until the end of the program.
The heap memory region is irrelevant to the heap data structure and is purely a term that indicates part of the RAM.
Allocating memory in the heap region is called dynamic allocation in C++ language. Developers need to use a specific function for dynamic allocation, where the allocation address is randomly designated. Since this process is done manually by the developers, every dynamically allocated data must be freed by the developers as well. Failed to do so will cause the program to crash from memory shortage or function improperly.
Dynamic allocation and deallocation to heap memory use the new and delete keyword:
/* DYNAMIC ALLOCATION */
int* ptr1 = new int;
int* ptr2 = new int();
/* DYNAMIC DEALLOCATION */
delete ptr1;
delete ptr2;
The former and latter dynamic allocation is called default-initialization and value-initialization.
- Default-initialization: initializes data with undetermined or pre-determined (exclusive to classes) value.
- Value-initialization: initializes data to the value inside parentheses.
Dynamic allocation and deallocation of array data are similar to the method above:
/* DYNAMIC ALLOCATION: ARRAY */
int* ptr = new int[];
/* DYNAMIC DEALLOCATION: ARRAY */
delete[] ptr;
Deallocating is an extremely crucial task, as failure to do so can result in memory leaks or dangling pointer.
Memory Leak
A memory leak is caused by mismanagement of heap memory when dynamically allocated data is not released (deallocated) and accumulated that no more heap memory space is available. A shortage of memory will eventually lead to system failure. Prevent memory leak by deallocating data on heap memory using the delete keyword.
/* DYNAMIC DEALLOCATION */
delete ptr;
Dangling Pointer
By deallocating data on heap memory prevents memory leak from happening. While the data addressed by the pointer is gone, it still holds the address that now points to the unknown, called dangling pointer that may cause the SEGFAULT, a segmentation fault error. Assign the nullptr so the pointer would point at least to nothing rather than point aimlessly after deleting the heap memory data.
/* PROPER DEALLOCATION: DELETE DATA ON ADDRESS -> NULLIFY ADDRESS */
delete ptr;
ptr = nullptr;
STRING
Conventional C language does not have a string data type that can hold the string data specifically; it uses an array of a character with the null terminator \0 at the end. However, C++ has a standard library for the string data type.
String
The C-Style string is an array of characters with a null terminator that is defined as follows:
/* C-STYLE STRING */
char arr[] = "Hello";
char* ptr = "World!";
String Data Type
The C++ string data type from the string header is part of the iostream header, under the std standard namespace. The string data is generally called string object. C++ recommends using the C++ string data type than the C-style string.
/* C++ STRING */
std::string str = "Hello World!";
String Array
An array cannot have elements of different sizes; the only possible way to store string data that varies size by the length of characters is by having a pointer to the string as its element instead of the string value.
std::string arr[] = {"Hello", "World!"};
OBJECT AND CLASS
The current document has explained and dealt with procedural and functional programming. The third scripting method, object-oriented programming (abbrev. OOP), focuses on the usage of classes and objects instead of functions.
Object
Previous chapters introduced a variable and function, which is for storing and processing data, respectively. Object (aka. instance) is a block of data that encapsulates these variables and functions into a single identity.
The programming based around the use of custom objects is called object-oriented programming.
std::string variable = "Hello World!";
std::cout << variable.length();
// Using the "length()" method that returns the number of characters excluding a null terminator from the "variable" string object.
12
Encapsulation
Encapsulation is the core concept in an object with the following characteristics:
- Combines variables and functions into a single data.
- Restrict direct access to these variables and functions to prevent accidental modification from external code.
State & Behavior
State and behavior refer to a variable and function encapsulated to an object in C++. The encapsulated variable and function are respectively called member variable and member function, accessed using the member access operator ..
| MEMBER | COMPONENT | SYNTAX |
|---|---|---|
| State | Member variable (aka. member field) | instance.field |
| Behavior | Member function (aka. method) | instnace.method() |
Class
A class creates objects (aka. instance) and is defined using the class keyword. Definitions of an object’s fields and methods are also inside a class definition. The following example is a simple user-defined class with attributes and methods:
/* CREATING CLASS */
class CLASS{
public:
/* MEMBER VARIABLE (AKA. MEMBER FIELD) */
int field1 = 1;
float field2 = 3.0;
/* METHOD (AKA. MEMBER FUNCTION) */
float method(int arg) {
return field1 + field2 - arg;
}
};
// INSTANTIATION
CLASS instance;
// THEREFORE...
instance.field1; // >> OUTPUT: 1
instance.field2; // >> OUTPUT: 3.0
instance.method(2); // >> OUTPUT: 2.0 (= 1 + 3.0 - 2)
The class requires a semicolon ; at the end of the code block. Creating an instance from the class is called instantiation.
