소개
C++ 프로그래밍 언어는 C 프로그래밍 언어에서 기반된 범목적(general-purpose) 저급(low-level) 프로그래밍 언어이다. 코드를 순서대로 실행하는 절차적 프로그래밍 언어인 C와 달리, 객체지향적 프로그래밍도 지원하는 C++를 하이브리드 언어라고 부른다. C 프로그래밍 언어의 확장판으로 볼 수 있는 C++ 언어는 더 많은 기능을 제공하므로써 폭넓은 활용도를 보장한다.
컴파일 언어
참조: 컴파일러 vs. 인터프리터
C++ 프로그래밍 언어는 컴파일 언어(compiled language)이다. C++ 컴파일러는 국제표준기구(ISO)에서 표준을 발표한 년도에 따라 버전이 나뉘어진다. 가장 널리 사용되고 있는 버전으로는 C++98과 C++11, 그리고 가장 최신인 C++17이 존재한다. 상당한 C++ 프로그래밍 교재들이 C++98 표준을 기반으로 설명하나, 본 문서는 최소한 다양한 기능들이 추가된 C++11 표준을 기준으로 C++ 프로그래밍 언어에 대하여 설명한다.
전처리기
전처리기(preprocessor)는 컴파일러의 일부분으로 소스 코드를 컴퓨터 기계어로 변환하기 전에 컴파일 준비 작업을 이행한다. 전처리기가 수행하는 명령어를 전처리기 지시문(preprocessor directive)이라 부르며 해쉬 기호 #로 표시한다. 다음은 흔히 사용되는 전처리기 지시문 일부를 간략적으로 소개한다.
| 전처리기 지시문 | 예시 | 설명 |
|---|---|---|
#include |
#include <iostream> |
스크립트에 헤더 파일을 추가한다. |
#define |
#define SQUARE |
스크립트 내에서 사용할 수 있는 매크로를 정의한다. |
#pragma |
#pragma once |
컴파일러에 추가적 설정을 제공한다. |
전처리기는 C++ 프로그래밍 언어 문법을 따르거나 처리하지 않는다. 오로지 전처리기 지시문을 다루고 주석을 없애는 등의 작업을 컴파일러에 제공할 뿐이다. 전처리기 지시문은 필수요소가 아니지만 더 편리하게 프로그래밍하도록 돕는다.
설치
C++ 프로그래밍 언어로 프로그램을 개발하려면 C++ 컴파일러가 반드시 필요하다. C++ 컴파일러 종류는 개발사와 목적에 따라 다양하지만, 전부 동일한 ISO 표준에 따라 동작하므로 일반적인 경우에는 어떠한 컴파일러를 사용하던 무관하다. 프로그래밍 언어의 소스 코드 편집, 프로그램 빌드, 그리고 디버깅 기능을 제공하는 통합 개발 환경(integrated development environment; IDE)을 설치하면 대체로 권장되는 컴파일러가 함께 설치된다. 그러므로 본 장에서는 IDE 설치 및 프로젝트 생성 단계를 위주로 설명한다.
비주얼 스튜디오
비주얼 스튜디오(다운로드)는 마이크로소프트에서 개발한 IDE이며 Visual C++ 컴파일러를 제공한다. 비주얼 스튜디오의 세 가지 에디션 중에서 무료 버전인 커뮤니티 에디션으로도 충분하다. 통합 개발 환경인 만큼 C#이나 자바스크립트 등 다른 프로그래밍 언어도 함께 지원하므로 여러 종류의 구성요소를 제공한다. C++ 프로그래밍 언어 개발을 위해서면 “Desktop development with C++”를 선택한다.
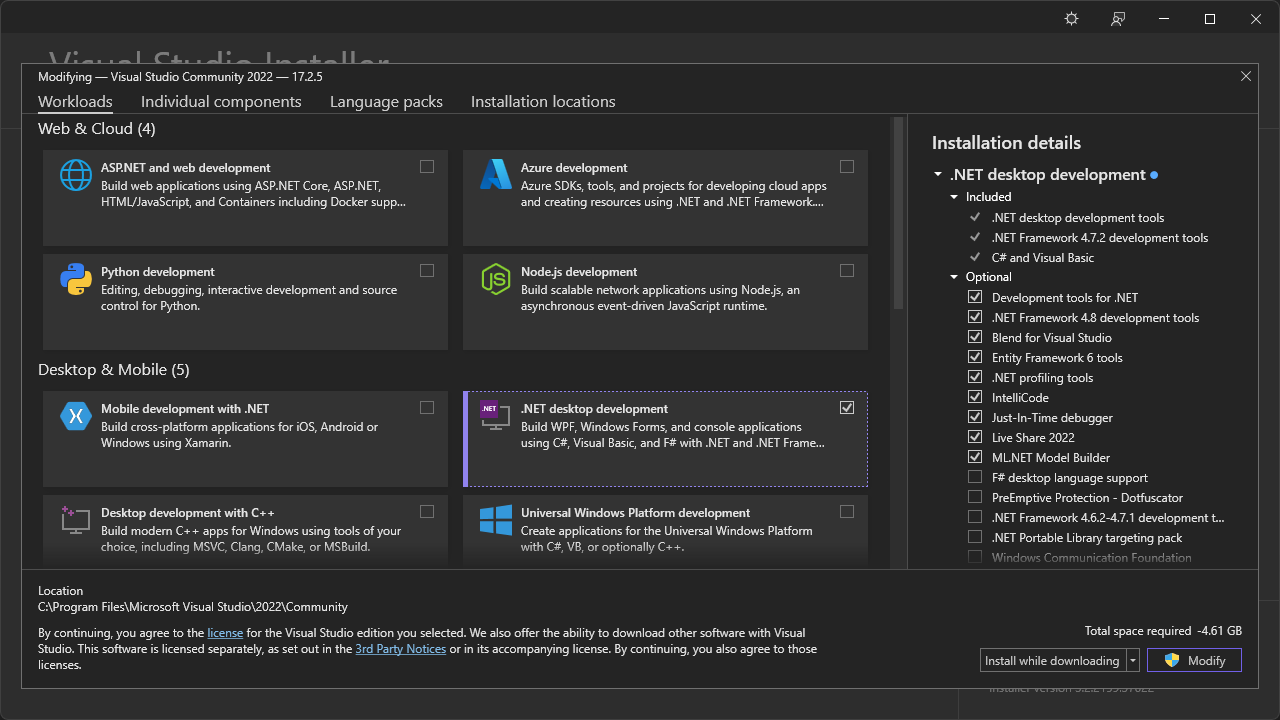
만일 한국어 지원을 원한다면 “Language packs” 탭에서 한국어를 함께 선택한다.
비주얼 스튜디오를 실행하면 아래와 같은 시작화면이 나타난다. 새로운 프로젝트를 생성하려면 오른쪽 하단의 “Create a new project” 버튼을 클릭한다.
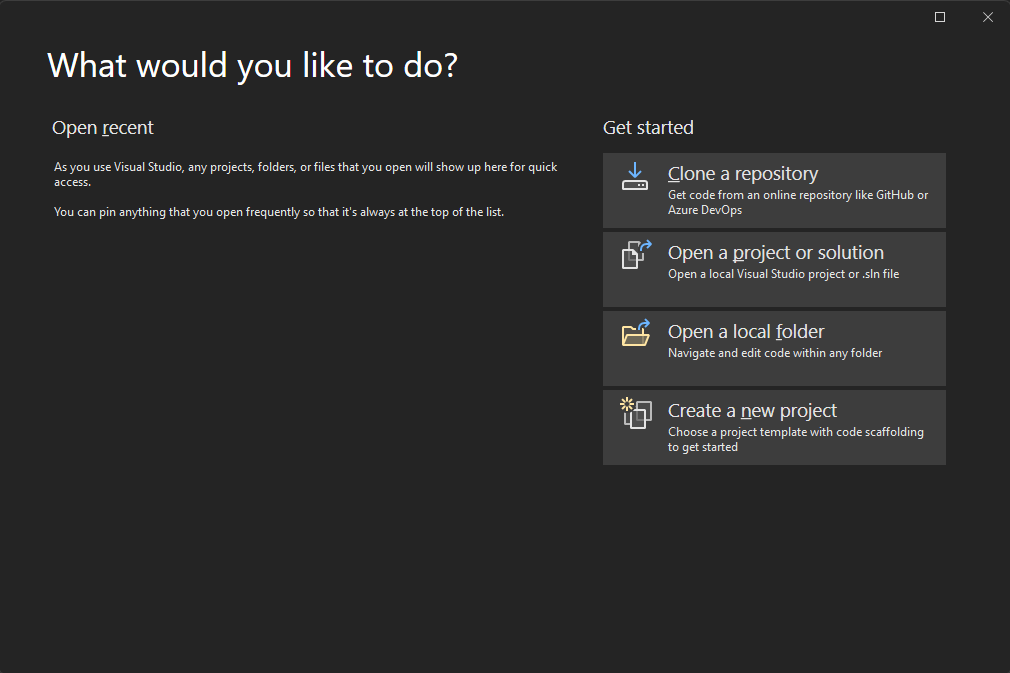
C++ 프로그래밍 언어로 다양할 어플리케이션을 만들 수 있어, 비주얼 스튜디오에서도 다양한 종류의 프로젝트 생성 선택지를 제공한다. 그 중에서 간단한 콘솔 어플리케이션을 위한 C++ 프로그래밍 언어 프로젝트 생성은 아래의 절차를 따른다:
-
프로그래밍 언어를 C++로 선택하여 “Console App”(콘솔 어플리케이션)을 클릭한다.
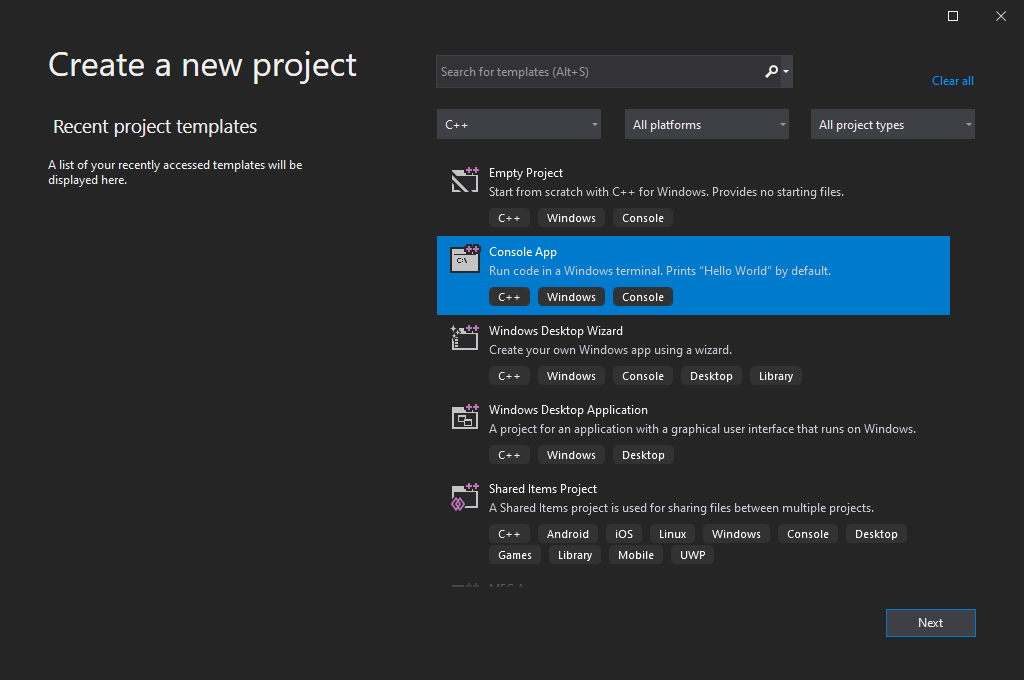
-
프로젝트 및 솔루션 이름을 선정한다. 여기서 프로젝트란, 소스 코드와 컴파일러 설정 등의 실질적인 코딩 내용을 관리하는
.vcxproj확장자 파일이며, 솔루션은 여러 프로젝트 파일을 하나의 폴더처럼 관리하는.sln확장자 파일이다. 비주얼 스튜디오에서 프로젝트는.sln파일로 열기를 권장한다.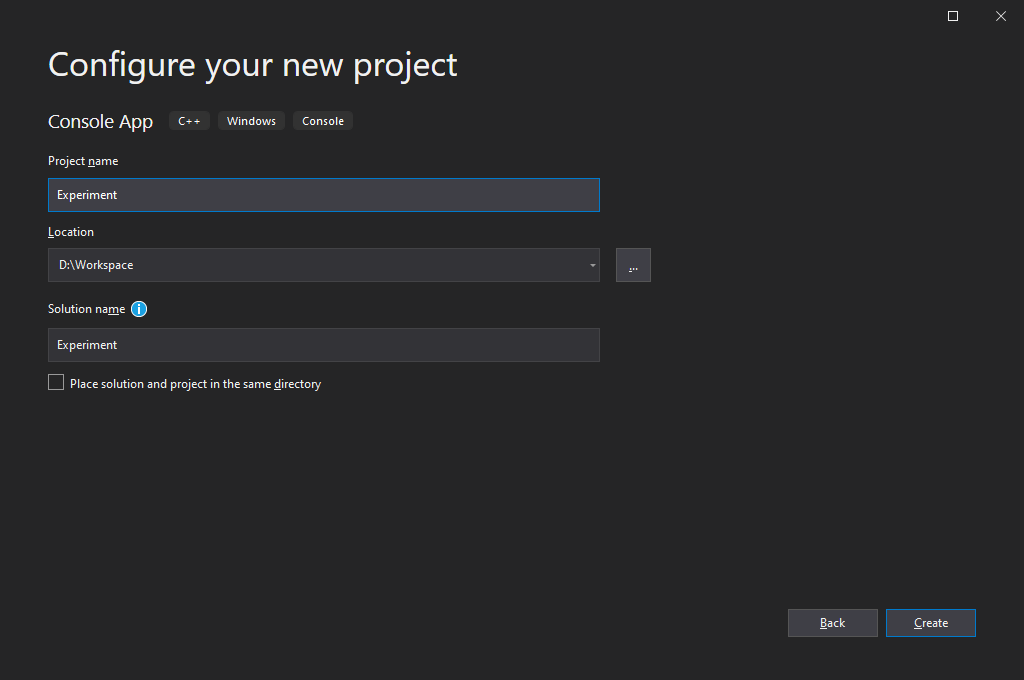
-
비주얼 스튜디오에서 알아서 준비한 프로젝트를 그대로 사용한다.
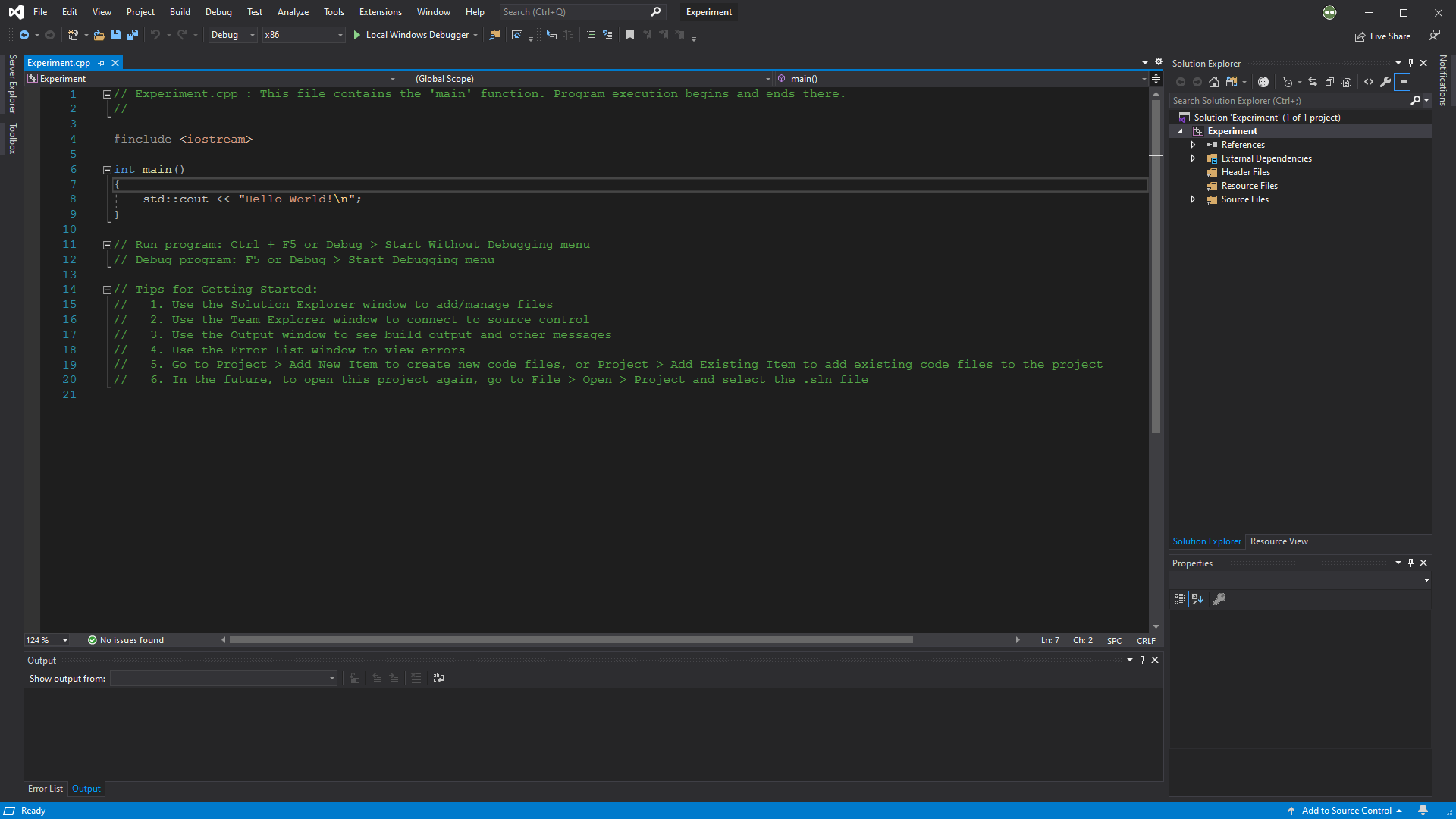
위의 3단계 절차는 콘솔 어플리케이션 프로젝트를 생성하는 가장 간단한 방법이다. 만일 아무것도 없는 빈 프로젝트를 생성하려면 여기를 참조한다.
비주얼 스튜디오는 두 가지의 실행 방법이 있다: 일반 실행 모드(Ctrl+F5)와 디버그 모드(F5)이다. 디버그(debug)는 프로그램에 발생한 문제를 해결하는 행위로, IDE에서 각 줄의 코드마다 어떠한 변화가 생겼는지 혹은 얼만큼의 시스템 리소스를 소모하는지 등을 확인할 수 있는 정보를 제공한다. 디버깅 목적이 아니면 일반 실행 모드를 사용하는 것을 권장한다.
엑스코드
엑스코드(다운로드)는 애플에서 개발한 macOS의 대표적인 IDE이며 Clang을 기본 컴파일러로 사용한다. 엑스코드는 Swift와 같은 여러 프로그래밍 언어를 지원하는데, 해당 IDE는 C++ 프로그래밍 언어 프로젝트 생성 옵션이 존재한다. 엑스코드를 실행하면 새로운 프로젝트를 File > New > Project...로 통해 생성한다.
