소개
C# (한국어:씨샵) 프로그래밍 언어는 자바(Java) 언어를 대응하기 위해 마이크로소프트에서 개발한 객체지향 프로그래밍 언어이다. 자바와 상당한 유사점을 가지면서 C/C++ 언어로부터 이질감이 없도록 설계되었다. 또한 .NET (한국어: 닷넷) 프레임워크라는 방대한 데이터 라이브러리를 접속하고 사용할 수 있어 개발의 편리성을 제공하는 장점을 가진다.
.NET
참조: 컴파일러 vs. 인터프리터
.NET(혹은 .NET Core)은 마이크로소프트에서 개발한 오픈소스 소프트웨어 프레임워크이다. 국제표준기구 ISO와 ECMA에서 표준으로 채택된 공통 언어 기반(Common Language Infrasturcture; CLI)이 적용되어 운영체제 및 아키텍쳐가 다르더라도 크로스 플랫폼(cross-platform)을 지원해야 하며 여러 고급 프로그래밍 언어을 사용할 수 있다. 그 중에서 C# 언어가 .NET이 지원하는 프로그래밍 언어 중 하나이며 윈도우 NT, macOS, 그리고 리눅스 운영체제에서 사용할 수 있다.
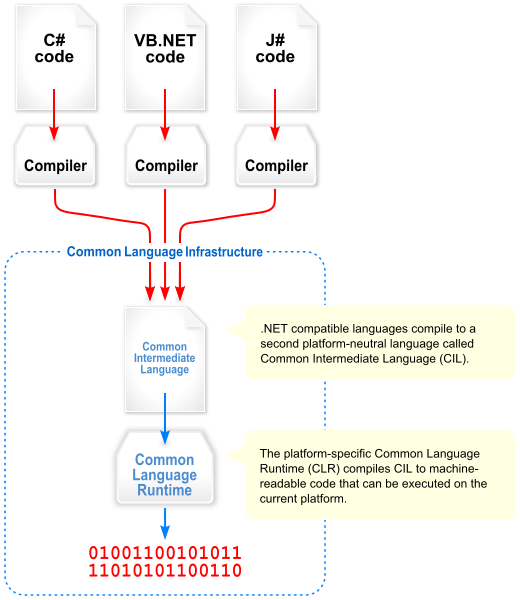
프레임워크는 CoreFX(이전 명칭: FCL) 그리고 CoreCLR(이전 명칭: CLR)로 구성되어 있으며 아래의 표는 이들의 역할을 간략하게 설명한다:
| 구성요소 | 설명 |
|---|---|
| 프레임워크 클래스 라이브러리 (Framework Class Library; FCL) | .NET 프로그램을 개발하는데 필요한 표준 라이브러리를 제공한다. |
| 공통 언어 런타임 (Common Language Runtime; CLR) | JIT 컴파일러를 통해 .NET 프로그램을 컴파일 및 실행한다. |
어셈블리
C/C++ 프로그래밍 언어는 컴파일러(예. Visual C++, Clang, GCC 등)가 소스 코드로부터 .exe 실행 파일 혹은 .dll 라이브러리 파일과 같은 컴퓨터가 읽을 수 있는 이진코드 기계어로 변환한다.
C/C++ 프로그램은 실행되기 전에 컴퓨터가 읽을 수 있도록 완전히 컴파일된다: 그러므로 해당 작업을 AOT(ahead-of-time) 컴파일이라고 부른다.
반면, .NET 컴파일러 플랫폼(일명 “로즐린”; Roslyn)은 소스 코드에서 이진코드가 아닌 공통 중간 언어(Common Intermediate Language; CIL) 파일을 생성한다. 여기서 CIL은 바이트코드(bytecode)이며, 컴퓨터가 읽을 수 있는 기계어는 아니지만 아키텍처 독립 언어로 크로스 플랫폼 지원이 가능한 핵심 요소이다.
바이트코드 파일은 컴퓨터가 읽을 수 있는 기계어로 번환하기 위해 프로그램 런타임(runtime) 시 JIT (just-in-time) 컴파일 작업이 추가로 요구된다.