Constructor
A constructor is a method that automatically executes whenever instantiation has occurred, defining the number of arguments and its data type to the instance. The name of a constructor must be the same as the class name but without specifying the returned data type because it has a fixed data type of void.
One of the common usages of a constructor is the initialization of member fields upon instantiation. There are two different initialization approaches: (1) direct initialization and (2) list initialization.
/* CREATING CLASS */
class CLASS {
public:
/* CONSTRUCTOR */
CLASS(int arg1, float arg2)
{
field1 = arg1; field2 = arg2; // DIRECT INITIALIZATION
statements;
}
int field1;
float field2;
float method(int arg) {
return field1 + field2 - arg;
}
};
// INSTANTIATION
CLASS instance(1, 3.0);
/* CREATING CLASS */
class CLASS {
public:
/* CONSTRUCTOR */
CLASS(int arg1, float arg2)
: field1(arg1), field2(arg2) // LIST INITIALIZATION
{
statements;
}
int field1;
float field2;
float method(int arg) {
return field1 + field2 - arg;
}
};
// INSTANTIATION
CLASS instance(1, 3.0);
Using the member initializer list can initialize constant member fields impossible when initialized directly.
A constructor is an optional method and passes arguments through parenthesis () upon initialization. However, initialize without parenthesis when there is no argument for the instance. Multiple constructors are allowed per class as long as the rule of function overloading is observed.
Destructor
A destructor is a method that automatically executes whenever the instance is destroyed and released from the memory. The name of a destructor must be the same as the class name with a tilde ~ prefix but without specifying the returned data type because it has a fixed data type of void.
/* CREATING CLASS */
class CLASS {
public:
/* DESTRUCTOR */
~CLASS() {
statements;
}
int field1 = 1;
float field2 = 3.0;
float method(int arg) {
return field1 + field2 - arg;
}
};
A destructor is an optional method, but only one is allowed per class since the absence of parameters means no support for function overloading.
Constant Object
A constant object is an object that cannot change member value after instantiation. Because of this property, the initialization of the instance is only possible by the list initialization.
// INSTANTIATION: CONSTANT OBJECTs
const CLASS instance;
A constant object can only access constant member variables and constant member function. Beware, the constant method is a method declarable only within the class and must place the const keyword after the parameter declaration.
/* CREATING CLASS */
class CLASS {
public:
int field1 = 1;
float field2 = 3.0;
float method1(int arg) {
return field1 + field2 - arg;
}
// DECLARATION: CONSTANT METHOD
void method2(int arg) const {
statements;
}
};
Access Specifier
Access specifier defines accessibility to class members from outside the class. There are three access specifiers in C++: public, private, and protected.
| KEYWORD | DESCRIPTION |
|---|---|
public |
Members are accessible from outside the class. |
private |
Members are accessible only within the class. |
protected |
Members are accessible from the derived class but still restricted from outside the class (refer to the inheritance section). |
Friend Function
A friend function is a function that can access private members within the class despite defined outside the class. To declare a friend function, place the prototype inside the class definition with the friend keyword.
class CLASS {
private:
int field1 = 1;
float field2 = 3.0;
float method1(int arg) {
return field1 + field2 - arg;
}
/* FRIEND FUNCTION PROTOTYPE */
friend void function(CLASS &instance);
};
/* FUNCTION DEFINITION */
void function(CLASS &instance) {
instance.field1 = 2;
}
// INSTANTIATION
CLASS instance;
function(instance);
// THEREFORE...
instance.field1; // >> OUTPUT: 2
instance.field2; // >> OUTPUT: 3.0
instance.method(2); // >> OUTPUT: 3.0 (= 2 + 3.0 - 2)
A friend function is not a member, which means it does not need an object to use. The reason the friend function can access the private members is because of the encapsulation of the prototype.
Pointer to Class
Objects are assignable to a pointer instead of a variable when instantiated. In the case of a pointer, access members via the arrow member selection operator ->.
class CLASS {
public:
CLASS(int arg1, float arg2)
: field1(arg1), field2(arg2) { }
~CLASS() { }
int field1;
float field2;
float method1(int arg) {
return field1 + field2 - arg;
}
};
// INSTANTIATION (POINTER)
CLASS instance(1, 3.0);
CLASS *ptr = &instance;
// THEREFORE...
instance->field1; // >> OUTPUT: 1
instance->field2; // >> OUTPUT: 3.0
instance->method(2); // >> OUTPUT: 2.0 (= 1 + 3.0 - 2)
Dynamic Object
A dynamic object is an instantiated stored in the heap region memory instead of the stack; this can prevent data corruption caused by the deallocation from the stack memory. It is commonly used on the framework libraries such as MFC.