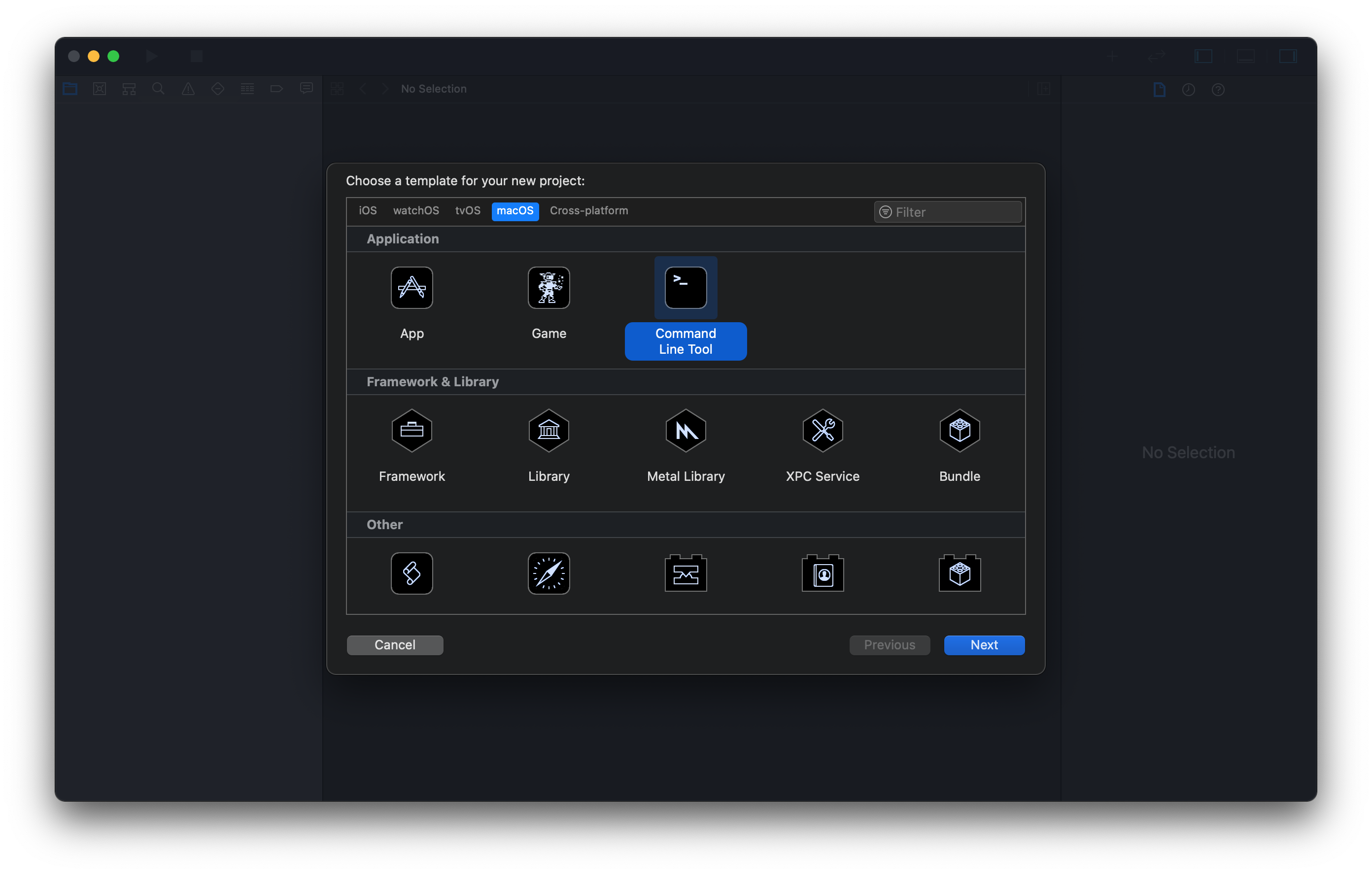
엑스코드 창이 나타나면 여러 프로젝트 선택지가 주어지는데, 이 중에서 C++ 프로그래밍 언어 프로젝트 생성을 위해서는 다음 절차를 따른다:
-
macOS 탭에서 가장 간단한 터미널 형식의 프로그램인 Command Line Tool을 선택한다.
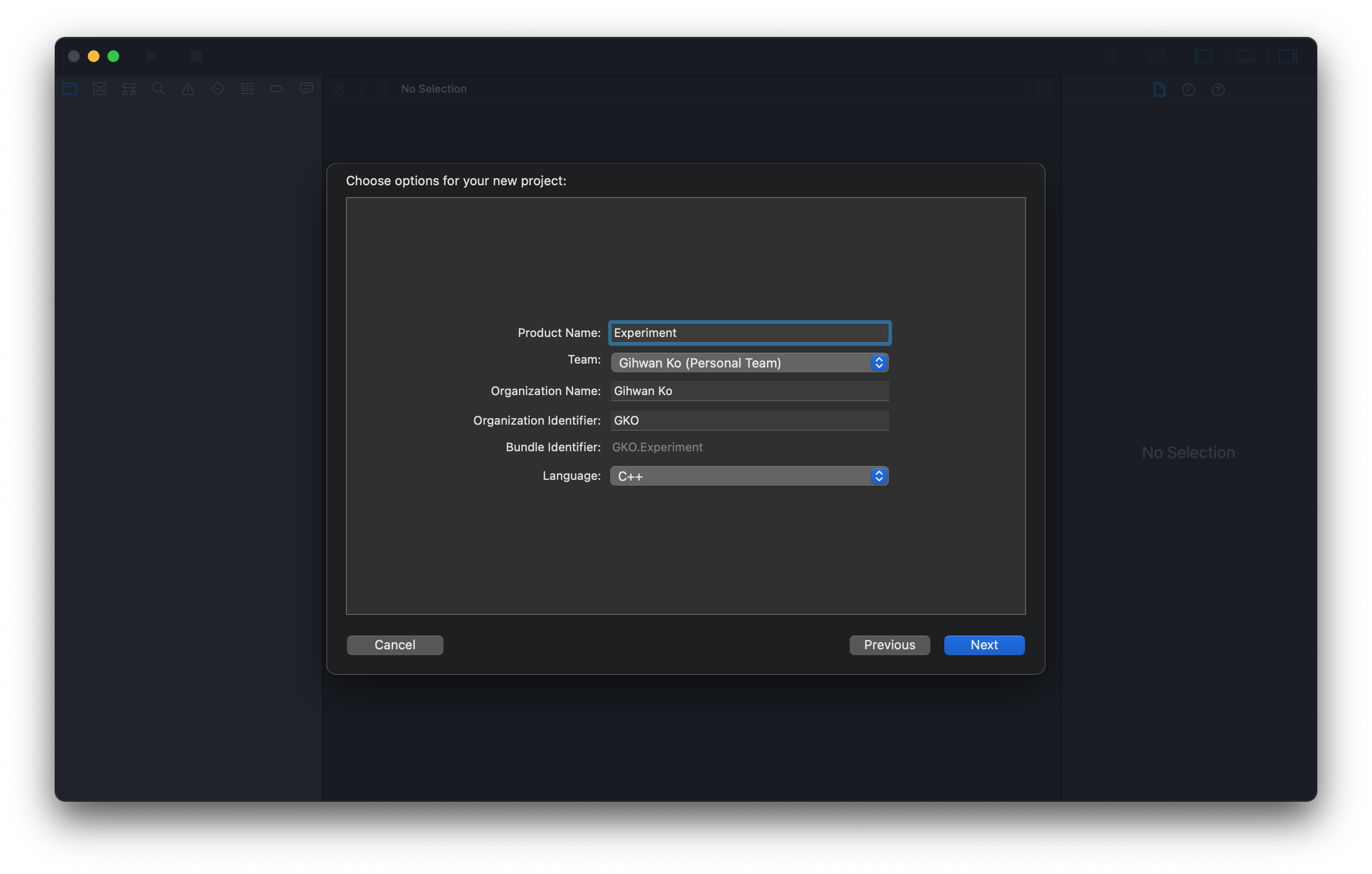
-
Product Name에는 프로젝트 이름을 선정하고, Language에는 C로 선택한다.
-
프로젝트를 저장할 경로를 지정한다.
-
좌측 패널의 Experiment 폴더 하에
main.cppC++ 프로그래밍 언어 소스 파일이 생성되어 있다.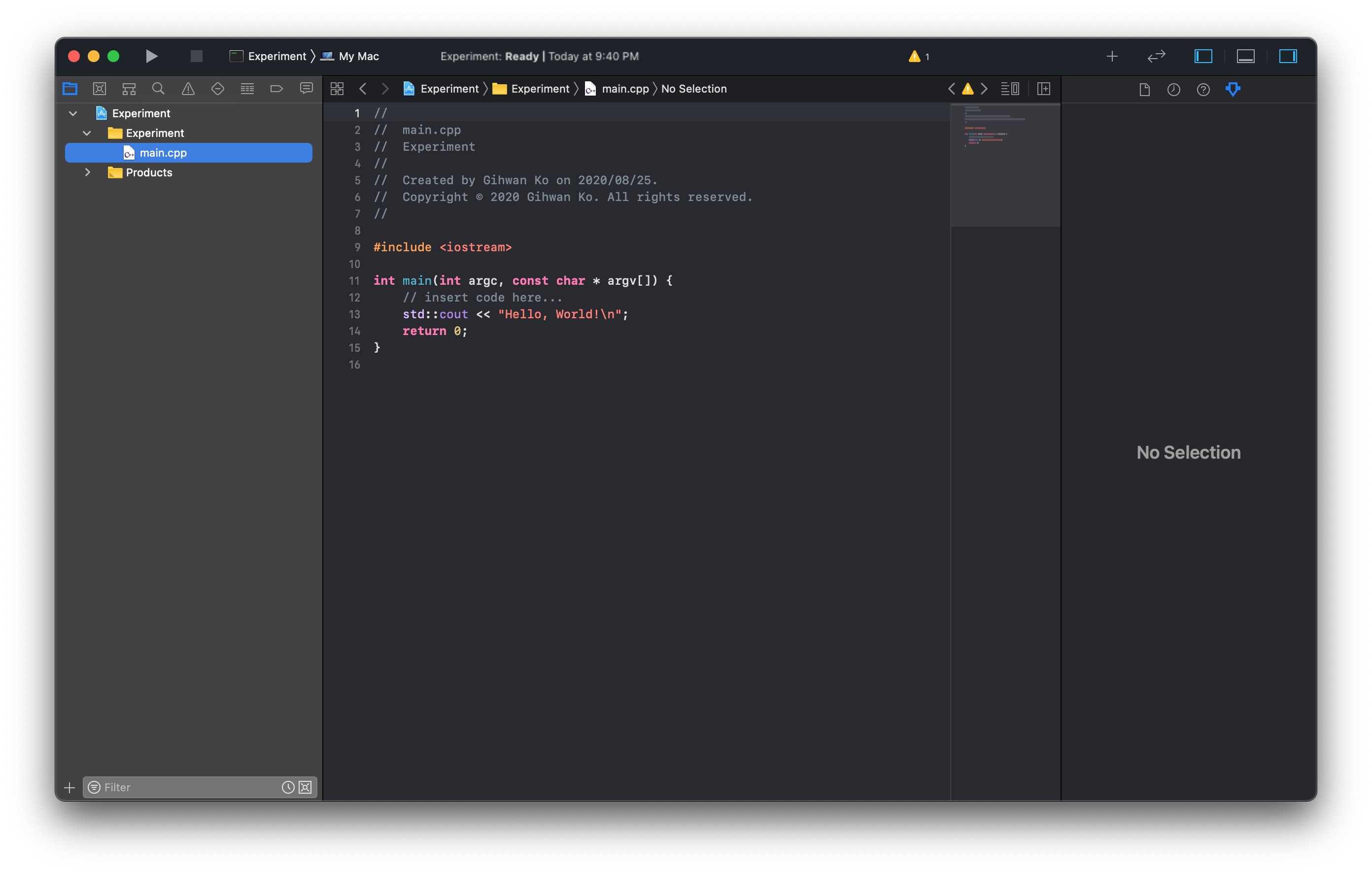
엑스코드에는 두 가지의 실행 방법이 있다: 일반 실행 모드와 디버그 모드이다. 두 실행 모드는 단축키 ⌘+R 하나로 통일되어 있으며, 실행 모드 변경은 프로젝트 설정에서 한다. 프로그램에 문제가 발생하여 검토가 필요한 경우, 관측하고자 하는 코드에 중단점(breakpoint)을 설정하여 디버깅을 한다. 활성화된 중단점을 모두 비활성화하여 프로그램을 일반적으로 실행하기 위해서는 단축키 ⌘+Y로 중단점 활성화 토글을 한다.
터미널
리눅스는 기본적으로 GCC 컴파일러가 설치되어 있으나, 위의 비주얼 스튜디오 및 엑스코드 IDE를 사용할 수 없다. 그러나 IDE는 프로그램 개발에 있어 큰 도움이 되는 소프트웨어이지, C++ 언어 프로그램을 만드는데 필수요소가 아니다. 물론 JetBrains의 CLion 등의 리눅스가 지원되는 IDE를 사용할 수 있으나, 최근 라즈베리 파이(Raspberry Pi)와 같은 소형화된 단일 보드 컴퓨터(single-board computer; SBC)를 사용하는 프로젝트가 많아져 경량화에 신경쓰기도 한다. 본 내용은 리눅스에서 터미널만을 사용하여 GCC로 컴파일하는 방법을 설명한다.
간단한 예시로 엑스코드 C++ 프로젝트 생성 (4단계) 그림에 나온 코드를 그대로 가져와 main.cpp C++ 프로그래밍 언어 소스 파일에 저장하였다.
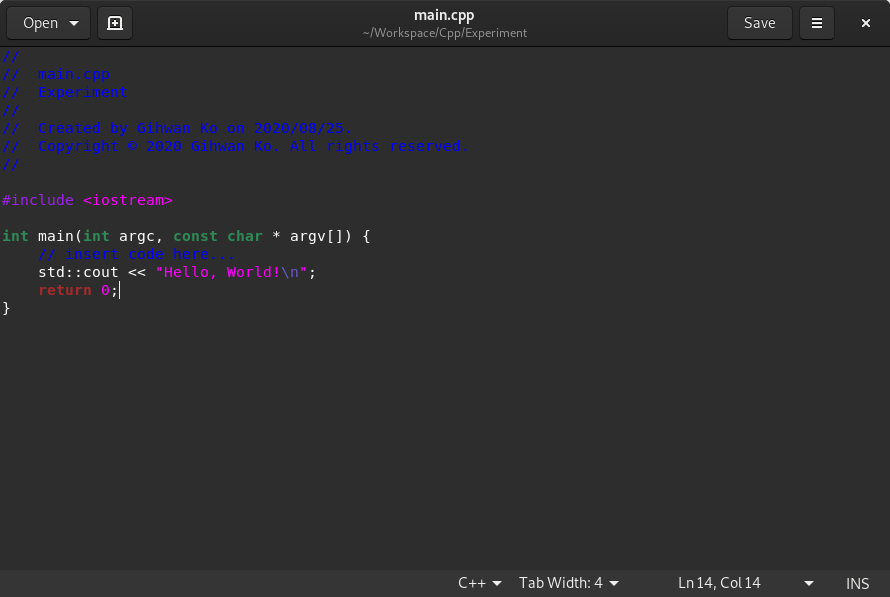
main.cpp 소스 파일은 ~/Workspace/C/Experiment 경로에 저장되었다고 가정한다.
터미널에서 소스 파일이 위치한 경로로 cd 명령어를 사용하여 이동한다. 소스 파일을 컴파일하기 위해서는 아래 명령어를 입력한다.
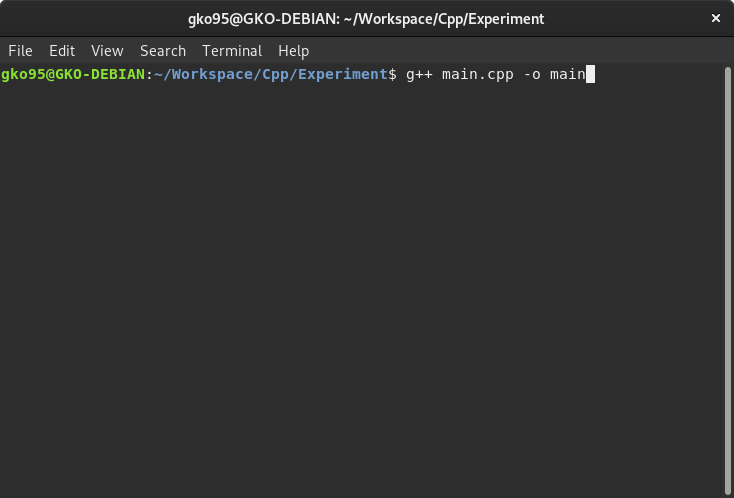
명령어의 의미는 다음과 같다:
GCC 컴파일러는
main.cpp소스 파일을 컴파일하여 이진 파일을 생성(-o)하는데, 생성된 이진 파일 이름은main으로 지정한다.
해당 예시는 GCC 컴파일러의 매우 간단한 예시 중 하나이며, 프로젝트 성질에 따라 외부 라이브러리 링크와 관련된 옵션 등을 추가할 수 있다.
main.cpp 소스 파일이 위치한 폴더를 확인하면 컴파일로 생성된 main 이진 파일이 찾을 수 있다.
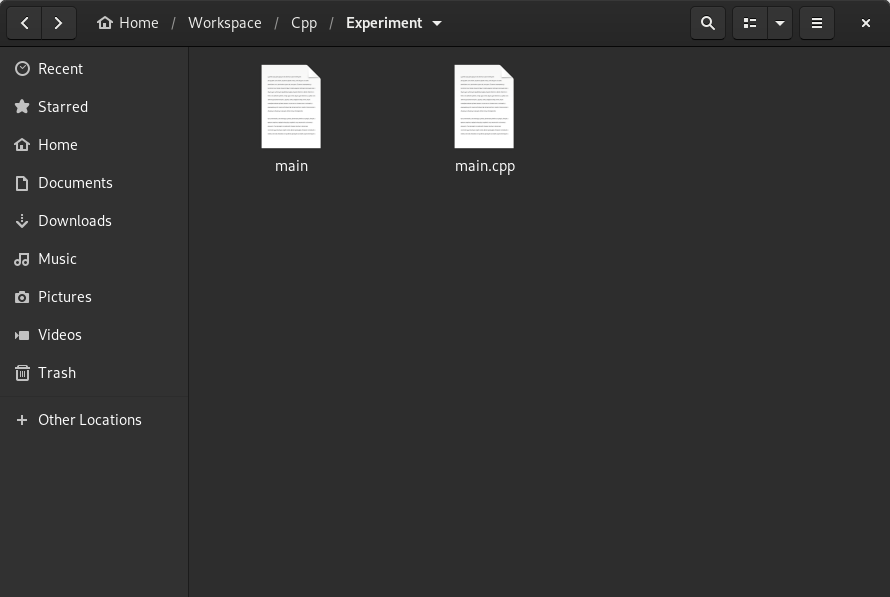
비록 .EXE와 같은 확장자가 없으나 실행이 가능한 파일이다. main 이진 파일을 실행하려면 터미널에서 ./와 함께 실행할 파일명을 입력한다.
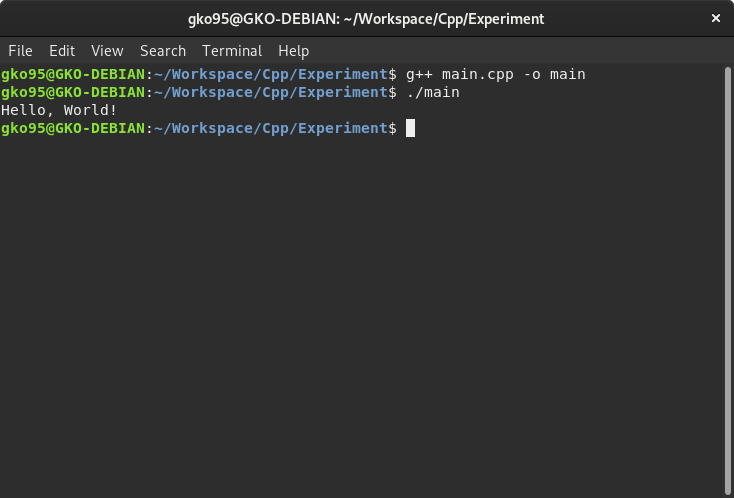
여기서 ./은 현재 터미널이 위치한 경로를 의미한다. 현재 경로를 표시하는 구문이 없으면 리눅스 터미널은 환경 변수(environment variable)에 입력된 경로를 위주로 main이란 파일을 찾으려다 대다수 실패할 것이다. 해당 내용은 절대경로 및 상대경로에서 다시 한 번 다룰 예정이다.
기초
각 프로그래밍 언어마다 준수되어야 할 규칙(일명 구문; syntax)과 기반이 되는 데이터들이 존재한다. 이를 어길 시에는 프로그램에 오류가 발생하거나 정상적인 동작을 보장할 수 없다. 실질적인 프로그래밍에 있어, 본 장에서는 C++ 프로그램 코딩에 기초적인 정보 제공을 목표로 한다.
헤더 파일
헤더 파일(header file)은 데이터 및 기능의 존재를 알리는 역할을 하는 C 언어 호환 .H 또는 C++ 전용 ` .HPP` 확장자 파일이다. 통상적으로 헤더 파일은 동일한 이름의 소스 파일과 짝을 이루며, 소스 파일에서 작성된 데이터와 코드를 헤더 파일로 통해 다른 소스 파일에서도 사용할 수 있도록 한다.
프로그래밍 언어에서 흔히 사용되는 데이터와 기능들은 바로 사용할 수 있도록 미리 컴파일되어 있다. 이를 표준 라이브러리라고 하며, 아래의 헤더 파일는 일부 표준 라이브러리를 소스 파일에 사용하게 한다. 이에 대한 자세한 내용은 라이브러리 장에서 다룰 예정이다.
| 헤더 파일 | 구문 | 설명 |
|---|---|---|
iostream |
#include <iostream> |
표준 입출력 함수를 정의한다:operator >>, operator << |
string |
#include <string> |
텍스트 데이터 처리 함수를 정의한다:append(), length() |
cmath |
#include <cmath> |
수학적 계산 관련 함수를 정의한다:exp(), cos() |
chrono |
#include <chrono> |
날짜 및 시간 처리 함수를 정의한다:system_clock(), duration() |
소스 파일에 헤더 파일을 불러오는 방식에는 두 가지가 존재하며, 홑화살괄호 <>와 큰 따옴표 ""가 있다.