/* DYNAMIC OBJECT */
CLASS *instance = new CLASS(1, 3.0);
Identity
Identity is the third property of an object which distinguishes itself from others, commonly by using the memory address to itself. Every instance has an implicit this pointer that points to the address of itself and can be used to access its members.
class CLASS {
public:
CLASS(int arg1, float arg2)
: field1(arg1), field2(arg2) { }
~CLASS() { }
int field1;
float field2;
float method1(int arg) {
// USAGE OF "this" POINTER
return (this->field1) + (this->field2) - arg;
}
};
For those who are familiar with Python, consider this pointer as a C++ version of the self keyword.
Inheritance
Inheritance is an act of providing both member fields and methods of a base class to a derived class. When the base class and derived class share the same name of member fields or methods, it uses members from the derived class.
/* CREATING BASE CLASS */
class BASECLASS {
public:
BASECLASS() { std::cout << "BASE CLASS: Constructor" << std::endl; }
~BASECLASS() { std::cout << "BASE CLASS: Destructor" << std::endl; }
int field1 = 1;
float field2 = 3.0;
};
/* CREATING DERIVED CLASS */
class DERIVEDCLASS
: public BASECLASS {
public:
DERIVEDCLASS() { std::cout << "DERIVED CLASS: Constructor\n" << std::endl; }
~DERIVEDCLASS() { std::cout << "\nDERIVED CLASS: Destructor" << std::endl; }
float field2 = 7.0;
char field3 = 'A';
};
// INSTANTIATION
DERIVEDCLASS instance;
std::cout << instance.field1 << ", " << instance.field2 << ", " << instance.field3 << std::endl;
"BASE CLASS: Constructor"
"DERIVED CLASS: Constructor"
1, 7.0, A
"DERIVED CLASS: Destructor"
"BASE CLASS: Destructor"
Type of Inheritance
There are three different types of class inheritance on OOP in C++ language:
| INHERITANCE | DESCRIPTION |
|---|---|
public |
Private members of the base class are not inherited nor accessible. Public and protected members of the base class become public and protected members of the derived class. |
private |
Private members of the base class are not inherited nor accessible. Public and protected members of the base class become private members of the derived class. |
protected |
Private members of the base class are not inherited nor accessible. Public and protected members of the base class become protected members of the derived class. |
/* INHERITING BASECLASS1 (PUBLIC) & BASECLASS2 (PROTECTED) */
class DERIVEDCLASS
: public BASECLASS1, protected BASECLASS2
{
statements;
};
Polymorphism
Polymorphism means “having many forms,” which in C++ programming means having different functionality based on the situation and usage. Polymorphism is one of the core features in OOP categorized into two types:
-
- Compile-time Polymorphism
- polymorphism achieved on compilation (aka. static polymorphism).
-
- Run-time Polymorphism
- polymorphism achieved on run-time (aka. dynamic polymorphism).
One of the compile-time polymorphism has already been introduced; function overloading which functions differently according to passed arguments.
Operator Overloading
Operator overloading is another compile-time polymorphism that customizes operator to function differently on specific classes. Just like function overloading, a single operator can have multiple implementations as long as the argument’s uniqueness is guaranteed. Overloaded operators are class-exclusive and won’t be applied elsewhere.
Use the operator keyword to specify the operator to customize. The syntax for defining operator functionality is identical to the method definition.
/* CREATING CLASS */
class CLASS {
public:
// OPERATOR OVERLOADING 1
void operator [] (int arg1, int arg2) {
statements;
}
// OPERATOR OVERLOADING 2
CLASS operator + (const CLASS &arg) {
statements;
return arg;
}
};
On the second overloading, the method parameter arg references the CLASS type argument, and the const keyword makes the parameter read-only. Eventually, the parameter can access the CLASS type object directly from its memory space but cannot modify it.
Function Overriding
Function overriding is a run-time polymorphism where the derived class redefines members inherited from the base class. The difference between overloading and overriding is the formal selects functionality while the latter redefines functionality.
A virtual function is a function specifically for function overriding, declared by the virtual keyword from the base class alone.
/* CREATING BASE CLASS */
class BASECLASS {
public:
// VIRTUAL FUNCTION
virtual void polymorph() {
statements1;
}
};
/* CREATING DERIVED CLASS */
class DERIVEDCLASS1
: public BASECLASS {
public:
// OVERRIDDEN FUNCTION
void polymorph() {
statements2;
}
};
Beware, the base class member substituted by the derived class in the C++: OBJECT AND CLASS § Inheritance example code is not a function overriding. The member definition of the base class is still intact and did not get redefined.
A virtual function can have its definition implemented in the base class for either using behavior (1) directly from a base class or (2) from a derived class in case no function override has occurred. However, a virtual function without any definition implemented is called pure virtual function.
/* PURE VIRTUAL FUNCTION */
virtual void polymorph() = 0;
Because a pure virtual function has no definition in the base class, it must be overridden when inherited to a derived class. Failed to do so will cause a compilation error.
A base class that has at least one pure virtual function is called the abstract class. Due to the property pure virtual function has, an abstract class cannot create instances directly but is used only to create a derived class.
Class in Files
For efficient management of the project, creating a class as files is highly recommended. On Visual Studio, create a class file by right-clicking either Source Files or Header Files filter and select Add » Class….
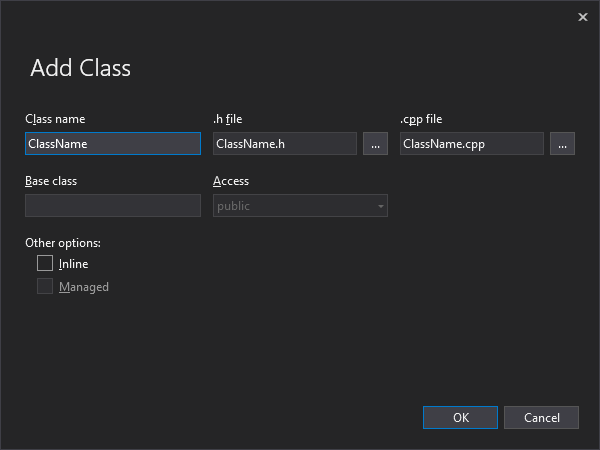
Class name typed on “Class Name:” automatically fills “.h file:” and “.cpp file:” with the same name. Click the OK button to create a header and source file in the project.
The header and source file respectively go to the Header Files and Source File filter. Despite having separated into two different files, the class can be imported to the C++ script by the #include directive.
#include "ClassName.h"
int main() {
// CALLING CLASS FROM "ClassName" CLASS FILES.
ClassName instance(1, 3.0);
return 0;
}
The header file for the class is generally created with the C-compatible .h extension, while the .hpp extension is C++ exclusive. Since C language does not support the OOP, the C++ class may have either header extension.
Class Header File
The class header file .h contains declarations of the class member fields and methods. The purpose of the header file is to declare the existence of the data to another script.
/* HEADER "ClassName.h" */
class ClassName {
public:
ClassName(int arg1, float arg2);
~CLASS() { }
int field1;
float field2;
float method(int arg3);
};
Class Source File
The source file .cpp contains the definition and initialization of the member fields and methods. While the header file declares the existence of data, their state and behavior are all defined in the source file. Link the source code with the header by using the #include directive.
/* SOURCE "ClassName.cpp" */
#include "ClassName.h"
ClassName::ClassName(int arg1, float arg2)
: field1(arg1), field2(arg2)
{
statements;
}
ClassName::~ClassName()
{
statements;
}
float ClassName::method(int arg3)
{
return field1 + field2 - arg3;
}
USER-DEFINED DATA TYPE
Commonly used data types such as int, float, char, and more are already defined and are called through the iostream header file. This chapter introduces defining a new user-defined data type that is similar to these data types but can store multiple data in a single variable.
Structure
The structure is a user-defined data type that integrates multiple member fields as a single structure tag regardless of their data type. Use the struct keyword to define a structure.
/* STRUCTURE DEFINITION: 5-BYTE SIZE */
struct STRUCTURE {
// MEMBER FIELD DEFINITION
int field1; // DATA SIZE: 4 BYTES
char field2; // DATA SIZE: 1 BYTE
};
/* STRUCTURE VARIABLE DEFINITION & INITIALIZATION */
STRUCTURE variable = {3, 'A'};
/* STRUCTURE DEFINITION & VARIABLE DEFINITION */
struct STRUCTURE {
int field1;
char field2;
} varialbe;
/* STRUCTURE VARIABLE INITIALIZATION*/
variable = {3, 'A'};
/* STRUCTURE DEFINITION & VARIABLE DEFINITION AND INITIALIZATION */
struct STRUCTURE {
int field1;
char field2;
} variable = {3, 'A'};
After defining a structure, use the member access operator . to access the member field.
variable.field1; // >> OUTPUT: 3
variable.field2; // >> OUTPUT: A
Some C++ projects may have C-style structure variable assignments such as struct STRUCTURE variable; but it is a deprecated syntax since C++11. Compared to the original C language, C++ syntax has become more simplified.