#include <iostream>
#include "header.hpp"
이 둘은 전처리기가 헤더 파일을 어느 위치에서 찾을 것인지 차이점을 가진다.
-
#include <header.hpp>컴파일러 혹은 IDE에서 지정한 경로를 위주로 헤더 파일을 찾으며, 일반적으로 시스템 헤더 파일에 사용된다.
-
#include "header.hpp"현재 소스 파일이 위치한 경로를 위주로 헤더 파일을 찾는다. 만일 찾지 못하였을 시,
#include <header.hpp>와 같이 지정된 경로에서 헤더 파일을 재탐색한다. 일반적으로 사용자 정의 헤더 파일에 사용된다.
컴파일된 헤더
컴파일된 헤더(precompiled header)는 컴파일러에서 더 빠른 속도로 처리할 수 있도록 중간체 형태로 컴파일된 헤더 파일이다. 컴파일 시간을 줄일 수 있는 장점을 가져 수많은 헤더 파일을 가진 프로젝트 혹은 큰 용량을 가진 헤더 파일에 효율적이다. 하지만 컴파일된 헤더를 사용하면 컴파일 작업 자체에는 시간이 다소 걸리는 단점이 있다. 그러므로 용량이 작은 프로젝트나 자주 수정을 해야 하는 헤더 파일이 있다면 컴파일된 헤더 파일은 오히려 비효율적이다.
Visual C++에서는 pch.h (비주얼 스튜디오 2017 이전에는 stdafx.h)가 컴파일된 헤더 파일이다.
주석
주석(comment)은 프로그래밍에 있어 실행되지 않는 부분이며, 흔히 어떠한 정보를 간략히 스크립트 내에 입력하는데 사용된다. C++ 프로그래밍 언어에는 두 가지의 주석이 존재하며, 이들은 각각 한줄 주석과 블록 주석이라 부른다.
- 한줄 주석 (line comment): 코드 한 줄을 차지하는 주석이며, 두 개의 슬래시
//로 표시된다. - 블록 주석 (block comment): 코드 여러 줄을 차지하는 주석이며, 한 쌍의 슬래시와 별표
/* */로 표시된다.
/*
블록 주석:
코드 여러 줄을 차지하는 주석이다.
*/
// 한줄 주석: 코드 한 줄을 차지하는 주석이다.
표현식
프로그래밍에서는 표현식과 문장이 있다.
-
표현식(expression)
값을 반환하는 구문적 존재를 가리킨다. 표현식에 대한 결과를 도출하는 것을 평가(evaluate)라고 부른다.
2 + 3 // 숫자 5를 반환 2 < 3 // 논리 참을 반환 -
문장(statement)
실질적으로 무언가를 실행하는 구문적 존재를 가리킨다: 흔히 하나 이상의 표현식으로 구성되지만,
break및continue와 같이 독립적으로 사용되는 문장도 있다. C++ 프로그래밍 언어에서 모든 문장은 문장 종단자(statement terminator)인 세미콜론;으로 마무리 되어야 한다.int variable = 2 + 3; // 숫자 5를 "variable" 변수에 초기화 if (2 < 3) statement; // 논리가 참이면 "statement" 문장 실행 -
블록(block)
소스 코드를 중괄호
{}로 그룹화시키는 프로그래밍 언어의 어휘적 구조이다. 블록의 두 가지 의의는 (1) 여러 문장들을 하나의 문장처럼 다루거나 (2) 데이터가 취급되는 영역을 구분 짓는다.{ int variable = 2 + 3; if (2 < 3) statement; }
입력 및 출력
C++ 프로그래밍 언어는 iostream 헤더로부터 입출력 기능을 제공하며, 각각 추출 연산자 >>와 삽입 연산자 <<를 함께 사용한다.
-
입력 객체
std::cin터미널에서 데이터 입력을 빈 공간(띄어쓰기, 줄바꿈 등)까지 받는다; 터미널 입력을 데이터에 전달하기 위해 추출 연산자
>>와 함께 사용한다. -
출력 객체
std::cout터미널에 데이터를 출력한다; 데이터를 터미널 측으로 전달하기 위해 삽입 연산자
<<와 함께 사용한다.
std::cout << "입력: ";
std::string variable;
// 텍스트 입력
std::cin >> variable;
// 텍스트 출력
std::cout << "출력: " << variable;
입력: Hello World!
출력: Hello
줄바꿈 조작자
줄바꿈 조작자(new-line manipulator) std::endl는 C++ 표준 라이브러리에서 제공하는 텍스트 줄바꿈(newline)이다.
std::cout << "Hello" << std::endl << "World!";
Hello
World!
식별자
식별자(identifier)는 프로그램을 구성하는 데이터들을 구별하기 위해 사용되는 명칭이다. 즉, 식별자는 개발자가 데이터에 직접 붙여준 이름이다. C++ 프로그래밍 언어에서 식별자를 선정하는데 아래의 규칙을 지켜야 한다.
- 오직 영문, 숫자, 밑줄
_만 허용된다. - 첫 문자는 숫자로 시작할 수 없다.
- 공백은 허용되지 않는다.
- 대소문자를 구분한다.
자료형
자료형(data type)은 데이터를 어떻게 표현할 지 결정하는 요소이며, C++ 프로그래밍 언어에서는 여러 자료형이 존재한다. 각 자료형마다 데이터를 표현하기 위해 필요한 바이트 크기가 정해져 있다.
바이트(byte)란, 컴퓨터에서 메모리에 저장하는 가장 기본적인 단위이다. 자료형마다 크기가 정해진 이유는 효율적인 메모리 관리 차원도 있으나 CPU 연산과도 깊은 연관성을 갖는다.
아래는 C++ 프로그래밍 언어가 갖는 자료형의 일부이며, 더 많은 목록은 여기에서 확인할 수 있다:
| 키워드 | 자료형 | 설명 |
|---|---|---|
short |
정수 | 소형 정수 크기: 2바이트 |
int |
정수 | 기본 정수 크기: 2 또는 4바이트 |
long |
정수 | 대형 정수 크기: 4 또는 8바이트 |
float |
부동소수점 | 32비트 단정밀도 실수 크기: 4바이트 |
double |
부동소수점 | 64비트 배정밀도 실수 크기: 8바이트 |
char |
문자: '' |
단일 문자: 'A' 및 '?'.크기: 1바이트 |
std::string |
문자열: "" |
std 네임스페이스에 포함된 일련의 문자들.크기: 알수 없음 (문자 개수에 따라 다름) |
bool |
논리형 | 논리의 참과 거짓을 true(0이 아닌 정수)와 false(정수 0)로 표시.크기: 1바이트 |
auto |
자동 | 적절한 자료형으로 자동 선택. 복잡한 자료형을 간략히 정의하는데 매우 유용하다. |
void |
보이드 | 불특정 자료형. 크기: 1바이트 |
아래는 C++ 프로그래밍 언어 자료형에 대한 추가적인 설명이다.
-
int정수 자료형은 C/C++ 프로그래밍 언어 국제표준에 의하면 최소 크기가 16비트, 즉 2바이트로 명시되어 있다. 이는 16비트 시스템의 워드(word)에서 감안된 것으로, 현재는 마이크로컨트롤러 등의 임베디드 시스템을 제외한 32비트 (및 64비트) 시스템에 맞게 대중적으로 4바이트 크기를 갖는다. -
long정수 자료형은 C/C++ 프로그래밍 언어 국제표준에 의하면 최소 크기가 32비트, 즉 4바이트로 명시되어 있다. 그러므로 32비트 (및 16비트) 시스템에서는 4바이트, 그리고 64비트 시스템에서는 8바이트 크기를 갖는다.
unsigned 키워드
unsigned 키워드는 자료형 중에서 최상위 비트를 정수의 부호를 결정하는 요소로 사용하지 않도록 한다. 아래의 16비트 정수형인 short는 원래 최상위 비트를 제외한 나머지 15개의 비트로 정수를 표현한다. unsigned 키워드를 사용하면 음의 정수를 나타낼 수 없지만, 16개의 비트로 양의 정수를 더 많이 표현할 수 있다.
short // 표현 가능 범위: -32768 ~ +32767
unsigned short // 표현 가능 범위: +0 ~ +65535
sizeof 연산자
sizeof 연산자는 데이터나 자료형가 메모리에 할당된 바이트 크기를 반환한다.
sizeof(int); // 크기: 4바이트
sizeof(char); // 크기: 1바이트
변수
변수(variable)는 데이터를 지정된 자료형으로 저장하는 식별자를 갖는 저장공간이다. 아래 예시는 variable이란 식별자를 갖는 정수형 변수에 숫자 3을 할당한다. 시스템적 관점에서 바라보면 variable 정수형 변수의 존재가 컴파일러에 각인되고 메모리가 할당되어 3이란 값이 저장되는 것으로, 이를 변수의 “정의(definition)”라고 부른다.
/* 변수 "variable"의 정의 */
int variable = 3;
정수 자료형의 변수인 variable을 생성한 동시에 값 3을 할당하였는데, 변수로의 최초 할당을 “초기화(initialization)”라고 부른다. 아래는 변수를 정의하는 과정에서 초기화를 나중에 하는 예시 코드이다. 한 번 정의된 변수는 컴파일러 측에서 이미 존재를 알고 있으므로, 이후 변수에 다른 데이터를 저장하거나 호출할 때 자료형을 함께 언급할 필요가 없다. 초기화되지 않은 변수를 호출하는 것은 변수에 연동된 메모리가 가공되지 않은 상태로 잠재적 위험을 초래할 수 있기 때문에, 일반적으로 C++ 프로그래밍 언어 컴파일러는 이를 오류로 치부한다.
/* 변수 "variable"의 정의 */
int variable;
variable = 3;
동일한 자료형의 변수 여러 개를 한꺼번에 정의하려면, 식별자마다 쉼표 ,로 구분지을 수 있다.
/* 다수의 정수 자료형 변수 정의 */
int variable1 = 3, variable2 = 4, variable3;
변수의 “선언(declaration)”은 메모리 할당 여부와 관계없이 컴파일러에게 해당 변수의 존재성을 알리는 행위이다. 그러나 이미 변수를 정의하는 과정에서 컴파일러에게 변수의 존재를 알리는 과정이 있는데, 이 또한 변수의 선언에 해당한다. 그러므로 C/C++ 프로그래밍 언어 ISO 표준의 § 6.2 Declarations and definitions 부문에 의하면 일반적인 변수의 선언은 정의와 동일하다고 본다. 단, 몇 가지의 특이사항이 존재한다.
- 함수 및 클래스 전방선언
- 함수 및 템플릿 매개변수 선언
using선언 및 지시문alias선언extern선언typedef선언- 기타 등등
차후에 소개할 extern 키워드는 변수를 선언만 하고 정의하지 않으므로 데이터를 저장할 메모리가 할당되지 않는다. 이러한 변수에 데이터를 저장하거나 호출하려는 행위는 시스템 오류를 야기하므로 컴파일이 불가하다. Visual C++ 컴파일러에서는 LNK1120 오류의 원인이 된다.
위에서 언급한 선언과 정의에 대한 설명은 C/C++ 프로그래밍 언어에서 매우 중요한 개념이지만 프로그래밍 입문자들에게 쉽게 간과되는 내용이다.
변수는 오로지 지정된 자료형 데이터만을 할당받아야 하지 않다. 아래 예시 코드는 정수형 및 문자형 변수에 값 75로 초기화하였다. 정수형 변수에는 정수 75로 저장되지만, 문자형 변수의 경우 ASCII 코드에 의하여 대문자 ‘K’로 저장된다.
long variable1 = 75; // variable1에는 정수 75가 저장
char variable2 = 75; // variable2에는 문자 'K'가 저장
거의 모든 프로그래밍 언어는 할당 기호를 기준으로 왼쪽에는 피할당자(변수), 오른쪽에는 할당자(데이터 혹은 변수)가 위치한다. 반대로 놓여질 경우, 오류가 발생하거나 원치 않는 결과가 도출될 수 있다.
상수
상수(constant)는 한 번 데이터를 할당한 후 변경할 수 없는 특별한 변수이며, const 키워드와 함께 정의한다.
/* 상수 정의 */
const int variable = 1;
지역 변수 및 전역 변수
C++ 프로그래밍 언어에서 변수가 코드 중에서 어디에 정의되었는지에 따라 두 가지의 종류로 구분된다.
-
지역 변수(local variable)
블록 내부에서 정의된 변수이다. 지역 변수에 저장된 데이터는 블록 밖에서는 소멸되므로 외부에서 사용할 수 없다.
int main() { /* 지역 변수 */ int variable; return 0; } -
전역 변수(global variable)
블록 내에 속하지 않은 외부에 정의된 변수이다. 전역 변수는 어느 블록에서도 호출만으로 지역 변수와 함께 사용할 수 있다. 단, 변수의 충돌로 인한 예상치 못한 결과와 오류를 방지하기 위해 가급적 전역 변수의 사용은 피하도록 한다.
/* 전역 변수 */ int variable; int main() { return 0; }
네임스페이스
네임스페이스(namespace)는 식별자의 유일성을 보장하기 위한 데이터 분류 공간으로, namespace 키워드를 통해 생성하여 블록 {} 안에 데이터들을 분류한다. 네임스페이스 안에 또 다른 네임스페이스를 정의할 수 있으며, 이를 네스티드 네임스페이스(nested namespace)라고 부른다. 그러나 네임스페이스 또한 유일한 식별자를 가져야 하기 때문에 동일한 영역범위(scope)에 놓여진 네임스페이스는 이름이 중복되어서는 안된다.
서로 다른 이름의 폴더(네임스페이스) 안에 동명의 파일(데이터) 혹은 폴더(네스티드 네임스페이스)를 보관할 수 있는 것과 같은 개념이다.
네임스페이스에 들어있는 데이터 및 네스트디 네임스페이스를 접근하기 위해서는 범위지정 연산자(scope resolution operator) ::를 사용한다.
/* 네임스페이스 1 정의 */
namespace namespace1
{
namespace nested
{
int variable = 3;
}
}
/* 네임스페이스 2 정의 */
namespace namespace2
{
namespace nested
{
int variable = 7;
}
}
std::cout << namespace1::nested::variable << std::endl; // 출력: 3
std::cout << namespace2::nested::variable << std::endl; // 출력: 7
여기서 입력 및 출력 앞단에 위치한 std는 표준 네임스페이스(standard namespace)로 C++ 표준 라이브러리에 정의된 데이터를 관리한다.
전역 네임스페이스
전역 네임스페이스(global namespace)는 어느 네임스페이스에도 속하지 않는 최외각 영역범위이다. 전역 네임스페이스는 범위지정 연산자 ::를 식별자의 접두부에 기입하여 명시한다.
다음은 위의 예시 코드에 전역 네임스페이스를 명시하여 데이터를 호출한 것이다.
::namespace1::nested::variable;
::namespace2::nested::variable;
using 키워드
using 키워드는 네임스페이스 내의 데이터를 간편하게 접근할 수 있도록 한다. 즉, 네임스페이스를 별도로 명시하지 않아도 데이터 호출이 가능하게 한다. 하지만 using 키워드의 무분별한 남용은 컴파일러가 어느 네임스페이스의 데이터를 호출하는 것인지 구별하지 못하게 하여 오류가 발생할 위험이 높다.
-
using지시문(using-directive)스크립트 파일에서 해당 네임스페이스 전체를 생략한다.
/* std 네임스페이스 생략 */ using namespace std; cout << "Hello World!" << endl; -
using선언(using-declaration)네임스페이스 내의 개별 데이터를 선택적으로 간략화시킨다.
/* std::endl 함수 간략화 */ using std::endl; std::cout << "Hello World!" << endl;
자료형 변환
자료형 변환(type casting)은 상수 혹은 변수로부터 호출한 데이터를 강제로 다른 자료형으로 바꾸는 작업이다.
-
암묵적 자료형 변환(implicit type casting)
변환 시 데이터 손실이 없어 컴파일러에서 자연적으로 처리되는 변환이다. 흔히 유사한 자료형을 작은 크기에서 큰 크기로 키울 때 자동적으로 발생한다.
short A = 1; // 2바이트 정수형 int B = A; // 4바이트 정수형 -
명시적 자료형 변환(explicit type casting)
변환 시 데이터 손실의 위험을 감수하며 데이터의 자료형을 바꾼다. C 형식 캐스팅은 소괄호
()안에 자료형을 기입한다.float A = 1.9; // 4바이트 부동소수점 int B = (int)A; // 4바이트 정수형 - 완전 호환 불가: 정수 부분만 반환된다.
C 형식의 자료형 변환이 가지던 결함을 보완하기 위해 C++11부터 네 가지의 새로운 캐스팅 연산자가 소개되었다. C++ 프로그래밍 언어에서는 다음 네 개의 연산자를 사용한 자료형 캐스팅을 권장한다.
static_cast 연산자
static_cast 연산자는 명시적 그리고 암묵적 변환에 사용되는 가장 일반적인 자료형 캐스팅 연산자이다.
int variable = 3;
static_cast<double>(variable);
const_cast 연산자
const_cast 연산자는 상수 전용 자료형 캐스팅 연산자이며, 상수의 자료형 이외에도 값 또한 참조를 통해 변경할 수 있다.
const int A = 3; // 변환 이전: A = 3
int *B = const_cast<int *>(&A);
*B = 1; // 변환 이후: A = 1
dynamic_cast 연산자
dynamic_cast 연산자는 클래스 혹은 객체의 다형성(polymorphism)을 처리하는데 사용되는 자료형 캐스팅 연산자이다.
derivedClass *A = new derivedClass;
baseClass *B = dynamic_cast<baseClass *>(A);
reinterpret_cast 연산자
reinterpret_cast 연산자는 포인터를 다른 자료형의 포인터로 변환하는데 사용되는 자료형 캐스팅 연산자이다.
int *variable = 3
reinterpret_cast<double *>(variable)
reinterpret_cast 연산자는 소개된 네 가지 캐스팅 연산자 중에서 데이터 손상 위험이 가장 높으므로 사용 시 매우 신중해야 한다.
연산자
연산자(operator)는 피연산 데이터를 조작할 수 있는 가장 간단한 형태의 데이터 연산 요소이다. 연산자는 피연산자의 접두부, 접미부, 혹은 두 데이터 사이에 위치시켜 사용한다.
산술 연산자
산술 연산자(arithmetic operator)는 정수나 부동소수점 자료형 산술 연산에 사용된다: 가장 기본적인 +, -, *, / 사칙 연산자부터 나눗셈의 나머지 %를 구할 수 있다. 산술 연산을 쉽게 읽을 수 있도록 숫자와 산술 연산자 사이에 공백을 넣어도 연산에는 아무런 영향을 주지 않으므로 무관한다.
할당 연산자
할당 연산자(assignment operator)는 할당 기호 =와 조합하여 산술 연산 코드를 더욱 간결하게 작성할 수 있도록 한다.
| 연산자 | 예시 | 동일 |
|---|---|---|
= |
x = y |
x = y; x 변수에 y 변수의 값을 할당하고, 할당된 값을 반환한다. |
+= |
x += y |
x = x + y |
-= |
x -= y |
x = x - y |
*= |
x *= y |
x = x * y |
/= |
x /= y |
x = x / y |
%= |
x %= y |
x = x % y |
여기서
=연산자가 할당된 값을 반환한다는 것을 통해 다음과 같은 표현식을 구현할 수 있다.int variable; std::cout << variable = 3;3
증감 연산자
증가 연산자(increment operator) ++ 및 감소 연산자(decrement operator) --는 데이터를 1만큼 증가 혹은 감소하는데 간략하게 한 줄로 표현할 수 있도록 한다.
-
접두부
해당 변수를 1만큼 증가/감소시킨 다음에 표현식을 평가한다.
x = ++y; // 동일: y = y + 1; x = y; x = --y; // 동일: y = y - 1; x = y; -
접미부
표현식을 평가한 다음에 해당 변수를 1만큼 증가/감소시킨다.
x = y++; // 동일: x = y; y = y + 1; x = y--; // 동일: x = y; y = y - 1;
비교 연산자
비교 연산자(relational operator)는 두 데이터를 대조하는데 사용된다: 초과 >와 미만 <, 이상 >=과 이하 <=, 그리고 동일 ==와 다름 != 관계 부합 여부에 따라 논리적 참 혹은 거짓이 반환된다.