Anonymous Structure
The syntax for the structure in the previous section is reusable and can create more than one structure variable of the same type. However, to create a user-defined data type for a single-use, define the anonymous structure using the syntax below:
/* SINGLE-USE STRUCTURE VARIABLE DEFINITION & INITIALIZATION */
struct {
int field1;
char field2;
} variable = {3, 'A'};
Union
The union is a user-defined data type that integrates multiple variables as members of a single structure tag regardless of their data type but shares a memory space. In other words, value changes in one of the members also change the value assigned in the other members. Use the union keyword to define a union.
/* UNION DEFINITION: 4-BYTE SIZE */
union UNION {
// MEMBER FIELD DEFINITION
int field1; // DATA SIZE: 4 BYTES
char field2; // DATA SIZE: 1 BYTE
};
/* UNION VARIABLE DEFINITION & INITIALIZATION */
UNION variable = {365};
/* UNION DEFINITION & VARIABLE DEFINITION */
union UNION {
int field1;
char field2;
} variable;
/* UNION VARIABLE INITIALIZATION*/
variable = {365};
/* STRUCTURE DEFINITION & VARIABLE DEFINITION AND INITIALIZATION */
union UNION {
int field1;
char field2;
} variable = {365};
The byte size of the union is equal to the member variable with the largest byte size; this allows the user-defined data type to use a single memory allocation while still have enough space to store other data types. Although the union data type may have more than one member, only one member needs initialization as they all shares the same memory space.
After defining a union, use the member access operator . to access the member field.
variable.field1; // >> OUTPUT: 365 (0x0000016d)
variable.field2; // >> OUTPUT: 109 (0x0000006d)
The member field field1 and field2 are integer and character data that each store 4-byte and 1-byte. Hence, each member has 0x0000016D and 0x6D equivalent to decimal number 365 and 109.
Anonymous Union
The syntax for the union in the previous section is reusable and can create more than one union variable of the same type. However, to create a data structure for a single-use, define the anonymous union using the syntax below:
/* DEFINING & INITIALIZING A SINGLE-USE UNION VARIABLE */
union {
int field1;
char field2;
} variable = {365};
Enumeration
The enumeration is a user-defined data type numbering enumerating items, called enumerators. Enumerators are assigned with an integer that starts from zero and increments by one by default.
/* ENUMERATION DEFINITION */
enum ENUMERATION {
enumerator1, // ENUMERATOR = 0
enumerator2, // ENUMERATOR = 1
enumerator3, // ENUMERATOR = 2
enumerator4 // ENUMERATOR = 3
};
/* ENUMERATION VARIABLE DEFINITION AND INITIALIZATION */
ENUMERATION variable = enumerator1;
/* ENUMERATION DELCARATION & VARIABLE DECLARATION */
enum ENUMERATION {
enumerator1, // ENUMERATOR = 0
enumerator2, // ENUMERATOR = 1
enumerator3, // ENUMERATOR = 2
enumerator4 // ENUMERATOR = 3
} variable;
/* ENUMERATION VARIABLE ASSIGNMENT */
variable = enumerator1;
/* ENUMERATION DEFINITION & VARIABLE DEFINITION AND INITIALIZATION */
enum ENUMERATION {
enumerator1, // ENUMERATOR = 0
enumerator2, // ENUMERATOR = 1
enumerator3, // ENUMERATOR = 2
enumerator4 // ENUMERATOR = 3
} variable = enumerator1;
Assigning an integer is done using the assignment operator =. The other enumerators may share the same value.
enum ENUMERATION {
enumerator1 = 3, // ENUMERATOR = 3
enumerator2 = 1, // ENUMERATOR = 1
enumerator3, // ENUMERATOR = 2
enumerator4 // ENUMERATOR = 3
};
However, enumerators cannot share the same identifier, which is similar to a global constant. In other words, enumerators are global data used across the project but unchangeable after initialization.
enum ENUMERATION1 {
enumerator1,
enumerator2,
enumerator3,
enumerator4
};
enum ENUMERATION2 {
enumeration4, // COMPILATION ERROR: MULTIPLE "enumerator4" EXIST!
enumeration5,
enumeration6
};
After defining an enumeration, initialize an enumeration variable with one of the enumerators. An integer variable can also store an enumerator from the enumeration.
/* ASSIGNING ENUMERATOR TO AN ENUMERATION VARIABLE */
ENUMERATION variable = enumerator1;
/* ASSIGNING ENUMERATOR TO AN INTEGER VARIABLE */
int variable = enumerator1;
Enumeration Class
Conventional enumeration must have an enumerator with a unique identifier across the project. However, enumerators of the enumeration class can have the same name in other enumeration classes.
enum class ENUMERATION1 {
enumerator1,
enumerator2
};
enum class ENUMERATION2 {
enumerator2, // NO COMPILATION ERROR: "enumerator2" IS LOCAL!
enumerator3
};
Unlike the enumeration, an integer variable cannot store an enumerator from the enumeration class. Use the scope resolution operator :: to access the enumerators.