논리 연산자
논리 연산자(logical operator)는 논리 자료형의 조합이 논리적으로 참인지 거짓인지 판별한다.
| 연산자 | 논리 | 설명 |
|---|---|---|
&& |
논리곱 | 모든 데이터가 참이면 true를 반환하고, 그렇지 않으면 false을 반환한다. |
|| |
논리합 | 하나 이상의 데이터가 참이면 true를 반환하고, 그렇지 않으면 false을 반환한다. |
! |
보수 | 참을 거짓으로, 또는 거짓을 참으로 변경한다. |
탈출 문자
탈출 문자(escape character)는 백슬래시 기호 \를 사용하며, 문자열로부터 탈출하여 텍스트 데이터 내에서 특정 연산을 수행하도록 한다. 이전에 문자열 자료형을 소개할 때, \n 탈출 문자를 사용하여 문자열 줄바꿈을 구현한 것을 보여주었다.
std::cout << "Hello\nWorld!";
Hello
World!
조건 및 루프
조건문(conditional statement) 및 반복문(loop statement)은 프로그래밍에 가장 흔히 사용되는 코드 문장(statement) 중 하나이다. 여기서 문장이란, 실질적으로 무언가를 실행하는 코드를 의미한다. 본 장에서는 C++ 프로그래밍의 조건에 따라 실행하는 조건문과 반복적으로 실행하는 반복문을 소개한다.
if 조건문
if 조건문은 조건 혹은 논리가 참(true)일 경우 코드를 실행하며, 거짓(false)일 경우에는 코드를 실행하지 않는다.
if (condition) {
statements;
}
// 간략화된 문장
if (condition) statement;
else 조건문
else 조건문은 단독으로 사용될 수 없으며 반드시 if 조건문 이후에 사용되어야 한다. 조건부가 거짓(false)으로 판정되면 실행할 코드를 포함한다.
if (condition) {
statements;
}
else {
statements;
}
else if 조건문
else if 조건문은 else와 if 조건문의 조합으로 이전 조건이 거짓(false)일 때 새로운 조건을 제시한다.
if (condition) {
statements;
}
else if (condition) {
statements;
}
else {
statements;
}
조건 연산자
조건 연산자(ternary operator) ?:는 세 가지 인수만을 사용하여 조건문을 아래와 같이 간략하게 표현한다. 조건 연산자는 가독성을 감소시키므로 과용해서는 안되지만 변수 할당에 유용하다.
condition ? true_return : false_return;
switch 조건문
switch 조건문은 전달받은 인자를 case의 상수와 동일한지 비교하여 논리가 참일 경우 해당 지점부터 코드를 실행하며, 거짓일 경우에는 다음 case로 넘어간다. 선택사항으로 default 키워드를 통해 어떠한 case 조건에도 부합하지 않으면 실행될 지점을 지정한다.
switch (argument) {
case value1:
statements;
break;
case value2:
statements;
break;
case value3:
statements;
break;
default:
statements;
}
switch 조건문이 어느 case 코드를 실행할지 결정하는 것이라고 쉽사리 착각할 수 있으나, 이는 사실상 break 탈출문 덕분이다. 탈출문이 없었더라면 아래 예시 코드처럼 해당 조건의 case 코드 실행을 마쳤어도 다음 case 코드로 계속 진행하는 걸 확인할 수 있다. 즉, case 키워드는 코드 실행 영역을 분별하는 것이 아니라 진입 포인트 역할을 한다.
int variable = 2;
// switch 조건문의 동작 예시
switch (variable) {
case 1:
std::cout << "Statement 1" << std::endl;
case 2:
std::cout << "Statement 2" << std::endl;
case 3:
std::cout << "Statement 3" << std::endl;
default:
std::cout << "Statement 4" << std::endl;
}
Statement 2
Statement 3
Statement 4
while 반복문
while 반복문은 조건 혹은 논리가 참(true)일 동안 코드를 반복적으로 실행하며, 거짓(false)일 경우에는 반복문을 종료한다.
while (condition) {
statements;
}
// 간략화된 문장
while (condition) statement;
do 반복문
do 반복문은 코드를 우선 실행하고 조건 혹은 논리가 참(true)일 경우 코드를 반복하며, 거짓(false)일 경우에는 반복문을 종료한다.
do {
statements;
} while (condition);
break 문
break 문(일명 탈출문)은 반복문을 조기 종료시키는데 사용된다. 반복 실행 도중에 탈출문을 마주치는 즉시 가장 인접한 반복문으로부터 탈출한다.
continue 문
continue 문은 반복문의 나머지 실행문을 전부 건너뛰어 다시 반복문의 조건부로 돌아간다. break와 달리 반복문은 종료되지 않고 여전히 살아있다.
for 반복문
for 반복문은 조건 혹은 논리가 참(true)일 동안 코드를 반복적으로 실행하며, 거짓(false)일 경우에는 반복문을 종료한다. for 반복문은 조건 평가 외에도 지역 변수를 초기화 및 증감할 수 있는 인자가 있다.
for (initialize; condition; increment) {
statements;
}
// 간략화된 문장
for (initialize; condition; increment) statement;
for 반복문의 우선 initialize에서 반복문 지역 변수를 정의하거나 외부 변수를 불러와 반복문을 위한 초기값을 할당한 다음 condition에서 조건을 평가한다. 논리가 참이면 코드를 반복적으로 실행하며, 거짓일 경우에는 반복문을 종료한다. 블록 내의 코드가 마무리되었거나 continue 문을 마주하면 increment에서 변수를 증감하고, condition으로 돌아가 절차를 반복한다.
범위형 for 반복문
C++11부터 범위형 for 반복문이 새로 소개되었으며, 조건 만족 여부에 따라 반복하는 게 아니라 주어진 범위 내에서 반복한다. 일반적으로 데이터 요소를 하나씩 나열할 수 있는 시퀀스 컨테이너가 범위로 사용된다.
for (element : container) {
statements;
}
// 간략화된 문장
for (element : container) statement;
goto 이동문
goto 이동문은 다른 문장으로써는 절대로 접근이 불가한 코드에 도달할 수 있도록 한다 (일명 제어 전달; control transfer). goto 키워드에 명시된 레이블로 제어를 전달하나, 이 둘은 반드시 동일한 함수 내에 위치해야 한다. 레이블은 goto 문 이전이나 이후에 위치하여도 무관하다.
int main() {
// 제어 전달: "label"로 이동
goto label;
// "label" 레이블
label:
statements;
}
단, goto 이동문을 사용할 때에는 매우 조심해야 하며 무리한 남용은 스파게티 코드의 원인이 된다.
컨테이너
C++ 프로그래밍 언어는 여러 데이터를 하나의 변수로 저장하는 컨테이너(container)를 제공한다. 그 중에서 저장된 다수의 데이터, 일명 요소가 순번을 가지는 컨테이너를 시퀀스 컨테이너(sequence container)라고 부른다. 본 장은 가장 흔히 사용되는 시퀀스 컨테이너를 중점으로 설명한다.
배열
배열(array)은 동일한 자료형의 데이터를 일련의 순서로 담는 저장공간이다. 정의 시 식별자 뒤에는 대괄호 []가 위치하여 배열이 담을 수 있는 데이터 용량 size를 정수 리터럴(integer literal)이나 상수로 지정한다. 한 번 정의된 배열의 크기는 변경이 불가하다. 배열의 데이터 초기화는 중괄호 {} 내에 항목을 순서대로 쉼표로 나누어 나열한다. 초기 데이터 개수는 배열 용량을 초과해서는 안되지만, 반면에 데이터 개수가 용량을 미치지 못하면 나머지는 0 혹은 NULL로 초기화된다.
/* 배열 정의 1 */
int arr[size] = {value1, value2, ... };
/* 배열 정의 2
: 배열 용량을 지정하지 않으면 데이터 개수만큼 크기가 정해진다. */
int arr[] = {value1, value2, ... };
배열의 각 요소에 할당된 데이터는 대괄호 []를 사용해 0번부터 시작하는 인덱스 위치를 호출할 수 있다. 그러나 배열 자체를 호출하면 컴퓨터 메모리에 배열이 저장된 주소가 반환된다. 배열의 메모리 주소는 첫 번째 요소(즉, 인덱스 0번)의 주소와 일치하는데, 그 다음 주소에는 다음 인덱스 요소가 연쇄적으로 할당되어 있다. 자세한 내용은 포인터를 다룰 때 소개한다.
int arr[3] = {value1, value2, value3};
std::cout << arr << std::endl; // 출력: 00D2FBA8
std::cout << &arr[0] << std::endl; // 출력: 00D2FBA8
std::cout << &arr[1] << std::endl; // 출력: 00D2FBAC (= 00D2FBA8 + 정수형 4바이트)
이러한 배열의 특징으로 인해 배열은 정의 외에 한꺼번에 할당이 불가능하다. 그렇지만 개별 요소를 재할당하여 데이터를 변경할 수 있다.
int arr[3];
/* 배열의 개별 요소 할당 */
arr[0] = value1;
arr[1] = value2;
arr[2] = value3;
배열의 크기
sizeof 연산자가 배열에 사용되면 배열의 크기가 아닌, 배열이 차지하는 총 바이트 수를 반환한다. 배열의 각 요소마다 자료형만큼 메모리를 차지하므로 배열의 크기를 구하기 위해서는 다음과 같은 표현식을 사용한다. 자료형의 요소들로 구성된 배열을 해당 자료형으로 나누면 요소의 개수가 계산된다.
int arr[3];
std::cout << sizeof(arr)/sizeof(int); // 출력: 3 (= 배열의 크기)
다차원 배열
배열은 또 다른 배열을 요소로 가질 수 있으나, 자료형이 동일해야 하며 요소로 작용하는 배열들의 크기는 모두 같아야 하는 제약을 갖는다.
/* 다차원 배열 정의 1 */
int arr[size1][size2] = { {value11, value12, ... }, {value21, value22, ...}, ... };
/* 다차원 배열 정의 2
: 첫 번째 차원은 배열 용량을 지정하지 않으면 배열 개수만큼 크기가 정해진다. */
int arr[][size2] = { {value11, value12, ... }, {value21, value22, ...}, ... };
배열 클래스
배열 클래스(array class)는 <array> 헤더로부터 제공되는 배열이며, 기술적인 방면에서 일반 배열과 동일하지만 C++ 표준 라이브러리에서 지원하는 추가 속성 덕분에 각 요소에 대한 접근성이 수월하다. 이러한 특성은 범위형 for 반복문과 같이 순차성이 요구되는 코드에서 활용되는데 적합하다.
#include <array>
/* 배열 정의: C++ 배열 클래스 */
std::array<int, 3> arr;
벡터 클래스
벡터 클래스(vector class)는 <vector> 헤더로부터 제공되는 크기를 가변할 수 있는 스퀀스 컨테이너이다.
배열의 데이터는 스택 영역에 저장되는 반면, 벡터는 힙 영역에 저장하기 때문에 크기 변경이 가능하다. 이에 대한 내용은 메모리 관리에서 설명한다.
비록 유연하다는 장점이 있으나, 배열에 비해 상대적으로 처리 속도가 느리다는 단점을 지닌다.
#include <vector>
/* 벡터 정의: C++ 벡터 클래스 */
std::vector<int> vec;
문자열
C/C++ 프로그래밍 언어는 일련의 문자들, 일명 문자열(string)을 한 개 이상의 char 문자들과 널 문자 \0로 구성된 배열로 표현할 수 있으며, 이를 “C 형식 문자열(C-style string)”이라고 부른다.
/* C 형식 문자열 */
char arr[] = "Hello"; // 즉, arr[] = {'H', 'e', 'l', 'l', 'o', '\0'};
char* ptr = "World!"; // 포인터를 활용한 문자열 표현 방법
아래는 C 표준 라이브러리에서 제공하는 문자열과 관련된 함수들의 목록이다. 단, 이들을 사용하기 위해서는 cstring 헤더를 추가해야 한다.
| 함수 | 예시 | 설명 |
|---|---|---|
strcat() |
strcat(str1, str2); |
문자열 str2를 문자열 str1 뒤에 덧붙인다. |
strcpy() |
strcpy(str1, str2); |
문자열 str2을 문자열 str1에 복사한다. |
strlen() |
strlen(str); |
문자열 str 크기를 반환하며, 이때 널 문자는 제외된다. |
문자열 자료형
C++ 표준 라이브러리는 iostream (혹은 string) 헤더로부터 자체적으로 문자열 자료형 std::string을 제공한다. 문자열 자료형은 흔히 문자열 객체(string object)라고도 부른다.
/* C++ 문자열 자료형 */
std::string variable = "Hello World!";
문자열 자료형은 매우 편리하지만, 윈도우 API 또는 POSIX 등의 운영체제 API를 사용할 경우에는 불가피하게 C 형식 문자열을 사용해야 할 경우가 흔히 발생한다.
함수
함수(function)는 독립적인 코드 블록으로써 데이터를 처리하며, 재사용이 가능하고 호출 시 처리된 데이터를 보여주어 유동적인 프로그램 코딩을 가능하게 한다. 함수는 이름 뒤에 소괄호가 있는 function() 형식으로 구별된다.
float variable = 3.14159
std::cout << std::round(variable);
// 실수의 소수점을 반올림하는 "std::round()" 함수
3
함수의 기능을 정의(definition)하기 위해서는 두 가지의 구성요소가 반드시 필요하다:
/* 함수 정의 */
void function() {
std::cout << 1 + 2;
}
/* 함수 호출 */
function(); // 출력: 3
함수가 정의하기도 전에 호출되면 순차적으로 실행되는 C++ 프로그래밍 언어 특성상 존재하지 않는 함수를 호출하는 것으로 간주되어 오류가 발생한다. 함수 프로토타입(prototype), 일명 전방선언(forward declaration)은 컴파일러에게 미리 함수의 존재를 알려주어 정의되기 전에 호출할 수 있다. 프로토타입은 선택사항이며, 우선적으로 선언될 수 있게 스크립트 상단부에 기입하는 게 일반적이다.
/* 함수 프로토타입 */
void function();
/* 함수 호출 */
function();
/* 함수 정의 */
void function() {
std::cout << 1 + 2;
}
함수명 뒤에 소괄호 () 기입여부에 따라 의미하는 바가 다르다.
-
function()은 함수에 정의된 코드를 실행한다.void function() { std::cout << 1 + 2 << std::endl; } function(); std::cout << "반환: " << function(); // [C2679] 이항 '<<': 'void' 형식의 오른쪽 피연산자를 사용 하는 연산자가 없거나 허용 되는 변환이 없습니다.3 -
function은 함수의 메모리 주소를 가리킨다.void function() { std::cout << 1 + 2 << std::endl; } function; std::cout << "반환: " << function;반환: 002713B1
함수 안에 새로운 함수를 정의하는 것은 C++ 프로그래밍 언어에서 허용되지 않는다.
return 반환문
return 반환문은 함수로부터 데이터를 함수에 지정된 자료형으로 반환하는 함수 전용 문장이다. 반환문이 실행되면 하단에 코드가 남아 있음에도 불구하고 함수는 즉시 종료된다. 함수의 자료형이 void이면 반환문은 필요가 없으나, 흔히 함수를 조기에 종료하기 위해서도 사용된다.
// return 반환문이 있는 사용자 정의 함수
int function() {
std::cout << "Hello World!" << std::endl;
return 1 + 2;
}
std::cout << function();
Hello World!
3
매개변수 및 전달인자
다음은 함수에 대해 논의할 때 중요하게 언급되는 매개변수와 전달인자의 차이에 대하여 설명한다.
- 전달인자 (argument): 전달인자, 혹은 간략하게 “인자”는 함수로 전달되는 데이터이다.
- 매개변수 (parameter): 전달인자를 할당받는 함수 내의 지역 변수이다. 그러므로 매개변수는 함수 외부에서 호출이 불가능하다. 매개변수 선언은 함수의 소괄호
()내에서 이루어진다.
매개변수와 전달인자는 개념적으로 다른 존재이지만, 동일한 데이터를 가지고 있는 관계로 흔히 두 용어는 혼용되어 사용하는 경우가 많다.
다음은 매개변수에 사용되는 연산자로 전달인자을 받는데 유연성을 제공한다. 이들은 프로그래밍 구문상 명확한 구별이 가능해야 하므로 반드시 일반 매개변수 뒤에 위치해야 한다.
| 연산자 | 구문 | 설명 |
|---|---|---|
= |
arg=value |
전달인자가 없으면 기본값 value가 대신 매개변수에 할당된다. |
/* 함수 프로토타입 */
int function(int arg1, float arg2 = 2.0);
/* 함수 호출 */
function(1); // 반환: 3
function(1, 3.14); // 반환: 4 (= 1 + 3.14의 정수만 추출)
/* 함수 정의 */
int function(int arg1, float arg2) {
return arg1 + arg2;
}
배열은 위와 동일한 구문으로 인자를 매개변수로 건네줄 수 없으며, 아래의 두 가지 방법이 존재한다:
-
매개변수를 배열로 선언한다.
void function(int arg[]); int arr[3] = {value1, value2, value3}; function(arr); // 배열을 함수의 인자로 넘겨준다. // 넘겨받은 인자를 배열 그대로 받아들인다. void function(int arg[]) { statements; return; } -
매개변수를 포인터로 선언한다. 배열 자체를 호출하면 배열의 첫 번째 요소의 메모리 주소를 가져오기 때문에 가능하다. 특히 배열의 각 요소가 할당된 메모리 주소는 연쇄적이므로, 바로 옆 (
int정수형이면 +4) 메모리 주소에는 배열의 다음 요소가 저장된 메모리 공간이다.void function(int *arg); int arr[3] = {value1, value2, value3}; function(arr); // 배열을 함수의 인자로 넘겨준다. // 넘겨받은 인자를 배열이 아닌 포인터로 받아들인다. void function(int *arg) { statements; return; }
정적 변수
정적 변수(static variable)는 프로그램이 실행되는 동안 함수를 탈출하여도 데이터가 소멸되지 않고 보존되는 static 키워드의 특수한 지역 변수이다. 해당 함수를 다시 호출하면 함수 종료 직전의 데이터를 그대로 이어서 사용할 수 있다.
int main() {
/* 정적 변수 */
static int variable;
return 0;
}
함수 오버로딩
함수 오버로딩(function overloading)은 동일한 이름 및 반환 자료형을 갖는 함수가 전달받은 인자의 자료형 및 개수에 따라 달리 동작하는 것을 의미한다. 이들은 각 인자 전달의 경우에 따라 제각각의 정의를 갖는다.
/* 오버로딩된 함수의 프로토타입 */
float function(int arg1, float arg2);
float function(float arg1, float arg2);
function(1, 3.0); // 반환: 4.0
function(1.0, 3.0); // 반환: -2.0
/* 오버로딩된 함수의 정의 1 */
float function(int arg1, float arg2) {
return arg1 + arg2;
}
/* 오버로딩된 함수의 정의 2 */
float function(float arg1, float arg2) {
return arg1 - arg2;
}
진입점
진입점(entry point)는 프로그램이 시작되는 부분을 의미하며, C++ 프로그래밍 언어의 경우 main() 함수에서부터 코드가 실행된다. 진입점은 프로토타입이 존재하지 않으며, 유일해야 하므로 복수의 main() 함수가 존재하거나 찾지 못하면 요류가 발생하여 컴파일이 불가하다.
/* C++ 프로그래밍 언어 진입점: main() */
int main(int argc, char **argv) {
return 0;
}
본 문서의 대부분 코드 예시에는
main()함수가 직접 언급되지 않았으나, 전역 변수와 함수 등을 제외한 코드들은main()함수 내에서 작성되어야만 실행된다.
C/C++ 프로그래밍 언어 표준에 의하면 main() 함수는 반드시 int 정수형을 반환해야 하며, EXIT_SUCCESS(혹은 정수 0) 그리고 EXIT_FAILURE이 있다. 만일 반환문이 없을 시, 컴파일러는 자동적으로 return 0; 문장을 main() 함수의 말단에 삽입한다.
main() 진입점은 아래와 같은 매개변수를 함축적으로 가진다.
argc: 전달인자 개수(argument count).argv: 전달인자 데이터 배열(argument vector); 매개변수 정의는char *argv[]로 대체 가능하다.
위의 전달인자 동작은 터미널 명령창을 통해 시 명백히 관측할 수 있다.
./app.exe option1 option2
| 매개변수 | argc |
argv[0] |
argv[1] |
argv[2] |
|---|---|---|---|---|
| 데이터 | 3 | ./app.exe |
option1 |
option2 |
WinMain() 함수
WinMain() 함수는 Win32 또는 MFC와 같은 GUI 프레임워크 어플리케이션의 진입점이다. 본 진입점의 핵심은 마우스 클릭이나 키보드 입력 등으로 발생된 메시지를 수신받아 이를 처리할 함수로 전달하는 메시지 루프(Message Loop)에 있다.
int WinMain(HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPSTR lpCmdLine,
int nCmdShow)
{
/* 메시지 루프 진입:
"return MSG.wParam;"를 통해 루프 탈출 */
// 메시지 루프 진입에 실패하면 WinMain()를 종료한다.
return 0;
}
진입점의 메시지 루프는 WM_QUIT 메시지를 수신할 때까지 지속적으로 어플리케이션 구동에 필요한 메시지 수신 및 분배가 이루어진다. 만일 메시지 루프 진입에 실패하면 진입점의 return 반환문에 의해 프로그램이 즉시 종료된다.
DllMain() 함수
DllMain() 함수는 .DLL 확장자를 가지는 동적 링크 라이브러리의 진입점이다.
int DllMain(_In_ HINSTANCE hinstDLL,
_In_ DWORD fdwReason,
_In_ LPVOID lpvReserved)
{
return 0;
}
콜백 함수
콜백 함수(callback function)는 인자로 전달되는 함수이다. 콜백 함수를 전달받는 함수, 일명 호출 함수(calling function)는 블록 내에서 매개변수 호출을 통해 콜백 함수를 실행한다.
여기서 콜백이란, 전달인자로 전달된 함수가 다른 함수에서 언젠가 다시 호출(call back)되어 실행된다는 의미에서 붙여진 용어이다.
아래는 콜백 함수의 예시이며, 이에 대한 자세한 원리는 차후 함수 포인터에서 설명한다.
/* 호출 함수 */
float calling(float (*function)(int, float), int arg) {
// 콜백 함수의 호출
return function(arg, 3.14159);
}
/* 콜백 함수 */
float callback(int arg1, float arg2) {
return (float)arg1 + arg2;
}
std::cout << calling(callback, 1);
4.141590
람다 표현식
람다 표현식(lambda expression), 일명 람다 함수(lambda function) 혹은 익명 함수(anonymous function)는 이름이 없는 (즉, 익명) 함수로써 흔히 일회용 함수로 사용된다. 비록 식별자가 필요하지 않는 익명 함수일지라도, 람다 표현식은 재호출을 위해 일반 함수처럼 식별자를 가질 수 있다.
| 구문 |
|---|
[]() -> type { statements; } |
캡쳐 조항 [] 및 매개변수 ()로 전달받은 데이터를 블록 {}에서 처리하여 type 자료형으로 반환한다 (기본 반환 자료형: auto). |
C++ 프로그래밍 언어의 람다 표현식에는 캡쳐 조항(capture clause) []이란 독특한 성질을 갖는다. 매개변수가 정의된 람다 표현식을 호출할 때 데이터를 전달받으면, 캡쳐 조항은 람다 표현식을 정의할 때 유효범위 내에 있는 정의된 변수를 블록 {}으로 전달한다.
-
캡쳐 조항이
[]처럼 비어있다면 아무런 캡쳐가 이루어지지 않는다.int number = 3; char letter = 'A'; auto lambda = [] { std::cout << number; // [C3493] 기본 캡처 모드가 지정되지 않았기 때문에 'number'을 암시 적으로 캡처 할 수 없습니다. std::cout << letter; // [C3493] 기본 캡처 모드가 지정되지 않았기 때문에 'letter'을 암시 적으로 캡처 할 수 없습니다. }; -
람다 표현식에서 사용하려는 변수명을 캡쳐 조항에 기입한다. 여기서 식별자 접두부에 앰퍼샌드
&기호 존재 여부에 따라 “값에 의한 캡쳐” 혹은 “참조에 의한 캡쳐”로 구분된다.자세한 내용은 C++ 프로그래밍 언어의 참조(reference)를 참고하도록 한다.
int number = 3; char letter = 'A'; /* 값에 의한 캡쳐 'number', 그리고 참조에 의한 캡쳐 'letter' */ auto lambda = [number, &letter] { std::cout << number; std::cout << letter; }; number = 7; letter = 'C'; lambda(); // 출력: 3C -
람다 표현식이 정의된 시점까지 유효범위 내의 변수들을 모두 캡쳐할 수 있다. 여기서 첫 조항이
[=]이면 “값에 의한 캡쳐” 혹은[&]이면 “참조에 의한 캡쳐”가 기본으로 설정된다. 만일 특정 변수의 캡쳐 방식을 달리하려면 2번에서 설명한 것처럼 별도로 식별자를 기입해야 한다.int number = 3; char letter = 'A'; /* 값에 의한 캡쳐 'number', 그리고 참조에 의한 캡쳐 'letter' */ auto lambda = [=, &letter] { std::cout << number; std::cout << letter; }; /* 동일: auto lambda = [&, number] { std::cout << number; std::cout << letter; }; */ number = 7; letter = 'C'; lambda(); // 출력: 3C
인라인 함수
인라인 함수(inline function)는 인라인 확장에 사용될 inline 키워드로 지정된 함수이다.
인라인 확장(inline expansion)은 컴파일 과정에서 함수 호출지(call site)를 함수 코드로 치환하는 최적화 기법이다.
프로그램 실행 (즉, 런타임) 도중에 함수를 호출하는데 소모되는 시간이 없으므로 속도가 소폭 향상되는 효과가 있으나, 과도한 사용은 프로그램 크기가 커지고 RAM 메모리를 더 많이 사용하는 단점으로 작용한다. 그러므로 인라인은 코드가 작지만 자주 사용되는 함수에 가장 적합하다.
/* 인라인 함수 */
inline void function(std::string arg) {
std::cout << arg;
}
int main() {
function("Hello World!");
return 0;
}
/* 동일:
int main() {
std::cout << "Hello World!";
return 0;
}
*/
재귀 함수
재귀 함수(recursive function)는 스스로를 호출하는 함수이다. 재귀 함수는 반드시 스스로를 호출하는 반복으로부터 탈출하는 기저 조건(base case)이 필요하다. 기저 조건이 없으면 무한 재귀가 발생하는데 프로그램 실행에 기여하는 메모리가 부족하여 충돌이 발생한다.
/* 예제: 펙토리얼 "!" */
int factorial(int arg) {
// 기저 조건: 재귀로부터 탈출하는 조건
if (arg == 1)
return 1;
else
return arg * factorial(arg - 1);
}
포인터
포인터(pointer)는 변수가 저장된 메모리 주소를 저장하는 변수이다. 32비트와 64비트 운영체제에서 하나의 메모리 주소는 각각 4바이트(십육진수 8자리)와 8바이트(십육진수 16자리) 크기를 가진다. 포인터를 정의할 때 일반 변수처럼 자료형이 요구되나 그 뒤에는 별표 *가 있어야 한다. 변수의 메모리 주소는 참조 연산자 &로 반환받는다.
/* 포인터 정의 */
int *ptr = &variable;
십육진수의 메모리 주소는 수기로 직접 작성하는 것이 아니며, 이는 매우 위험한 행위이다! 접근하려는 데이터의 메모리 주소가 항상 같을거란 보장이 없기 때문이다.
비록 메모리 주소는 4바이트 혹은 8바이트로 표현되지만, 각 메모리 주소마다 담을 수 있는 데이터의 크기는 한 바이트이다. C/C++ 프로그래밍 언어의 자료형에 의하면 int 정수나 float 부동소수점은 네 바이트가 필요하므로 이웃하는 총 네 개의 메모리 주소가 데이터를 저장하는데 관여한다. 포인터의 자료형은 이러한 특성을 고려하여 포인터가 저장한 메모리 주소로부터 어디까지 참조해야 완전한 데이터인지 알려주는 역할을 한다. 또한 포인터에 역참조 연산자 *를 사용하여 해당 자료형으로 어떠한 값이 표현되는지 확인도 가능하다 (포인터 정의에 사용된 별표 *와 다른 존재이다).
int variable = 365;
/* 동일한 자료형의 포인터 변수 */
int *ptr1 = &variable;
std::cout << "0x" << ptr1 << std::endl << *ptr1 << std::endl;
// 출력: 0x0073F9E0 (주소)
// 출력: 365 (값)
/* 상이한 자료형의 포인터 변수 */
char *ptr2 = &variable;
std::cout << "0x" << ptr2 << std::endl << static_cast<int>(*ptr2) << std::endl;
// 출력: 0x0073F9E0 (주소)
// 출력: 109 (값)
여기서 0x 접두사는 십육진수 표현법임을 구별짓기 위해 삽입하였다.
| 연산자 | 변수 | 반환 |
|---|---|---|
참조 연산자 & |
일반 변수 | 메모리 주소 |
역참조 연산자 * |
포인터 | 값 |
만일 일반 변수에서 데이터 변동이 발생하였으면 포인터 변수의 역참조에서도 동일한 데이터 변동을 목격할 수 있다. 두 변수가 동일한 메모리 주소를 공유하고 있기 때문이다. 이러한 C/C++ 프로그래밍 언어의 포인터 성질은 매우 중요하게 다루어지는 개념 중 하나이며, 이를 “참조에 의한 호출(call by reference)”이라고 부른다.
널 포인터
널 포인터(null pointer)는 아무런 메모리 주소를 가리키지 않는 포인터이다. C/C++ 프로그래밍 언어에서 포인터 사용은 자칫 “access violation” 메모리 접근 오류 등의 치명적인 문제를 야기시킬 수 있기에, 안전한 포인터 사용을 위해 널 포인터를 nullptr 키워드로 할당한다.
int* ptr = nullptr;
std::cout << "0x" << ptr;
0x00000000
보이드 포인터
보이드 포인터(void pointer)는 지정된 자료형이 없는, 즉 void 포인터이다. 이러한 포인터는 어떠한 자료형이라도 자료형 변환을 통해 메모리 주소를 가리킬 수 있는 장점을 가진다.
int variable = 365;
void *ptr = &variable;
std::cout << *(reinterpret_cast<int*>(ptr));
365
함수 포인터
함수 포인터(function pointer)는 함수 자체를 가리키는 보이드 포인터이다. 이는 배열 자체가 첫 번째 요소 메모리 주소를 가리키는 것과 동일한 맥락이다. 함수 포인터를 사용한 대표적인 예시로 콜백 함수가 있다. 함수 포인터의 선언은 아래와 같으며, 포인터의 자료형은 함수의 자료형과 일치해야 한다. 또한 함수가 갖는 매개변수의 자료형과 개수도 동일해야 한다. 이들을 만족하지 않으면 컴파일 작업 오류가 발생하게 된다.
// 함수 정의
int function(int arg1, float arg2) {
statements;
return 0;
}
int main() {
/* 함수 포인터 선언 및 호출 */
int (*ptr)(int, float) = function;
ptr(1, 3.14);
return 0;
}
참조
참조(reference)는 메모리 주소를 저장하지만, 초기화 이루 메모리 주소 변동이 불가한 상수 포인터에 대응한다. 참조는 단순히 네임 바인딩(name binding)된 변수이다: 자체적으로 할당된 메모리를 갖지 않는 대신에 참조하는 데이터가 할당된 메모리를 그대로 사용하며, 종속된 블록 영역범위를 벗어나면 참조만이 자연스레 사라진다. 이러한 특징에 의해 참조는 보다 안전한 포인터 하위호환으로 사용된다.
-
lvalue는 프로그램이 접근할 수 있는 메모리 주소를 갖는 데이터이다. 즉, 이미 정의된 변수에 별칭을 선언하는 것과 같다. 특히 함수의 매개변수의 참조에 의한 호출을 포인터보다 안전하게 구현하는데 활용된다.int variable = 3; int &ref = variable; std::cout << ref; // 출력: 3 variable++; std::cout << ref; // 출력: 4 -
rvalue 참조
&&rvalue는 프로그램이 접근할 수 있는 메모리 주소가 없거나, 혹은 메모리 주소가 있어도 더 이상의 접근이 불가한 데이터이다. 즉, 임시 데이터를 곧바로 참조하여 불필요한 변수 정의를 배제할 수 있다.int variable = 3; int &&ref = variable + 4; std::cout << ref; // 출력: 7 ref++; std::cout << ref; // 출력: 8
엔디언
엔디언(endianess)이란 컴퓨터가 메모리로부터 데이터를 표현하기 위해 바이트 단위의 정보를 어떻게 정렬할 것인지를 가리킨다. 특히 포인터가 메모리 주소를 접근 및 호출하기 때문에 엔디언의 기본적인 개념 이해는 필요하다고 본다.
아래는 십진수 정수를 십육진수로 변환하여 출력하는 C++ 프로그래밍 언어 코드이다:
int variable = 123456789;
std::cout << "십육진수: 0x" << std::hex << std::setfill('0') << std::setw(8) << variable << std::endl;
std::cout << "포인터: 0x" << &variable << std::endl;
십육진수: 0x075bcd15
포인터: 0x00CFF790
위의 바이트 네 개(0x07, 0x5b, 0xcd, 그리고 0x15)는 각각 int 정수 자료형을 정의하면 할당되는 네 바이트 메모리에 저장된다. 그리고 포인터를 호출하면 전체 메모리 중에서 첫 번째 주소만 호출한다고 이전 부문에서 설명하였다. 그렇다면 한 바이트만 저장할 수 있는 첫 번째 메모리 주소에는 실제로 어떤 값이 들어있는가: 0x07 혹은 0x15인가?
아래는 엔디언의 두 종류인 빅 엔디언(big-endian)과 리틀 엔디언(little-endian)에 대하여 우선 설명한다.
- 빅 엔디언: 최상위 바이트가 첫 주소에 할당된다.
+---------------------------------------------------+ | 0x00CFF790 | 0x00CFF791 | 0x00CFF792 | 0x00CFF793 | |------------+------------+------------+------------| | 0x07 | 0x5b | 0xcd | 0x15 | +---------------------------------------------------+ - 리틀 엔디언: 최하위 바이트가 첫 주소에 할당된다.
+---------------------------------------------------+ | 0x00CFF790 | 0x00CFF791 | 0x00CFF792 | 0x00CFF793 | |------------+------------+------------+------------| | 0x15 | 0xcd | 0x5b | 0x07 | +---------------------------------------------------+
십육진수 0x075bcd15와 0x15cd5b07는 각각 십진수로 변환하면 123456789 그리고 365779719가 나온다. 그러나 결론적으로 프로그램의 각 메모리 주소를 확인해 보면 리틀 엔디언으로 데이터가 저장되고 있음을 확인할 수 있다.
#include <iomanip>
int variable = 123456789;
unsigned char* ptr = reinterpret_cast<unsigned char*>(&variable);
for (int index = 0; index < sizeof(variable); index++) {
std::cout << "0x" << static_cast<void*>(ptr + index) << " : 0x"
<< std::hex << std::setfill('0') << std::setw(2) << static_cast<int>(*(ptr + index)) << std::endl;
}
0x00CFF790 : 0x15
0x00CFF791 : 0xcd
0x00CFF792 : 0x5b
0x00CFF793 : 0x07
비록 숫자를 읽을 때에는 빅 엔디언이 익숙하겠지만, 컴퓨터 메모리에서는 리틀 엔디언으로 데이터를 저장한다는 점을 명시하도록 한다.
클래스
클래스(class)는 객체를 생성하는데 사용자 정의 자료형이다.
객체(object 혹은 instance)는 데이터를 저장할 수 있는 변수와 처리할 수 있는 함수를 하나로 묶은 데이터이다. 객체의 변수와 함수를 통틀어 맴버(member)라고 칭하는데, 이들은 각각 필드(field; 맴버 변수)과 메소드(method; 맴버 함수)라고 불리며 다음과 같이 접근한다.
- 필드:
instance.field- 메소드:
instance.method()현재까지 다룬 내용 중에서 객체에 해당되는 데이터로는 문자열 객체와 배열 및 벡터가 있다.
std::array<int, 4> variable = {0, 3, 5, 9}; std::cout << variable.at(2); // "variable" 배열 객체의 "at()" 메소드를 사용하여 2 번째 인덱스 요소의 값을 반환한다.
일반적으로 클래스는 class 키워드를 사용하여 필드 및 메소드와 함께 정의되는데, struct 혹은 union 키워드로도 정의될 수 있으나 성질 차이가 존재하며 자세한 내용은 PDS에서 다룰 예정이다. 클래스로부터 객체를 생성하는 것을 “객체화(instantiation)”라 부르는데, 이때 클래스에 정의된 맴버들은 캡슐화(encapsulation)되어 다음 특징을 갖는다:
- 변수와 함수가 하나의 객체로 결합된다.
- 우연치 않은 수정을 방지하기 위해 변수 및 함수에 대한 직접적인 접근을 외부로부터 제한할 수 있다.
/* 클래스 정의 */
class CLASS {
public:
/* 필드 맴버 */
int field1 = 2;
float field2 = 3.14;
/* 메소드 맴버 */
int method() {
return field1 * field2;
}
/* 메소드 맴버 (오버로딩) */
int method(int arg) {
return field1 + field2 - arg;
}
};
int main () {
/* 클래스 객체화 */
CLASS instance;
std::cout << instance.field1; // 출력: 2
std::cout << instance.method(1); // 출력: 4
}
여기서 클래스 내에 정의된 메소드는 사실상 인라인 함수이며, 자세한 내용은 맴버 선언을 참고한다.
접근 지정자
접근 지정자(access specifier)는 외부 코드 및 상속으로부터 맴버 접근 권한을 지정한다.
| 키워드 | 설명 |
|---|---|
public |
클래스 외부 코드로부터 맴버 접근이 자유롭다; stuct 및 union 키워드의 기본 접근 지정자이다. |
private |
클래스 내부에서만 맴버 접근이 가능하다; class 키워드의 기본 접근 지정자이다. |
protected |
맴버 접근이 가능한 외부 코드가 해당 클래스로부터 상속된 파생 클래스로 제한된다. |
class와struct키워드의 유일한 차이점은 기본 접근 지정자 뿐이다. 그러므로 클래스를 정의할 때 후자를 사용하는 경우도 흔히 찾아볼 수 있다.
클래스 포인터
클래스 포인터(class pointer)는 클래스를 자료형으로 갖는 포인터이다. 일반 포인터와 동일하게 클래스 뒤에 별표 *를 기입하여 포인터를 정의한다. 단, 포인터로부터 맴버를 접근하는기 위해 포인터 맴버 연산자 ->를 사용해야 하는 차이점이 있다.
/* 클래스 포인터 정의 */
CLASS *ptr = &instance;
std::cout << ptr->field1; // 출력: 2
std::cout << ptr->method(1); // 출력: 4
익명 클래스
익명 클래스(anonymous class)는 불필요한 리소스를 줄이기 위해 재사용이 불가능한 일회용 클래스를 정의한 동시에 객체화한다.
/* 익명 클래스 정의 및 객체화 */
class {
public:
int field1 = 2;
float field2 = 3.14;
int method() {
return field1 * field2;
}
int method(int arg) {
return field1 + field2 - arg;
}
} instance;
생성자
생성자(constructor)는 객체화마다 자동으로 실행되는 특수한 void 자료형 메소드이다. 비록 생성자는 선택사항이지만, 정의한다면 반드시 클래스명과 동일해야 한다. 외부 코드로부터 객체화되기 때문에 생성자를 public 접근 지정자로 설정한다. 흔히 객체화 단계에서 맴버들을 초기화하는 용도로 사용된다.
-
직접 초기화(direct initialization)
생성자의 블록 내에서 각 맴버를 할당 연산자
=로 초기화하는 일반적인 방법이다./* 클래스 정의 */ class CLASS { int field1; float field2; public: /* 생성자: 직접 초기화 */ CLASS(int arg1, float arg2) { field1 = arg1; field2 = arg2; statements; } }; /* 클래스 객체화 */ CLASS intance(2, 3.14); -
목록 초기화(list initailization)
직접 초기화로는 불가능한 상수 맴버의 초기화가 가능하다.
/* 클래스 정의 */ class CLASS { int field1; float field2; public: /* 생성자: 목록 초기화 */ CLASS(int arg1, float arg2) : field1(arg1), field2(arg2) { statements; } }; /* 클래스 객체화 */ CLASS intance(2, 3.14);
생성자는 오버로딩될 수 있어 한 개 이상이 정의될 수 있다. 그 중에서 아무런 전달인자를 받지 않는 생성자를 기본 생성자(default constructor)라고 칭한다.
소멸자
소멸자(destructor)는 객체가 메모리로부터 소멸되기 직전에 자동으로 실행되는 특수한 void 자료형 메소드이다. 비록 소멸자는 선택사항이지만, 정의한다면 접두부에는 물결표 ~와 함께 반드시 클래스명과 동일해야 한다. 외부 코드로부터 소멸되기 때문에 소멸자를 public 접근 지정자로 설정한다.
/* 클래스 정의 */
class CLASS {
public:
/* 소멸자 */
~CLASS() {
statements;
}
};
소멸자는 매개변수를 가질 수 없으므로 오버로딩될 수 없다. 그러므로 클래스는 오로지 하나의 소멸자만 정의할 수 있다.
this 포인터
this 포인터는 객체가 자신의 메모리 주소를 반환하는데 사용된다. 객체의 비정적(non-static) 메소드로부터 자신의 맴버 호출을 this-> 표현식으로 명시적으로 나타낼 수 있어, 흔히 필드 맴버를 매개변수 또는 지역변수와 구분짓는데 활용된다.