/* ENUMRATION CLASS ASSIGNMENT */
ENUMERATION1 variable = ENUMERATION::enumerator2;
C++ recommends using enumeration class than conventional enumeration to prevent identifier confliction of enumerators.
Typedef Declaration
The typedef keyword aliases the existing data type to a different name, providing better readability.
typedef int dtypeName;
C language uses the typedef keyword to simplify the definition syntax of the user-defined data type such as structure and union since C language requires the keyword on every user-defined data definition. On the other hand, C++ does not need these keywords.
Type Alias Declaration
The C++: BASIC § Namespace section first introduced the using keyword on preventing calling the namespace repetitively. The using keyword increases the readability by aliasing the original data type with a different name, called type alias declaration.
using dtypeName = int;
There is no difference between the type alias declaration and typedef declaration, and these two are equivalent.
TEMPLATE
A template provides a format of function or class definition regardless of its data type. Developers can utilize this template to create similar functions and classes with ease. This chapter introduces defining and using a template.
Function Template
Define a template for a function using the following syntax:
/* FUNCTION TEMPLATE DEFINITION */
template <class T, class U>
U function(T arg1, U arg2) {
statements;
return something;
}
Instantiate a function template to use by specifying the data type in the angled bracket <>.
/* FUNCTION TEMPLATE INSTANTIATION */
function<int, float>(1, 3.0)
typename Keyword
The typename keyword explicitly tells the compiler the trailing identifier is indeed a type. In the template definition, the keyword is a synonym for the class keyword.
/* FUNCTION TEMPLATE DEFINITION: USING "typename" KEYWORD */
template <typename T, typename U>
U function(T arg1, U arg2) {
statements;
return something;
}
Class Template
Define a template for a class (aka. parameterized class) using the following syntax:
/* CLASS TEMPLATE DEFINITION */
template <class T, class U>
class CLASS {
public:
CLASS(T arg1, U arg2)
: field1(arg1), field2(arg2) { }
~CLASS() { }
T field1;
U field2;
U method1(T arg) {
return field1 + field2 - arg;
}
};
Instantiate a class template to use by specifying the data type in the angled bracket <>.
/* CLASS TEMPLATE INSTANTIATION */
CLASS<int, float> instance(1, 3.0);
The C++: CONTAINER chapter has already introduced two parameterized classes, which are array class and vector class.
std::array<int, 3> arr; // ARRAY CLASS : <class T, size_t N>
std::vector<int> vec; // VECTOR CLASS: <class T>
Class Template as Files
Since the class template is not a class but a template, C++ does not officially support creating a class template as a header-source file pair. Though not recommended, there is a possible approach.
/* HEADER "ClassName.h" */
template<class T, class U>
class ClassName
{
public:
ClassName(T arg1, U arg2);
~ClassName();
T field1;
U field2;
U method(T arg3);
};
/* SOURCE "ClassName.cpp" */
#include "ClassName.h"
template<class T, class U>
ClassName<T, U>::ClassName(T arg1, U arg2)
: field1(arg1), field2(arg2) { }
template<class T, class U>
ClassName<T, U>::~ClassName() { }
template<class T, class U>
U ClassName<T, U>::method(T arg3) {
return field1 + field2 - arg3;
}
/* MAIN SCRIPT "main.cpp" */
#include <iostream>
#include "ClassName.h"
#include "ClassName.cpp" // REQUIRED TO PREVENT LINKING ERROR!
int main() {
// INSTANTIATION
CLASS<int, double> instance(1, 3.0);
return 0;
}
Template Specialization
Some function or class templates may need an individual definition for a special occasion. Creating a distinct template definition when instantiated using a specific data type is called template specialization.
/* FUNCTION TEMPLATE DEFINITION */
template <class T, class U>
U function(T arg1, U arg2) {
statements;
return something;
}
/* FUNCTION TEMPLATE SPECIALIZATION: CHAR-EXCLUSIVE */
template <>
bool function<char>(int arg1, float arg2) {
statements;
return something;
}
Template Alias
The C++: USER-DEFINED DATA TYPE § Type Alias section explained declaring data type with a different alias name. This concept can be applied the same in aliasing a new name for a template, increasing readability with the using keyword.
/* FUNCTION TEMPLATE DEFINITION */
template <class T, class U>
U function(T arg1, U arg2) {
statements;
return something;
}
/* ALIASING TEMPLATE */
template <class X, class Y>
using aliasName = function<X, Y>;
/* FUNCTION TEMPLATE INSTANTIATION: USING ALIAS */
aliasName<int>(1, 3)
FILE MANAGEMENT
C++ language can read and write external files to save or load data. This chapter focuses on accessing and modifying the .txt extension text file.