/* 클래스 정의 */
struct CLASS {
/* 필드 맴버 */
int field1 = 2;
float field2 = 3.14;
/* 메소드 맴버 */
int method() {
return this->field1 * this->field2;
}
/* 메소드 맴버 (오버로딩) */
int method(int arg) {
return this->field1 + this->field2 - arg;
}
};
맴버 선언
클래스에는 오로지 선언만 되어 외부에 별도로 정의가 필요한 맴버들이 있으며, 대표적으로 맴버 함수와 정적 맴버가 이에 해당한다. 선언을 통해 맴버의 존재성이 클래스에 종속되었다는 것을 알릴 뿐, 실질적인 데이터는 클래스 외부에 위치한다. 때문에 클래스의 sizeof 연산자는 맴버 변수에 의해서만 결정되고, 선언된 맴버들은 클래스 자료형 크기에 어떠한 기여를 하지 않는다.
클래스 내부에 맴버 함수의 정의가 가능한 것은 편의상 제공된 컴파일러 기능일 뿐, 결국 인라인에 의해 실제 코드는 클래스 외부로 옮겨진다.
/* 클래스 정의 */
struct CLASS {
int field1 = 2;
float field2 = 3.14;
/* 메소드 맴버: 선언 */
int method(int arg);
};
/* 메소드 맴버: 정의 */
int CLASS::method(int arg) {
return field1 + field2 - arg;
}
정적 맴버
정적 맴버(static member)는 클래스로부터 생성된 객체의 개수와 무관하게 오로지 하나의 데이터만 존재하여 공유되는 static 키워드로 명시된 맴버이다. 해당 유형의 맴버는 객체화가 필요없이 클래스로부터 직접 호출이 가능하다.
파이썬 프로그래밍 언어와 비교하자면 클래스 속성 및 메소드에 대응한다.
일반 맴버와 달리, 정적 맴버는 클래스 내에서 선언만 되고 외부에서 별도로 정의되어야 한다.
/* 클래스 정의 */
struct CLASS {
/* 정적 필드 및 메소드 선언 */
static int field;
static void method(int arg);
};
/* 정적 필드 및 메소드 정의 */
int CLASS::field = 7;
void CLASS::method(int arg) {
CLASS::field += arg;
}
int main() {
std::cout << CLASS::field; // 출력: 7
/* 클래스 객체화 */
CLASS instance;
CLASS::method(2);
std::cout << instance.field; // 출력: 9
return 0;
}
프렌드 선언
프렌드 선언(friend declaration)는 friend 키워드로 외부 함수 (혹은 메소드, 클래스 등)을 캡슐화로부터 맴버들을 접근할 수 있도록 하는 선언이다. 단순히 맴버 접근 권한이 주어졌을 뿐, 프렌드 선언은 클래스 맴버가 전혀 아니므로 단독적으로 호출되어 사용된다. 캡슐화에 기반한 기술이므로 접근 지정자와 무관하다.
/* 클래스 정의 */
class CLASS {
int field1 = 2;
float field2 = 3.14;
/* 프렌드 함수 선언 */
friend int function(CLASS &instance, int arg);
};
/* 프렌드 함수 정의 */
int function(CLASS &instance, int arg) {
return instance.field1 + instance.field2 - arg;
}
int main() {
/* 클래스 객체화 */
CLASS instance;
std::cout << function(instance, 1); // 출력: 4
}
상수 객체
상수 객체(constant object)는 객체화 이후에 맴버의 데이터 변동이 불가한 객체이다. 일반 메소드 맴버를 접근할 수 없으나, 대신에 const 키워드가 매개변수 선언 이후에 기입되어 필드 맴버의 값을 바꿀 수 없는 상수 메소드(constant method)를 호출할 수 있다.
/* 클래스 정의 */
struct CLASS {
int field1 = 2;
float field2 = 3.14;
/* 상수 메소드 정의 */
int method(int arg) const {
return field1 + field2 - arg;
}
};
int main() {
/* 클래스 객체화: 상수 객체 */
const CLASS instance;
}
상속
상속(inheritance)은 기반 클래스(base class)가 파생 클래스(derived class)에게 필드 및 메소드 맴버를 제공하는 행위이다. 파생 클래스는 접근 지정자를 통해 기반 클래스로부터 상속받는 맴버들의 접근 권한을 설정할 수 있다. 기반 클래스와 파생 클래스에 동일한 이름의 맴버가 존재할 경우, 기반 클래스의 맴버는 파생 클래스에 의해 묻힌다. 파생 클래스는 여러 기반 클래스로부터 동시에 상속받을 수 있다.
기반 클래스의
private맴버는 절대로 상속되지 않으며 접근 불가하다.
| 접근 지정자 | 설명 |
|---|---|
public |
기반 클래스 맴버들의 접근 지정자는 파생 클래스에서도 그대로 유지된다; stuct 및 union 키워드의 기본 접근 지정자이다. |
private |
기반 클래스 맴버들은 파생 클래스에서 private으로 전환된다; class 키워드의 기본 접근 지정자이다. |
protected |
기반 클래스 맴버들은 파생 클래스에서 protected로 전환된다. |
/* 기반 클래스 정의 */
class BASECLASS {
public:
BASECLASS() {
std::cout << "생성자: 기반 클래스" << std::endl;
}
~BASECLASS() {
std::cout << "소멸자: 기반 클래스" << std::endl;
}
int field1 = 3;
std::string field2 = "C++";
int method(int arg1, int arg2) {
return arg1 + arg2;
}
};
/* 파생 클래스 정의 */
struct DERIVEDCLASS
: public BASECLASS {
DERIVEDCLASS() {
std::cout << "생성자: 파생 클래스" << std::endl;
}
~DERIVEDCLASS() {
std::cout << "소멸자: 파생 클래스" << std::endl;
}
std::string field2 = "Hello World!";
bool field3 = true;
int method(int arg1, int arg2) {
return arg1 * arg2;
}
};
int main() {
/* 클래스 객체화 */
DERIVEDCLASS instance;
std::cout << instance.field1 << " " << instance.field2 << " " << instance.field3 << std::endl;
std::cout << instance.method(2, 3) << std::endl;
}
생성자: 기반 클래스
생성자: 파생 클래스
3 Hello World! 1
6
소멸자: 파생 클래스
소멸자: 기반 클래스
상속 맴버 접근
범위지정 연산자 ::를 사용하여 파생 클래스에 묻혀진 기반 클래스의 필드 및 메소드를 호출할 수 있다. 아래는 상속에서 다룬 예시 코드에서 동명의 기반 클래스 맴버를 파생 클래스로부터 호출한다.
/* 기반 클래스 정의 */
class BASECLASS {
public:
BASECLASS() {
std::cout << "생성자: 기반 클래스" << std::endl;
}
~BASECLASS() {
std::cout << "소멸자: 기반 클래스" << std::endl;
}
int field1 = 3;
std::string field2 = "C++";
int method(int arg1, int arg2) {
return arg1 + arg2;
}
};
/* 파생 클래스 정의 */
struct DERIVEDCLASS
: public BASECLASS {
DERIVEDCLASS() {
std::cout << "생성자: 파생 클래스" << std::endl;
field2 = BASECLASS::field2; // 기반 클래스의 field2 필드
}
~DERIVEDCLASS() {
std::cout << "소멸자: 파생 클래스" << std::endl;
}
std::string field2 = "Hello World!";
bool field3 = true;
int method(int arg1, int arg2) {
return BASECLASS::method(arg1, arg2); // 기반 클래스의 method() 메소드
}
};
int main() {
/* 클래스 객체화 */
DERIVEDCLASS instance;
std::cout << instance.field1 << " " << instance.field2 << " " << instance.field3 << std::endl;
std::cout << instance.method(2, 3) << std::endl;
}
생성자: 기반 클래스
생성자: 파생 클래스
3 C++ 1
5
소멸자: 파생 클래스
소멸자: 기반 클래스
다형성
다형성(polymorphism)은 “여러가지의 형태를 가진”이란 사전적 의미를 가지며, 프로그래밍 언어에서는 상황과 용도에 따라 달리 동작하는 것을 가리킨다.
- 컴파일타임 다형성(compile-time polymorphism): 컴파일 시 이루어지는 다형성 (일명 정적 다형성; static polymorphism)
- 런타임 다형성(run-time polymorphism): 프로그램 실행 시 이루어지는 다형성 (일명 동적 다형성; dynamic polymorphism)
이전 장에서 소개한 적이 있는 함수 오버로딩은 컴파일타임 다형성 중 하나이다.
연산자 오버로딩
연산자 오버로딩(operator overloading)은 연산자가 특정 클래스 및 해당 객체에서 어떻게 동작할 지 operator 키워드로 재정의하는 컴파일타임 다형성 중 하나이다. 한 개의 연산자에 전달받은 인자의 자료형 및 개수에 따라 여러 정의가 가능하다.
/* 클래스 정의 */
struct CLASS {
CLASS(int arg) : field(arg) { }
int field;
/* 연산자 오버로딩: + 정의 */
CLASS operator + (const CLASS &arg) {
return CLASS obj(field + arg.field);
}
/* 연산자 오버로딩: [] 정의 */
std::string operator [] (std::string arg) {
return std::string(std::to_string(field) + arg);
}
};
int main() {
CLASS obj1(2), obj2(3);
/* 연산자 사용: + */
CLASS instance(obj1 + obj2);
/* 연산자 사용: [] */
std::cout << instance["!"] << std::endl;
}
5!
함수 오버라이딩
함수 오버라이딩(function overriding)은 상속된 기반 클래스의 맴버 함수 (일명 메소드)를 파생 클래스에서 재정의하는 런타임 다형성이다.
동일한 이름 하에 정의된 여러 함수 중에서 하나를 택하여 실행하는 함수 오버로딩과 전혀 다른 개념이다.
오버라이딩이 되는 기반 클래스의 메소드는 virtual 지정자로 정의된 가상 함수(virtual function)이다. 정의된 가상 함수는 기반 클래스를 객체화하여 곧바로 사용할 수 있으며, 또는 파생 클래스에서 오버라이딩을 하지 않은 채 객체화하여 사용될 수 있다. 단, 상속에서 보여준 예시 코드는 절대 함수 오버라이딩이 아니며 단순히 파생 클래스에 묻힌 것일 뿐이다.
/* 기반 클래스 정의 */
class BASECLASS {
public:
/* 가상 함수 정의 */
virtual void function() {
}
};
/* 파생 클래스 정의 */
class DERIVEDCLASS
: public BASECLASS {
public:
/* 함수 오버라이딩 */
void function() {
}
};
기반 클래스의 가상 함수는 아무런 정의가 없이 =0 구문이 뒤에 붙는 순수 가상 함수(pure virtual function)로 선언될 수 있다. 그리고 최소한 한 개 이상의 순수 가상 함수를 갖는 클래스를 추상 클래스(abstract class)라고 부른다.
/* 추상 클래스 정의 */
class BASECLASS {
public:
/* 순수 가상 함수 선언 */
virtual void function() = 0;
};
순수 가상 함수는 아무런 정의가 없으므로 추상 클래스는 객체화가 불가하며, 오로지 상속 목적으로만 사용된다.
클래스 파일
클래스는 .HPP (또는 .H) 헤더 및 .CPP 소스 파일로 나뉘어 관리될 수 있다. 비주얼 스튜디오의 경우에는 솔루션 탐색기(Solution Explorer)에서 클래스를 추가하려는 프로젝트에 오른쪽 클릭하여 Add > Class...를 선택한다.
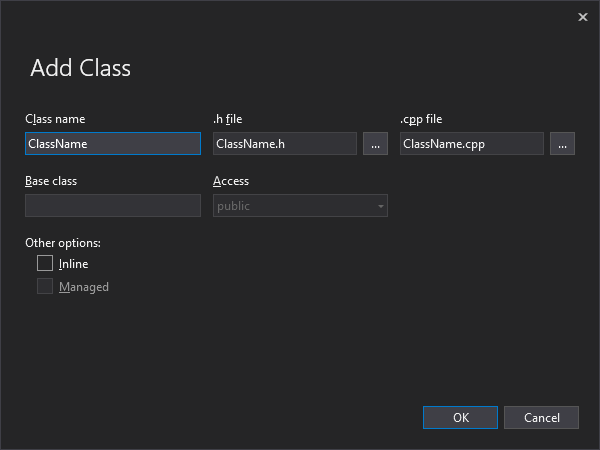
Class Name 란에 입력한 클래스 식별자는 .h file와 .cpp file에 동일한 파일 이름으로 자동입력된다. OK 버튼을 누르면 클래스의 헤더 파일과 소스 파일이 생성된 것을 솔루션 탐색기에서 확인이 가능하다. 생성된 클래스는 #include 지시문으로 클래스 헤더를 불러와 사용할 수 있다.
#include "ClassName.h"
int main() {
// "ClassName" 클래스 파일로부터 클래스를 불러온다.
ClassName instance(1, 3.0);
return 0;
}
클래스 헤더 파일
.HPP (또는 .H) 확장자의 클래스 헤더 파일은 일반적으로 클래스의 필드 및 메소드 맴버의 선언을 담고 있다. 해당 클래스를 사용하려는 타 소스 파일이 오브젝트 파일로 컴파일되는 과정, 즉 링크되기 이전에 클래스의 존재와 구성을 알리는 역할을 한다.
/* "ClassName.h" 헤더 파일 */
class ClassName {
int field1;
float field2;
public:
ClassName(int arg1, float arg2);
~CLASS() { }
int method(int arg);
};
클래스 소스 파일
.CPP 확장자의 클래스 소스 파일은 클래스 헤더 파일에서 선언된 필드 및 메소드 맴버의 정의를 내포한다. 해당 클래스 맴버들의 실질적인 코드가 들어있으나, #include 지시문으로 클래스 헤더를 포함해서 맴버의 선언과 정의를 연동시켜야 한다.
/* "ClassName.cpp" 소스 파일 */
#include "ClassName.h"
ClassName::ClassName(int arg1, float arg2)
: field1(arg1), field2(arg2)
{
statements;
}
ClassName::~ClassName() {
statements;
}
int ClassName::method(int arg) {
return field1 + field2 - arg;
}
사용자 정의 자료형
사용자 정의 자료형(user-defined type)은 흔히 int, float, char 등의 기존하는 자료형으로부터 개발자가 특정 목적을 위해 제작한 새로운 자료형이다. 정의된 자료형은 또 다른 사용자 정의 자료형을 구성하는데 사용될 수 있다. 대표적인 예시로 클래스가 있으나, 본 장은 객체지향 기능들이 결여되고 필드 맴버만으로 구성된 레코드(record)를 지칭하는 PDS(passive data structure 혹은 plain old data, POD; 수동형 자료구조) 관점에서 소개한다.
PDS 클래스는 다음 특징을 지닌다:
집합형(aggregate)이란, 중괄호
{}를 사용하는 집합 초기화를 통해 생성된 데이터이다. 대표적인 집합형으로 배열이 있으며 클래스(일반적으로struct및union)도 아래의 특성을 모두 갖추면 집합형이다.
- 사용자 정의 생성자가 없다.
- 비정적
private그리고protected필드 맴버를 갖지 않는다.private,protected그리고 가상 기반 클래스로부터 상속되지 않다.- 가상 맴버 함수가 없다.
C++ 프로그래밍 언어에서 PDS 클래스 자료형을 별도로 다루는 이유는 C 프로그래밍 언어의 사용자 정의 자료형과 호환되기 때문이다.
구조체
구조체(structure)는 자료형과 무관하게 필드 맴버를 하나의 단일 데이터로 통합시킨 struct 키워드로 정의된 사용자 정의 자료형이다.
/* 구조체 정의: 총 8바이트 활용 */
struct STRUCTURE {
/* 맴버 정의 */
char field1; // 자료형 크기: 1바이트
int field2; // 자료형 크기: 4바이트
};
정의된 구조체로부터 변수를 정의하는 방법은 다음과 같다:
-
C++ 프로그래밍 언어 자료형처럼 변수 앞에 구조체를 명시하고, 중괄호
{}내에 맴버가 선언된 순서대로 데이터를 나열한다./* 구조체 변수 정의 1 */ STRUCTURE variable1 = {'A', 3}; STRUCTURE variable2 = {.field2 = 3, .field1 = 'A'}; -
구조체 변수 선언 이후, 맴버 순서대로 데이터가 나열된 중괄호
{}로 초기화한다./* 구조체 변수 정의 2 */ STRUCTURE variable; variable = {'A', 3}; -
구조체를 정의하는 동시에 구조체 변수를 정의한다.
/* 구조체 및 변수 정의 */ struct STRUCTURE { int field1; char field2; } variable = {'A', 3};
정의된 구조체 변수는 객체 맴버 연산자 .를 통해 구조체 맴버를 호출한다.
std::cout << variable.field1 << std::endl << variable.field2;
A
3
데이터 구조 정렬
위의 예시 코드에서 char (1바이트) 그리고 int (4바이트) 자료형 맴버로 구성된 구조체가 사실상 8바이트 메모리 용량을 차지한다고 언급하였다. 이는 시스템 프로세서 차원에서 메모리 접근성을 위한 데이터 구조 정렬(data structure alignment)이 반영된 결과이다. 여기서 데이터의 메모리 주소가 해당 데이터의 크기인 $n$-바이트 배수로써 자연스럽게 정렬(naturally aligned)되었을 때 하드웨어 성능 효율이 가장 높으며, 이를 “$n$-바이트 정렬”되었다고 부른다.
대체적으로 자료형마다 지정된 정렬 크기는 해당 자료형 크기와 일치한다: char은 1바이트 정렬, short는 2바이트 정렬, int 및 float는 4바이트 정렬이다. 다양한 자료형 맴버들로 구성될 수 있는 구조체의 경우, 메모리 공간 절약보다 접근 효율이 우선시되기 때문에 맴버 자료형이 갖는 가장 큰 정렬 크기의 배수만큼 메모리를 할당받아 맴버들을 정의된 순서대로 정렬시킨다.
-
정렬에 의해 맴버 간 여분이 발생하면 메모리의 연속성을 위해 패딩으로 메워진다.
/* 구조체 크기: 8바이트 */ struct STRUCTURE { //-------------------- Addr: 0x00000000 char field1; // + 1 // char Padding1[3]; // + 3 //-------------------- Addr: 0x00000004 int field2; // + 4 //-------------------- Addr: 0x00000008 }; -
구조체 자체의 정렬을 위해, 구조체 크기는 정렬 크기의 배수이어야 한다. 맨 마지막 맴버의 자료형 크기가 정렬 크기에 미치지 못하면 나머지를 패딩으로 채운다.
/* 구조체 크기: 8바이트 */ struct STRUCTURE { //-------------------- Addr: 0x00000000 int field1; // + 4 //-------------------- Addr: 0x00000004 char field2; // + 1 // char Padding1[3]; // + 3 //-------------------- Addr: 0x00000008 }; -
맴버가 정의된 순서는 구조체 크기에 영향을 줄 수 있다:
char-int-short자료형 순서로 정의된 구조체는 총 12바이트 크기를 갖는다./* 구조체 크기: 12바이트 */ struct STRUCTURE { //-------------------- Addr: 0x00000000 char field1; // + 1 // char Padding1[3]; // + 3 //-------------------- Addr: 0x00000004 int field2; // + 4 //-------------------- Addr: 0x00000008 short field3; // + 2 // char Padding2[2]; // + 2 //-------------------- Addr: 0x0000000C };반면
char-short-int자료형 순서로 정의하면 구조체의 크기는 8바이트로 줄어든다. 비록short자료형이 2바이트 정렬인 관계로char자료형 맴버 사이에 1바이트 패딩이 메워지지만,int자료형에 의한 4바이트 크기의 정렬 경계 내에 두 맴버를 모두 담아낼 수 있기 때문이다./* 구조체 크기: 8바이트 */ struct STRUCTURE { //-------------------- Addr: 0x00000000 char field1; // + 1 // char Padding1[1]; // + 1 short field2; // + 2 //-------------------- Addr: 0x00000004 int field3; // + 4 //-------------------- Addr: 0x00000008 };
구조체 포인터
구조체 포인터(structure pointer)는 구조체를 자료형으로 갖는 포인터이다. 일반 포인터와 동일하게 구조체 뒤에 별표 *를 기입하여 포인터를 정의한다. 단, 포인터로부터 맴버를 접근하는기 위해 포인터 맴버 연산자 ->를 사용해야 하는 차이점이 있다.
/* 구조체 포인터 정의 */
STRUCTURE *ptr = &variable;
ptr->field1 = 'A';
ptr->field2 = 3;
익명 구조체
익명 구조체(anonymous structure)는 불필요한 리소스를 줄이기 위해 재사용이 불가능한 일회용 구조체와 변수를 함께 정의한다.