Reading and writing external text file requires the following header:
| HEADER | DESCRIPTION |
|---|---|
fstream.h |
Input/output file stream class. |
Inside this header includes the std::ifstream and std::ofstream class that is respectively for data input to the program and data output from the program.
Opening Files
The file first needs to be opened to either read or write. Opening the file is done using the open() method that is available on both std::ifstream (for reading) and std::ofstream (for writing) class.
#include <fstream>
std::ifstream file;
file.open("sample.txt");
/* EQUIVALENT:
std::ifstream file("sample.txt");
*/
Reading Files
While there are several methods for reading the file, the best example is using the std::getline() function. Executing once will only extract a single text line, so getting every line of content requires a loop statement.
Aternatively, the extraction operator >> can get the text separated by the blank space and new line. Use the std::ifstream class for reading the external file.
#include <fstream>
std::ifstream file("sample.txt");
while (getline(file, line)) {
std::cout << line << std::endl;
}
Writing Files
The insertion operator << can write text data to the file. Use the std::ofstream class for writing the external file.
#include <fstream>
std::ofstream file("sample.txt");
file << "Hello World!\n";
Creating Files
A new file can be created using the same method of writing a file that does not bound by just writing on the existing file. Creating a file is done simply by designating a file name that doesn’t exist on the specified path.
#include <fstream>
std::ofstream file("path\\new_file.txt");
file << "Hello World!\n";
Closing Files
After opening the file, it should be closed manually. Opened file is closed using the close() method.
#include <fstream>
std::ofstream file("sample.txt");
statements;
file.close();
EXCEPTION
An exception is an inexecutable code error due to incorrect coding or input. Because it is not an error filtered upon compilation, a successfully built program immediately halts when encountering an exception. C++ language has keywords and code blocks for handling exceptions: throw, try and catch, and more. Exception handling aims to provide a stable program without any halt or crash.
try/catch Blocks
The try and catch block pair handles exceptions that occurred during the program execution. The paragraphs below explain the purpose of each code block.
The try block detects the exception that occurred inside, and when it does, the program immediately skips to the catch code block corresponding to the type of exception even if there are remaining codes.
The catch block contains the codes to execute when triggered by the try block. A single try block can have several catch blocks to prepare for various types of exceptions. If there is no catch block, the compilation error occurs, which is not an exception.
/* "try" BLOCK */
try {
statements;
}
catch(const std::out_of_range &e) {
// "catch" BLOCK: ERROR FOR ACCESSING ELEMENT OUT OF RANGE
}
catch(const std::exception &e) {
// "catch" BLOCK: ERROR FOR EVERY EXCEPTION
}
throw Keyword
The throw keyword manually halts execution and “throws” expression to the catch keyword. The keyword may throw numerical data or text data but also trigger exception without throwing any data by leaving blank.
However, the catch exception handler cannot check the thrown value, but only its parameter type.
/* "try" BLOCK */
try {
statements;
throw expression;
}
catch(int e) {
// "catch" BLOCK: INTEGER EXPRESSION
}
catch(char e) {
// "catch" BLOCK: CHARACTER EXPRESSION
}
For exception handler to catch every exception and parameter type, place ellipsis ... between parenthesis.
catch(...) {
// "catch" BLOCK: EVERY EXCEPTION & PARAMETER TYPE
}
Standard Error Stream
The C: BASIC § Input & Output section first introduced the most common output stream: the std::cout standard output stream. There are other kinds of stream designed for streaming errors, which is std::cerr standard error stream.
A stream is “a continuous flow of liquid, air, or gas.” In terms of computer communication, a stream means a path of data flow.
std::cerr << "Hello World!"
This distinguishment on streams allows selective control of transmitting data from the program to target devices/locations, such as a terminal or file.
PREPROCESSOR
C++ language compiler processes the script into two divided stages: preprocessing and compilation. On the stage of preprocessing, preprocessor directive such as #include is taken care of by the compiler. This chapter will introduce useful and commonly used preprocessor directives that is being implemented on development.
Macro Definition
A macro is a fragment of code that has a name (aka. identifier). These pieces of code can be simple data (such as a number, character, and string) or an expression with arguments. The formal and latter are respectively called the object-like and function-like macro.
A macro has a benefit that cannot change on runtime. A header file is where macros are generally defined, which passes to the source file via the #include inclusive directive.
#define Directive
The #define directive creates a new macro.
#define SOMETHING value // OBJECT-LIKE MACRO
#define ANYTHING(x, y) (x * SOMETHING - y) // FUNCTION-LIKE MACRO
#undef Directive
The #undef directive removes a defined macro. In some cases, this macro can resolve an error caused by naming collision due to other macros.