/* 익명 구조체 및 변수 정의 */
struct {
char field1;
int field2;
} variable = {'A', 3};
공용체
공용체(union)는 자료형과 무관하게 여러 필드 맴버를 하나의 단일 데이터로 통합시킨 union 키워드로 정의된 사용자 정의 자료형이다. 각 맴버마다 데이터를 저장하는 구조체와 달리, 맴버들은 하나의 공용 메모리를 사용한다. 즉, 공용체의 한 맴버에 데이터 변경이 발생하면 나머지 맴버에도 영향을 미친다.
/* 공용체 정의: 총 4바이트 활용 */
union UNION {
/* 맴버 정의 */
char field1; // 자료형 크기: 1바이트
int field2; // 자료형 크기: 4바이트
}
공용체에 할당되는 메모리 크기는 내부 변수 중에서 가장 큰 메모리 용량이 요구되는 자료형과 동일한데, 이는 나머지 내부 변수도 하나의 메모리 공간에서 처리할 수 있도록 하기 위해서이다.
정의된 공용체로부터 변수를 정의하는 방법은 다음과 같다:
-
C++ 프로그래밍 언어 자료형처럼 변수 앞에
union과 함께 공용체를 명시하고, 중괄호{}내에 단일 데이터를 기입한다.만일 구조체처럼 각 맴버에 대하여 값을 지정하면, 맨 마지막에 순서에 할당된 값이 최종 데이터가 된다.
/* 공용체 변수 정의 1 */ UNION variable1 = {365}; UNION variable2 = {.field2 = 365, .field1 = 'A'}; // 결과: variable2 = {321}; -
공용체 변수 선언 이후, 맴버 순서대로 데이터가 나열된 중괄호
{}로 초기화한다./* 공용체 변수 정의 2 */ UNION variable; variable = {365}; -
공용체를 정의하는 동시에 공용체 변수를 정의한다.
/* 공용체 및 변수 정의 */ union UNION { char field1; int field2; } variable = {365};
정의된 공용체 변수는 객체 맴버 연산자 .를 통해 공용체 맴버를 호출한다.
#include <iomanip>
using namespace std;
cout << setw(3) << setfill(' ') << variable.field1 << " (0x" << hex
<< setw(sizeof(variable) * 2) << setfill('0') << static_cast<int>(variable.field1) << ")" << endl;
cout << setw(3) << setfill(' ') << variable.field2 << " (0x" << hex
<< setw(sizeof(variable) * 2) << setfill('0') << static_cast<int>(variable.field2) << ")" << endl;
m (0x0000006d)
365 (0x0000016d)
첫 번째 내부 변수 field1은 1바이트 자료형이므로 한 바이트 0x6D만 처리하여 정수 109에 해당하는 ASCII 문자 ‘m’이 출력되는 반면, 두 번째 내부 변수 field2는 4바이트 자료형이므로 0x0000016D를 전부 처리하여 365 정수가 출력되었다.
공용체 포인터
공용체 포인터(union pointer)는 공용체를 자료형으로 갖는 포인터이다. 일반 포인터와 동일하게 구조체 뒤에 별표 *를 기입하여 포인터를 정의한다. 단, 포인터로부터 맴버를 접근하는기 위해 포인터 맴버 연산자 ->를 사용해야 하는 차이점이 있다.
/* 공용체 포인터 정의 */
UNION *ptr = &variable;
ptr->field1 = 3;
ptr->field2 = 'A';
익명 공용체
익명 공용체(anonymous union)는 불필요한 리소스를 줄이기 위해 재사용이 불가능한 일회용 공용체와 변수를 함께 정의한다.
/* 익명 공용체 및 변수 정의 */
union {
char field1;
int field2;
} variable = {365};
열거형
열거형(enumeration)은 열거된 항목, 일명 열거자(enumerator)들을 정수로 순번을 매기는 enum 키워드로 정의된 자료형이다. 열거자들은 기본적으로 정수 0부터 시작하여 다음 열거자마다 1만큼 증가한다. 열거자에 할당 연산자 =로 정수를 직접 지정하지 않는 이상, 이러한 규칙은 계속 유지된다. 그러나 열거형 정의 이후에 열거자를 추가하거나, 혹은 열거형의 값을 바꾸는 건 불가하다.
/* 열거형 정의 */
enum ENUMERATION {
enumerator1, // = 0
enumerator2, // = 1
enumerator3 = 7, // = 7
enumerator4 // = 8
};
비록 다른 열거형에 정의된 열거자여도 식별자는 전역적으로 유일해야 한다.
enum ENUMERATION1 {
enumerator1,
enumerator2,
};
enum ENUMERATION2 {
enumeration2, // [C2086] 'enumerator2': 재정의: 이전 정의는 '열거자'입니다.
enumeration3,
};
열거형으로부터 정의된 변수는 해당 열거형이 갖는 열거자만 할당받을 수 있다. 만일 타 열거형의 열거자나 범위 외의 정수로 할당하려면 자료형 변환이 필요하다.
/* 열거형 변수 정의 */
ENUMERATION variable = enumerator1;
열거형 클래스
열거형 클래스(enumeration class)는 클래스 성질이 추가된 열거형이며 enum class 혹은 enum struct 키워드로 정의된다. 열거형 클래스 자료형으로 정의된 변수는 오로지 주어진 열거자만을 할당받을 수 있다. 개별 열거자는 열거형 클래스의 정적 필드 맴버인 마냥 호출되는데, 이러한 국부적 영역범위 특성은 서로 다른 열거형 클래스에도 동명의 열거자를 정의할 수 있도록 한다. 때문에 열거형 클래스는 영역 제한 열거형(scoped enumeration)이라고 칭한다.
일반 열거형과 달리 열거자 충돌 문제를 방지할 수 있기 때문에, C++ 프로그래밍 언어는 열거자 클래스의 활용을 적극 권장한다.
/* 열거형 클래스 정의 1 */
enum class ENUMERATION1 {
enumerator1,
enumerator2
};
/* 열거형 클래스 정의 2 */
enum struct ENUMERATION2 {
enumerator2,
enumerator3
};
/* 열거형 클래스 변수 정의 */
ENUMERATION1 variable = ENUMERATION1::enumerator1;
typedef 선언
typedef 키워드는 C/C++ 프로그래밍 언어 내장 자료형 및 사용자 지정 자료형에 별칭(alias)을 선언하여 가독성을 높이는 역할을 한다.
/* unsigned 문자 자료형의 BYTE 별칭 선언 */
typedef unsigned char BYTE;
자료형 별칭 선언
using 키워드는 네임스페이스의 반복적 호출을 생략하는데 사용되기도 하지만, 자료형에 별칭을 선언(type alias declaration)하여 가독성을 높이기도 한다.
자료형 별칭 선언은
typedef선언과 차이가 없으며 사실상 동일한 역할을 수행한다.
using dtypeName = int;
템플릿
템플릿(template)은 자료형을 나중에 지정하여 사용할 수 있는 함수 및 클래스 틀이며 template <> 구문과 함께 정의된다. 유사한 코드를 수행하는 함수 및 클래스를 각 자료형 조합마다 별도로 정의하지 않고 템플릿으로 통합시키므로써 관리가 편해지고 작업효율을 높일 수 있다. 대표적인 예시로 배열 클래스와 벡터 클래스가 있다.
함수 템플릿
함수 템플릿(function template)은 다음과 같은 구문으로 정의된다.
/* 함수 템플릿 정의 */
template <class T, class U>
U function(T arg1, U arg2) {
...
}
정의된 함수 템플릿을 사용하기 위해서는 홑화살괄호 <> 안에 자료형을 지정하여 객체화한다.
/* 함수 템플릿 객체화 */
function<int, float>(1, 3.0)
typename 키워드
typename 키워드는 컴파일러에게 해당 데이터가 자료형임을 명시적으로 알리는 기능을 가진다. 그러나 템플릿 정의에 있어서 typename 키워드는 class 키워드 대안으로 사용되기도 한다.
/* 함수 템플릿 정의: typename 키워드 사용 */
template <typename T, typename U>
U function(T arg1, U arg2) {
...
}
클래스 템플릿
클래스 템플릿(class template)은 다음과 같은 구문으로 정의된다.
/* 클래스 템플릿 정의 */
template <class T, class U>
class CLASS {
public:
CLASS(T arg1, U arg2)
: field1(arg1), field2(arg2) { }
~CLASS() { }
T field1;
U field2;
U method1(T arg) {
return field1 + field2 - arg;
}
};
정의된 클래스 템플릿을 사용하기 위해서는 홑화살괄호 <> 안에 자료형을 지정하여 객체화한다.
/* 클래스 템플릿 객체화 */
CLASS<int, float> instance(1, 3.0);
클래스 템플릿은 클래스가 아니다: 즉, 클래스처럼 헤더 파일과 소스 파일로 나누어서 관리하는 것은 C++ 프로그래밍 언어에서 지원하지 않는다.
템플릿 특수화
특정 자료형 조합에 따라 템플릿을 달리 정의해야 할 경우가 발생한다. 템플릿 특수화(template specialization)은 특정 자료형으로 객체화하였을 시 별도의 정의가 적용되도록 한다.
/* 함수 템플릿 정의 */
template <class T, class U>
U function(T arg1, U arg2) {
statements;
return something;
}
/* 함수 템플릿 특수화: 문자 자료형 전용 */
template <>
bool function<char>(int arg1, float arg2) {
statements;
return something;
}
템플릿 별칭
템플릿 별칭(template alias)은 자료형 별칭 선언과 동일한 개념을 템플릿에 그대로 적용한 것이다. 즉, using 키워드로 기존 템플릿을 다른 별칭으로 호출하여 가독성을 높여준다.
/* 함수 템플릿 정의 */
template <class T, class U>
U function(T arg1, U arg2) {
statements;
return something;
}
/* 템플릿 별칭 */
template <class X>
using aliasName = function<X, X>;
/* 함수 템플릿 객체화: 별칭 사용 */
aliasName<int>(1, 3)
메모리 관리
프로그램을 실행하는데 있어 메모리 관리는 매우 중요한 작업에 해당한다. 그 중에서 동적 메모리 할당은 보다 더 나은 메모리 효율성을 위해 사용되며, 포인터에 대한 충분한 개념적 이해도가 필요하다. 여기서 메모리는 HDD 및 SSD와 같은 보조기억장치가 아닌 RAM이 해당하는 주기억장치를 가리킨다.
스택 영역
스택(stack)은 마지막에 입력된 데이터가 먼저 출력되는 선형적 LIFO(Last-In-First-Out) 데이터 나열 구조이다. 빠른 메모리 접근성의 장점을 가지고 있어 일반적으로 컴파일러에서 데이터 메모리 할당 및 해제를 스택 영역에서 처리한다. 대표적으로 조건문, 반복문, 혹은 함수에서 정의된 지역 변수 등이 블록 외에서는 사용할 수 없다는 특징이 스택 영역 메모리를 활용하고 있음을 의미한다.
스택 영역 메모리의 LIFO 구조는 프로그램 코드를 실행하는데 활용되며, 데이터를 저장하기 위한 용도로는 부적합하다. 지역 변수는 스택을 벗어나면 데이터가 사라지고, 전역 변수는 외부에 쉽게 노출되어 있어 권장되지 않는다.
힙 영역
힙(heap) 영역 메모리는 프로그램이 데이터를 저장할 수 있는 메모리 영역이다. 컴파일러가 코드를 실행하기 위해서 사용하는 영역이 아니며, 프로그램 개발자가 직접 메모리를 할당하고 해제해야 한다. 주소를 찾아가는데 걸리는 시간이 있어 스택 영역보다 접근 속도가 느리지만, 블록의 영향을 받지 않고 프로그램이 종료될 때까지 데이터가 메모리에 남아있을 수 있다는 특징을 갖는다.
힙 영역 메모리는 힙 자료구조와 전혀 상관이 없으며, 사전적으로 “(데이터) 더미”를 뜻하는 순수히 RAM 물리 메모리의 주소공간 영역을 지칭하는 용어이다.
동적 할당
동적 할당(dynamic allocation)은 개발자가 힙 영역에 메모리를 할당하는 작업을 가리킨다. 시스템이 처리하는 메모리가 아니므로 더 이상 사용되지 않는 힙 메모리도 직접 할당을 해제해야 한다. 이러한 작업을 하지 않으면 컴파일된 프로그램이 비정상적으로 동작하거나 최악의 경우 시스템 충돌이 발생한다.
동적 할당과 해제는 new 및 delete 표현식을 통해 이루어진다.
-
값 초기화(value-initialization): 소괄호
()내에 지정된 값으로 초기화된다. -
기본 초기화(default-initialization): 자료형에 따라 기본 초기화는 달리 작용한다.
-
기본 자료형(
int,float,char등)은 초기화되지 않으며 메모리에 잔여하는 쓰레기 값(garbage value)을 갖는다. -
배열의 경우에는 각 요소마다 자료형에 따른 기본 초기화가 작용한다.
/* 동적 할당: 값 초기화 */ int* temp = new int(3); int* buff = new int[2] {1, 7}; std::cout << *temp << std::endl; // 출력: 3 std::cout << buff[0] << buff[1] << std::endl; // 출력: 17 /* 동적 할당: 기본 초기화 */ int* var = new(temp) int; int* arr = new(buff) int[2]; std::cout << *var << std::endl; // 출력: 3 std::cout << arr[0] << arr[1] << std::endl; // 출력: 17 /* 동적 할당 해제 */ delete temp, var; delete[] buff, arr; -
new키워드 접미부의 소괄호()는 동적 할당이 이루어질 메모리 주소를 직접 지정하기 위해 사용된다.
메모리 누수
메모리 누수(memory leak)는 메모리 관리 문제로써 더 이상 사용되지 않는 메모리가 해제되지 않고 계속 잔여하여, 시스템에서 할당할 수 있는 메모리 리소스가 점차 줄어드는 현상이다. 만일 시스템에서 더 이상 할당할 수 있는 메모리가 없으면 시스템 충돌이 발생하는 치명적인 오류가 발생한다. 이를 해결하기 위해 동적 할당된 메모리는 반드시 delete 키워드로 해제하도록 한다.
/* 동적 할당 해제 */
delete ptr1;
delete[] ptr2;
허상 포인터
허상 포인터(dangling pointer)는 참조하려는 메모리 주소가 더 이상 유효하지 않을 때 발생하는 메모리 관리 문제이다. 시스템적으로 메모리 관리를 하는 과정에서 흔히 발생하는 현상이지만, 프로그래밍에서는 동적 할당이 해제된 포인터가 여전히 해당 주소를 가리키고 있어서 나타나는게 대다수이다. 그러므로 영값 주소 nullptr을 할당하여 아무런 주소를 가리키지 않도록 한다.
/* 올바른 동적 할당 해제: 할당 해제 이후 포인터에 영값 할당 */
delete ptr1;
delete[] ptr2;
ptr1 = ptr2 = nullptr;
메모리 함수
C 표준 라이브러리 중에서 문자열 관련 cstring 헤더는 힙 영역 메모리를 처리하는 전용 함수들이 존재한다. 이들은 C/C++ 프로그래밍 언어에서 매우 흔히 사용되는 메모리 함수들의 목록이다.
| 함수 | 예시 | 설명 |
|---|---|---|
memchr() |
memchr(str,'c',num); |
문자열 str에서 num 개의 바이트 내에 문자 'c'의 존재여부를 확인한다.발견될 시 해당 문자의 메모리 주소가 반환되며, 없으면 널 포인터가 반환된다. |
memcmp() |
memcmp(ptr1,ptr2,num); |
포인터 ptr1과 ptr2를 num 개의 바이트 내에서 크기를 비교한다.만일 n번째 바이트에서 처음으로 일치하지 않으면 함수는 *(ptr1 + n)에서 *(ptr2 + n) 차를 반환한다. |
memset() |
malloc(ptr,value,num); |
포인터 ptr로부터 시작해 num 개의 바이트를 value 값으로 채운다. |
memcpy() |
memcpy(ptr1,ptr2,num); |
포인터 ptr2에 있는 num 개의 바이트를 ptr1으로 복사한다; 단, ptr1과 ptr2가 겹쳐서는 안된다. |
memmove() |
memmove(ptr1,ptr2,num); |
포인터 ptr2에 있는 num 개의 바이트를 ptr1으로 복사한다; memcpy()와 달리 ptr1과 ptr2가 겹쳐도 동작하나 상대적으로 느리다. |
예외 처리
예외(exception)는 잘못된 코딩이나 입력으로 인해 프로그램상 실행 불가능 코드 오류이다. 컴파일러에서 걸러지는 오류가 아니기에 정상적인 프로그램이 실행될 수 있으나, 예외가 발생하면 프로그램은 즉시 중단된다. 예외 처리는 실행된 프로그램이 예외로 인해 프로그램 실행이 중단되는 것을 방지하여 안정적으로 실행되는 것을 주목표로 한다.
try-catch 예외 처리문
try-catch 쌍은 예외를 감지하고 발생한 예외 유형에 따라 기입된 코드를 실행하여 처리된다. 예외 처리된 파이썬 프로세스는 도중에 중단되지 않고 계속 실행된다.
-
try문블록 내의 코드에 예외가 발생하는지 확인한다. 예외가 발생하였을 시, 나머지 코드는 실행되지 않고 예외 종류에 따라 해당하는
catch블록으로 넘어간다. -
catch문try블록에서 예외가 발생하면 실행되는 코드를 포함한다. 하나의try블록에 여러catch블록을 사용하여 다양한 예외에 대비할 수 있다. 만일catch블록이 없으면 컴파일 오류가 발생한다 (컴파일 오류는 예외가 아니다).
try {
statements;
}
catch(const std::out_of_range &e) {
// 예외 유형: 범위를 벗어난 요소 접근
}
catch(const std::overflow_error &e) {
// 예외 유형: 산술 오버플로우 발생
}
catch(...) {
// 예외 유형: 모든 유형의 예외 처리
}
throw 키워드
throw 키워드는 내에서 의도적으로 예외를 발생시키는데 사용된다. 자체 제작 함수나 클래스에서 설계되지 않은 방식으로 접근하거나 사용하려는 경우, 해당 문으로 오류를 일으켜서 프로세스 실행을 즉시 중단시키는 용도로 활용된다. 해당 키워드는 try 블록 내부 및 외부에서 동작 방식이 약간 다르다:
-
try블록 내부표현식으로부터 평가된 자료형을
catch예외 처리문으로 전달한다.catch는 전달된 값이 아닌 자료형에 따라 구별하여 예외 처리한다./* try 블록 */ try { throw expression; } catch(int e) { // catch: 정수형 } catch(char e) { // catch: 문자형 } -
try블록 외부예외 처리문 밖에서는
std::terminate()와 동일, 즉 프로그램을 종료한다.
표준 오류 스트림
이전 장의 입력 및 출력 부문에서 가장 흔히 사용되는 출력 스트림인 “표준 출력”을 사용하여 출력하는 std::cout 객체를 소개하였다. C++ 프로그래밍 언어에는 다른 스트림도 존재하는데, 그 중에는 오류 내용을 전달을 목적으로 하는 “표준 오류(standard error)” 스트림의 std::cerr 객체가 존재한다.
스트림(stream)이란 사전적 의미로 “물이 흐르는 개울”을 의미한다. 즉, 컴퓨터 통신 용어에서 스트림은 데이터가 흐르는 길을 의미한다.
std::cerr << "Hello World!"
이렇게 나뉘어진 스트림은 프로그램으로부터 데이터가 장치 혹은 파일로 전송되는데 선택적 제어를 가능케 한다.
파일 관리
여러 데이터를 C++ 프로그래밍 언어로 개발된 프로세스에 전달하거나, 혹은 데이터를 외부로 출력하기 위해 파일을 불러와 read 혹은 write 하여 처리할 수 있다. 본 장은 C 프로그래밍 언어에서 파일을 관리하는 방법에 대하여 소개한다. 외부 파일을 읽고 쓰기 위해서는 다음 헤더 파일이 필요하다.
| 헤더 | 설명 |
|---|---|
fstream |
파일 입출력 스트림 클래스 |
헤더 파일에는 파일에서 프로그램으로 데이터를 전달하는 std::ifstream 클래스와 프로그램에서 파일로 데이터를 건네주는 std::ofstream 클래스가 포함되어 있다.
파일 열기 및 닫기
C++ 프로그래밍 언어에서 파일을 열고 닫으려면 std::ifstream 혹은 std::ofstream 파일 스트림 객체로 open() 메소드와 close() 메소드를 사용한다.
#include <fstream>
/* 파일 열기 */
std::ifstream file;
file.open("filename.txt");
/* 동일:
std::ifstream file("sample.txt");
*/
/* 파일 닫기 */
file.close();
close() 메소드로 더 이상 사용하지 않는 파일을 닫아주는 습관은 리소스 낭비를 줄여주므로 매우 중요하다. 예외가 발생하여도 정상적으로 파일을 닫을 수 있도록 예외 처리문 혹은 is_open() 메소드를 활용한 조건문을 사용할 것을 권장한다.
절대경로 및 상대경로
컴퓨터에는 두 종류의 경로 탐색법이 존재한다.