#undef SOMETHING
Predefined Macros
Compilers have common standard and compiler-specific predefined macros available for developers. Below is a list of links to the document on predefined macros such as MSVC, GCC, and more.
- MSVC: Microsoft Docs - Predefined Macros
- GCC: GCC Online Documentation - Predefined Macros
- Others: SourceForge Wiki
Conditional Inclusion
A conditional inclusion is a directive for conditional compilation; the compiler ignores the codes when the condition is false.
#if SOMETHING > value
statements;
#elif SOMETHING < value
statements;
#else
statements;
#endif
These directives are not for the substitution of if and else conditional statement despite having similar traits on evaluating the condition.
Macro Condition
A conditional inclusion can also evaluate whether the macro is defined or not.
// IF COMPILED ON 64-BIT ARM OR x64 ARCHITECTURE...
#ifdef _WIN64
statments;
#endif
// IF NOT COMPILED ON 64-BIT ARM OR x64 ARCHITECTURE...
#ifndef _WIN64
statements;
#endif
Pragma Directive
A pragma directive is for configuring features and options for a compiler. Compiler developed by different companies or organizations differs from each other, and this makes pragma a non-standard compiler-specific preprocessor directive.
The Pragma is an abbreviation of the word “pragmatic: a practical consideration.” The directive may have been named with such a term as it involves how the compiler practically works and processes.
- MSVC: Microsoft Docs - Pragma Directives and the Pragma Keyword
- GCC: GCC Online Documentation - Pragmas
This chapter focuses on pragma directives from MSVC as it is the most common and widely used C compiler provided by Microsoft Visual Studio.
#pragma once
The #pragma once pragma directive only includes the header file once instead of multiple times on every inclusion.
#pragma once
Because it prevents including the same header file multiple times for a single source file that can cause a re-definition problem, #pragma once is commonly used for include guard. Additionally, this pragma directive can reduce compilation time as it only includes the header once.
The following code is an example of include guard without using the #pragma once directive:
/* HEADER FILE: "header.h" */
#ifndef HEADER_FILE
#define HEADER_FILE
#endif /* HEADER_FILE */
If the header.h has not been processed, the compiler defines the HEADER_FILE for the first time. However, on the second encounter, the compiler will not process the header file again because of the macro conditioning.
#pragma region
Although it does not affect any on the compilation, the #pragma region and #pragma endregion pair supports expanding and collapsing code block on Visual Studio code editor.
#pragma region REGIONNAME
statements;
#pragma endregion
RANDOM
Randomization may be necessary for some programming, such as game development and statistical modeling. Random numbers generation requires the following header:
| HEADER | DESCRIPTION |
|---|---|
cstdlib.h |
Contains general-purpose functions such as random numbers, communication, and more. |
rand() Function
The rand() function is a pseudo-random number generator; it generates numbers randomly, but generated numbers are always the same on every program execution.
#include <cstdlib>
for (int index = 0; index < 3; index++) {
std::cout << rand() << " ";
}
// >> OUTPUT: 1 7 4 (1ST EXECUTION)
// >> OUTPUT: 1 7 4 (2ND EXECUTION)
// >> OUTPUT: 1 7 4 (3RD EXECUTION)
srand() Function
The srand() function does not generate random numbers but only determines the randomness based on the argument of seed. Each seed will provide randomness unique from others.
However, the rand() function is still required to generate a random number. Thus, the generated numbers always follow the same pattern on every program execution despite having the srand() function.
#include <cstdlib>
srand(98); // SEED FOR RANDOMNESS: INTEGER 98
for (int index = 0; index < 3; index++) {
std::cout << rand() << " ";
}
// >> OUTPUT: 8 7 5 (1ST EXECUTION)
// >> OUTPUT: 8 7 5 (2ND EXECUTION)
// >> OUTPUT: 8 7 5 (3RD EXECUTION)
Truly Random Number
For different randomness requires renewed seed on each program execution. The best method for seed renewal is by using a timestamp that is an integer representation of data and time.
Timestamp can be acquired using time() function included in ctime.h header. To get the timestamp of an executed time of a time() function, pass the integer 0 as its argument.
#include <cstdlib>
#include <ctime>
srand(time(0)); // SEED FOR RANDOMNESS: TIMESTAMP
for (int index = 0; index < 3; index++) {
std::cout << rand() << " ";
}
// >> OUTPUT: 4 0 0 (1ST EXECUTION)
// >> OUTPUT: 3 9 2 (2ND EXECUTION)
// >> OUTPUT: 5 7 1 (3RD EXECUTION)