- 절대경로(absolute path): 시스템의 루트경로(예. 윈도우의
C:\혹은 리눅스의/)로부터 시작하여 탐색하는 방식이다. - 상대경로(relative path): 실행되고 있는 프로세스의 현 위치를 기준으로 경로를 탐색하는 방식이다.
경로를 지정할 때에는 백슬래시 두 개 \\로 폴더 및 파일을 구분한다. 하나만 사용하면 탈출 문자가 되어 원치 않은 텍스트 연산이 수행될 수 있다.
파일 읽기
C++ 프로그래밍 언어에서 텍스트 기반 파일을 열었으면 몇 가지의 방법으로 파일 내용을 읽을 수 있다. 파일 읽기에는 std::ifstream 클래스를 사용한다. 다음은 예시 텍스트 파일과 함께 일부 파일을 읽어오는 방법을 소개한다.
<filename.txt>
Hello World!
65 3.14159
-
추출 연산자
>>: 빈 공간(예. 띄어쓰기, 줄바꿈 등)을 기점으로 나누어서 텍스트를 불러온다.#include <fstream> std::string variable1, variable2, variable3; double variable4; std::ifstream file("path\\filename.txt"); file >> variable1; // variable1 = "Hello" file >> variable2; // variable2 = "World!" file >> variable3; // variable3 = "65" file >> variable4; // variable4 = 3.14159 file.close(); -
std::getline()함수: 줄바꿈을 기점으로 나누어서 텍스트를 불러온다;<string>헤더 필요.#include <fstream> #include <string> std::string variable1, variable2; std::ifstream file("path\\filename.txt"); std::getline(file, variable); // variable1 = "Hello World!" std::getline(file, variable); // variable2 = "65 3.14159" file.close();
그 외에도 여러 방법이 있으며, 파일 스트림 객체의 eof() 메소드로 프로그램이 파일 전체를 읽었는지 여부를 확인할 수도 있다.
여기서 EOF란, End-of-File의 약자로 파일의 끝에 도달하였으면 트리거되는 데이터이다.
파일 쓰기
C++ 프로그래밍 언어에서 텍스트 기반 파일을 열었으면 아래의 삽입 연산자 <<를 사용하여 파일 내용을 작성할 수 있다. 파일 쓰기에는 std::ofstream 클래스를 사용한다.
#include <fstream>
std::ofstream file("filename.txt");
file << "Hello World!" << std::endl;
file << 65 << " " << 3.14159
file.close();
<filename.txt>
Hello World!
65 3.14159
파일 생성
파일 쓰기 모드는 이미 존재하는 파일 내용을 수정하는 것 외에도 파일을 새롭게 생성할 수 있다. 단순히 파일 경로 및 이름을 지정하므로써 새로운 파일을 생성할 수 있다.
#include <fstream>
std::ofstream file("path\\NEW_filename.txt");
file << "New file created!" << std::endl;
file.close();
전처리기
C++ 프로그래밍 언어가 컴파일되기 전에 전처리기에서 #include와 같은 전처리기 지시문을 우선적으로 처리한다. 전처리기 지시문은 C++ 프로그래밍 언어 컴파일러 설정 및 프로그래밍의 편리성을 제공한다. 본 장에서는 일부 유용한 전처리기 지시문에 대하여 소개한다.
매크로 정의
매크로(macro)란 식별자가 있는 코드 조각이다. 코드 조각은 숫자나 문자와 같은 간단한 데이터가 될 수 있으며 (객체형식 매크로; object-like macro), 전달인자를 받는 표현식이나 문장이 될 수도 있다 (함수형식 매크로; function-like macro). 매크로는 #define 지시문으로 정의되며, 각 매크로에 해당하는 데이터 및 표현식이 소스 코드에 대체된다. 정의된 매크로는 #undef 지시자로 제거할 수 있다.
#define SOMETHING 7 // 객체형식 매크로
#define ANYTHING(x, y) (x * SOMETHING - y) // 함수형식 매크로
std::cout << ANYTHING(2, 3);
/* 결과:
std::cout << (2 * 7 - 3);
*/
#undef SOMETHING
#undef ANYTHING
한 번 정의된 매크로는 런타임 도중에 변경이 불가하다. 정의된 매크로는 마치 전역 변수인 마냥 헤더 파일에서 #include와 같은 포함 지시문을 통해 다른 스크립트에서도 사용할 수 있다.
컴파일러에는 공통된 표준 매크로 및 컴파일러마다 전용 매크로가 내장되어 있다.
- Visual C++: Microsoft Docs - 미리 정의된 매크로
- GCC: GCC Online Documentation - Predefined Macros
- 그 외: SourceForge Wiki
쉼표 연산자
쉼표 연산자(comma operator)는 앞에 있는 표현식을 평가하되 반환되지 않고, 뒤에 있는 표현식이 평가되어 반환된다. 흔히 매크로 정의를 간결하게 하기 위해 사용된다. 아래의 예시 코드에 의하면 먼저 할당 연산자로 value1은 4가 되고, 이후에 증가 연산자에 의해 5가 된다.
int value1 = 1, value2 = 3;
int variable = (value1 += value2, ++value1);
std::cout << variable;
5
조건 포함문
조건 포함문(conditional inclusion)은 조건여부에 따라 컴파일 시 특정 범위의 코드를 포함시킬 것인지 배제할 것인지 결정한다.
#if SOMETHING > value
...
#elif SOMETHING < value
...
#else
...
#endif
비록 조건 포함문이 일반 조건문의 키워드와 유사할지라도 절대 if 및 else 조건문을 대체하기 위해 사용되지 말아야 한다.
매크로 조건
조건 포함문은 매크로의 정의 여부를 판단할 수 있다.
// 만일 64비트 ARM 혹은 x64 아키텍쳐로 컴파일 할 경우...
#ifdef _WIN64
...
#endif
// 만일 64비트 ARM 혹은 x64 아키텍쳐로 컴파일되지 않은 경우...
#ifndef _WIN64
...
#endif
Pragma 지시문
Pragma 지시문(pragma directive)은 컴파일러의 기능과 옵션을 설정하기 위해 사용되는 전처리기 지시문이다. 개발사마다 제작한 컴파일러는 기술적 성능이 각각 다르기 때문에 pragma는 비공통적인 컴파일러 특정 전처리기 지시문이다.
Pragma란 용어는 pragmatic의 줄임말로, 사전적 의미로는 “실용적인”을 뜻한다. 이는 실질적 컴파일러 동작 및 처리 방식에 관여한 것을 보아 붙여진 용어라고 판단된다.
- Visual C++: Microsoft Docs - Pragma Directives and the Pragma Keyword
- GCC: GCC Online Documentation - Pragmas
본 장은 마이크로소프트의 비주얼 스튜디어에서 제공하는 Visual C++ 컴파일러의 pragma 지시문을 위주로 다룬다.
#pragma once
#pragma once는 컴파일 작업 시 #include 지시문을 통해 중복 포함된 헤더 파일을 한 번만 포함시키는 pragma 지시문이다.
#pragma once
결과적으로 하나의 소스 파일에 헤더 파일이 중복적으로 포함이 되는 것을 제한하므로써 정의가 반복되는 현상을 막을 수 있는데, 이러한 기능을 헤더 중복 방지(include guard)라고 부른다. 추가적으로 #pragma once 지시문을 사용하면 처리하는 헤더 파일 횟수가 줄어들어 컴파일 작업 시간도 함께 줄이게 된다.
아래의 코드는 #pragma once 지시문을 사용하지 않고 헤더 중복 방지 기능을 구현하는 방법이다.
/* 헤더 파일: "header.h" */
#ifndef HEADER_FILE
#define HEADER_FILE
#endif /* HEADER_FILE */
만일 header.h 헤더 파일이 아직 처리되지 않았으면 컴파일러는 처음으로 HEADER_FILE 매크로를 정의한다. 그러나 헤더 파일을 다시 한 번 마주하였을 시, HEADER_FILE이 이미 정의되어 있기에 매크로 조건에 의해 컴파일러는 헤더 파일을 처리하지 않는다.
#pragma region
컴파일 작업에는 직접적인 영향을 주지 않지만, #pragma region 및 #pragma endregion 쌍은 가독성을 위해 비주얼 스튜디오에서 지정된 코드 부분을 한 줄로 압축하거나 펼치는 기능을 제공한다.
#pragma region REGIONNAME
...
#pragma endregion REGIONNAME
라이브러리
본 문서는 main() 함수를 가지는 하나의 메인 스크립트만을 사용하여 프로그램을 빌드하였다. 프로젝트 규모가 커지면 두 개 이상의 스크립트를 사용하거나 컴파일된 라이브러리를 불러와 관리하는 방안도 고려해야 한다. 본 장은 프로젝트 내의 스크립트 간 데이터나 함수를 주고받을 수 있도록 구축하는 방법과 이에 대한 설명을 제공한다.
포함 지시문
포함 지시문(inclusive directive) #include는 전처리기 지시문 중 하나로 대표적으로 stdio.h와 같은 헤더 파일을 불러오는데 매번 사용된다. 헤더 파일에 선언된 기능들을 불러오는데 사용된 #include 지시문의 정확한 기능은 헤더 파일의 전체 코드를 지시문이 위치한 곳에 그대로 삽입한다.
헤더와 소스 파일 나누기
문서 초반에 처음 언급된 소스(source) 파일과 헤더(header) 파일의 역할을 다시 정리하면 전자는 데이터나 함수의 정의, 그리고 후자는 데이터나 함수의 선언이 위주인 스크립트이다. 다만, 진입점인 main() 함수는 선언부가 없다는 점을 고려하면 메인 스크립트를 다음과 같이 구성할 수 있다.
/* 헤더 파일: main.h */
#include <iostream>
int variable;
void function(int, float);
/* 소스 파일: main.cpp */
#include "main.h"
int main() {
variable = 'A';
std::cout << variable << std::endl;
function(1, 3.14);
return 0;
}
void function(int arg1, float arg2) {
std::cout << arg1 + arg2 << std::endl;
}
A
4.140
위의 소스 파일의 헤더 파일 포함은 결과적으로
#include지시문으로 인해 다음과 같이 표현된 것과 동일하다./* #include "main.h" 코드 시작 */ #include <iostream> int variable; void function(int, float); /* #include "main.h" 코드 끝 */ int main() { variable = 'A'; std::cout << variable << std::endl; function(1, 3.14); return 0; } void function(int arg1, float arg2) { std::cout << arg1 + arg2 << std::endl; }
extern 키워드
extern 키워드는 변수를 정의 없이 선언만 한다. C++ 프로그래밍 언어의 변수를 처음 소개하였을 때 선언은 정의와 동일하다고 하였으나, 특수한 경우로써 extern 키워드가 있다고 함께 설명하였다. 그러므로 이번 내용은 선언(declaration)과 정의(definition)의 명확한 차이를 짚고 넘어가야 한다.
변수 및 함수를 정의하면 해당 데이터를 위한 메모리가 할당되므로 한 번만 정의될 수 있다. 반면, 선언은 메모리 할당 없이 컴파일러에게 변수 및 함수의 존재만 알려줄 뿐이므로 데이터 메모리가 할당되지 않아 여러 번 선언이 가능하다. 이러한 특징이 스크립트 간 데이터 및 함수 공유에 매우 중요한 역할을 한다.
/* 헤더 파일: module.h */
#include <iostream>
// "extern" 키워드로 변수 "variable" 선언
extern char variable;
void function(int, float);
/* 소스 파일: module.cpp */
#include "module.h"
// 본격 변수 "variable" 정의
char variable = 'A';
void function(int arg1, float arg2) {
std::cout << arg1 + arg2 << std::endl;
}
/* 메인 스크립트 */
#include <iostream>
#include "module.h"
int main() {
std::cout << variable << std::endl;
function(1, 3.14);
return 0;
}
A
4.140
만일 module.h 헤더 파일에서 extern 키워드를 사용하지 않았으면 변수는 정의가 되어버린다. 오로지 한 번만 정의될 수 있는 변수가 module.cpp 소스 파일과 메인 스크립트에서 중복되어 정의되므로 결국 재정의(re-definition) 문제로 컴파일 오류가 발생한다.
extern 키워드를 사용하면 변수는 여러 번 선언이 가능하다. module.cpp 소스 파일과 메인 스크립트에서 중복 선언은 컴파일 작업에 아무런 문제를 야기하지 않는다. 허나, 선언된 변수를 사용하기 위해서는 단 한 번의 정의가 반드시 필요하다. 이러한 이유로 module.cpp에 char variable = 'A'; 정의가 존재하는 것이며, 메인 스크립트에서는 variable 전역 변수의 값을 그대로 출력할 수 있게 된다.
라이브러리
라이브러리(library)는 함수 기능 및 데이터 호출을 제공하는 이진파일이며 main() 진입점을 갖지 않는다. 본 문서도 여태까지 C++ 프로그래밍 언어의 표준 라이브러리인 libc++(Visual C++ 컴파일러에서는 stl)을 iostream 헤더 파일로 불러와 사용하고 있었다. 마찬가지로 소스 코드를 라이브러리로 만들어 헤더 파일과 함께 배포하면 누군든지 라이브러리의 함수 기능과 데이터를 활용할 수 있다. 또한 이진파일 컴파일되었기 때문에 저장공간 절약과 소스 코드 유출 방지를 함께 꾀할 수 있다.
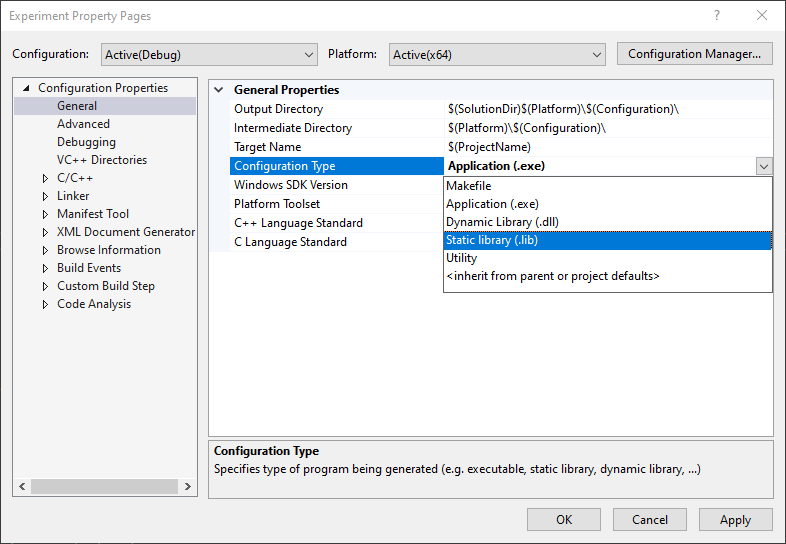
라이브러리는 크게 두 종류로 나뉘어진다:
-
정적 라이브러리(static library)
정적 라이브러리(
.LIB혹은.A확장자)는 프로그램 프로젝트를 컴파일하면 라이브러리도 함께 내포된다. 그러면 프로그램 하나가 완전체이기 때문에 외부 의존도가 낮아지는 장점을 가지지만, 프로그램 용량이 커지고 프로그램을 업데이트하려면 전부 새로 컴파일해야 하는 단점이 있다. -
동적 라이브러리(dynamic library)
동적 라이브러리(
.DLL혹은.SO)는 프로그램에 내포되지 않고 별개의 파일로 존재하기 때문에 프로그램 용량이 작아지고 업데이트가 필요한 라이브러리만 교체하면 되지만, 프로그램의 외부 의존도가 높아져 라이브러리를 찾지 못하면 치명적인 문제를 야기할 수 있다.
C++ 프로그래밍 언어에서는 라이브러리 생성이 어렵지 않다; 본 장에서 예시로 들은 module.cpp를 컴파일하는 게 전부이다. 헤더 파일에서 이미 함수에 대한 선언이 모두 되어있기 때문에 컴파일러는 라이브러리 내에 있는 함수들의 존재를 알아차리고 있다. 그리고 프로그램을 컴파일 혹은 실행하면서 라이브러리를 호출하여 원하는 함수를 사용한다.
extern "C" 한정자
extern "C" 한정자는 C++ 프로젝트를 라이브러리로 컴파일 할 때 사용되며, 주요 목적은 C 프로그래밍 언어 호환성이다.
C 프로그래밍 언어와 C++ 프로그래밍 언어에는 몇 가지 차이점이 있으며, 대표적으로 함수 오버로딩 지원 여부가 있다. 함수 오버로딩 여부는 소스 코드를 이진 라이브러리 파일로 컴파일한 이후에도 영향을 준다. C++ 언어는 하나의 함수명에 여러 조합의 전달인자 개수와 자료형을 가질 수 있기 때문에, 이들을 구별하기 위한 조치로 함수 이름과 전달인자 정보를 함께 사용한다. 그러나 C 언어는 하나의 함수명에 단 한 조합의 전달인자 개수와 자료형만을 가질 수 있으므로 함수 이름만으로 구분이 가능하다. 라이브러리 호출 형식이 다른 두 언어를 지원하기 위해 extern "C" 한정자는 전달인자 정보를 제외시키므로써 C/C++ 프로젝트를 무조건 C 라이브러리로 컴파일한다.
반대로 extern "C"는 C++ 프로젝트에서 C 라이브러리를 불러오는데에도 사용된다. 라이브러리 내에 함수를 전달인자 정보 없이 함수명만으로 C++ 코드로 가져오도록 한다. 그러므로 extern "C"는 라이브러리 컴파일만이 아닌 호출에서도 필수적이다.
헤더 파일에 extern "C" 한정자를 사용하였을 시, 소스 파일에는 해당 한정자를 필요로 하지 않는다. 그러므로 C++ 프로젝트로 라이브러리를 컴파일 및 호출할 시 헤더 파일을 아래와 같이 선언한다.
/* 헤더 파일: module.h */
extern "C" void function(int, float);
만일 여러 함수 및 변수를 한꺼번에 C 언어에 연동시키려면 아래와 같이 블록을 사용할 수 있다.
/* 헤더 파일: module.h */
extern "C" {
void function(int, float);
}
반면, C 프로젝트에서는 extern "C" 한정자는 무의미하다. C++ 프로젝트에서만 한정자를 활성시키려면 전처리기와 매크로를 활용하여 아래 코드처럼 작성하기도 한다.
/* 헤더 파일: module.h */
#ifdef __cplusplus
extern "C" {
#endif
void function(int, float);
#ifdef __cplusplus
}
#endif
랜덤 발생기
게임 개발이나 통계적 모델링 프로그램에서는 무작위성이 요구되기도 한다. 랜덤 숫자 발생기를 작성하기 위해서는 다음과 같은 헤더 파일이 필요하다.
| 헤더 | 설명 |
|---|---|
cstdlib.h |
랜덤 발생기, 통신 등 여러 종류의 범목적 함수를 포함하는 헤더 파일이다. |
rand() 함수
rand() 함수는 숫자를 무작위로 생성하지만, 프로그램을 실행할 때마다 항상 동일한 숫자가 생성되는 의사(pseudo) 랜덤 발생기이다.
#include <cstdlib>
for (int index = 0; index < 3; index++) {
std::cout << rand() << " ";
}
// >> 출력: 1 7 4 (첫 번째 실행)
// >> 출력: 1 7 4 (두 번째 실행)
// >> 출력: 1 7 4 (세 번째 실행)
srand() 함수
srand() 함수는 무작위로 숫자를 생성하지 않지만 무작위성을 결정하는 시드(seed)를 전달인자로 받는다. 입력되는 시드에 따라 부여되는 무작위성은 전혀 달라진다. 하지만 난수를 생성하기 위해서는 rand() 함수가 여전히 필요하다. 그러므로 srand() 함수가 있음에도 불구하고 매 프로그램 실행 시 동일한 랜덤 숫자가 발생된다.
#include <cstdlib>
srand(98); // 랜덤 시드: 정수 98 사용
for (int index = 0; index < 3; index++) {
std::cout << rand() << " ";
}
// >> 출력: 8 7 5 (첫 번째 실행)
// >> 출력: 8 7 5 (두 번째 실행)
// >> 출력: 8 7 5 (세 번째 실행)
진정한 랜덤 발생기
매 프로그램마다 달라지는 무작위성을 보장하기 위해서는 매번 새로운 시드를 제공해야 한다. 가장 대표적인 방법으로 날짜와 시간을 정수형으로 표현하는 타임스탬프(timestamp)를 시드로 사용하는 것이다. 타임스탬프는 ctime.h 헤더 파일에 있는 time() 함수를 통해 얻을 수 있다. 현재 타임스탬프는 숫자 0을 전달인자로 건네주면 된다.
#include <cstdlib>
#include <ctime>
srand(time(0)); // 랜덤 시드: 타임스탬프 사용
for (int index = 0; index < 3; index++) {
std::cout << rand() << " ";
}
// >> 출력: 4 0 0 (첫 번째 실행)
// >> 출력: 3 9 2 (두 번째 실행)
// >> 출력: 5 7 1 (세 번째 실행)