어셈블리(assembly)는 C# 프로그래밍 언어에서 바이트코드 파일을 의미한다. C/C++ 프로그래밍 언어와 같이 어셈블리에도 .exe 프로세스 어셈블리(process assembly)와 .dll 라이브러리 어셈블리로 나뉘어진다. 하지만 어셈블리는 이진파일이 아니므로 C#은 .NET (정확히는 CoreCLR) 없이 프로그램을 실행할 수 없다.
.NET 프레임워크
.NET 프레임워크(.NET Framework)는 .NET 이전에 활발히 사용되던 데스크탑 전용 윈도우 NT에서만 사용할 수 있는 프레임워크이다. 비록 2020년 11월부로 .NET Core가 주요 프레임워크로 전환되었으나, .NET 프레임워크로 개발된 프로그램이 상당히 많아 여전히 지원되고 있다.
객체지향 프로그래밍
C# 프로그래밍 언어는 “객체”라는 데이터를 위주로 프로그램을 개발하는 객체지향 프로그래밍(object-oriented programming; OOP) 언어이다. 객체와 클래스는 OOP에서 가장 핵심되는 개념으로 반드시 알아야 하며, 다음은 이들에 대한 간략한 설명이다.
-
객체 (object 혹은 instance): 값을 저장하는 데이터(일명 필드; field) 및 동작을 수행하는 코드(일명 메소드; method)의 묶음
-
클래스 (class): 객체를 생성하는 자료형
-
맴버 (member): 구성원, 즉 객체와 클래스의 경우에는 필드와 메소드
설치
본문은 윈도우 NT 운영체제에서 C# 프로그래밍 언어 소스 코드 편집, 프로그램 빌드, 그리고 디버깅 기능을 제공하는 통합 개발 환경(integrated development environment; IDE) 설치 및 프로젝트 생성 단계를 소개한다. 프레임워크는 .NET 프레임워크가 아닌 .NET Core 위주로 진행한다.
비주얼 스튜디오
비주얼 스튜디오(다운로드)는 마이크로소프트에서 개발한 IDE이며 .NET을 제공한다. 비주얼 스튜디오의 세 가지 에디션 중에서 무료 버전인 커뮤니티 에디션으로도 충분하다. 통합 개발 환경인 만큼 C/C++이나 자바스크립트 등 다른 프로그래밍 언어도 함께 지원하므로 여러 종류의 구성요소를 제공한다. C# 프로그래밍 언어 개발을 위해서면 “.NET desktop development”를 선택한다.
만일 한국어 지원을 원한다면 “Language packs” 탭에서 한국어를 함께 선택한다.
비주얼 스튜디오를 실행하면 아래와 같은 시작화면이 나타난다. 새로운 프로젝트를 생성하려면 오른쪽 하단의 “Create a new project” 버튼을 클릭한다.
C# 프로그래밍 언어로 다양할 어플리케이션을 만들 수 있어, 비주얼 스튜디오에서도 다양한 종류의 프로젝트 생성 선택지를 제공한다. 그 중에서 간단한 콘솔 어플리케이션을 위한 C# 프로그래밍 언어 프로젝트 생성은 아래의 절차를 따른다:
-
프로그래밍 언어를 C#으로 선택하여 “Console App (.NET Core)”을 클릭한다.
-
프로젝트 및 솔루션 이름을 선정한다. 여기서 프로젝트란, 소스 코드와 컴파일러 설정 등의 실질적인 코딩 내용을 관리하는
.csproj확장자 파일이며, 솔루션은 여러 프로젝트 파일을 하나의 폴더처럼 관리하는.sln확장자 파일이다. 비주얼 스튜디오에서 프로젝트는.sln파일로 열기를 권장한다.
-
비주얼 스튜디오에서 알아서 준비한 프로젝트를 그대로 사용한다. 만일 아무것도 없는 빈 프로젝트를 생성하려면 여기를 참조한다.
비주얼 스튜디오는 두 가지의 실행 방법이 있다: 일반 실행 모드(Ctrl+F5)와 디버그 모드(F5)이다. 디버그(debug)는 프로그램에 발생한 문제를 해결하는 행위로, IDE에서 각 줄의 코드마다 어떠한 변화가 생겼는지 혹은 얼만큼의 시스템 리소스를 소모하는지 등을 확인할 수 있는 정보를 제공한다. 디버깅 목적이 아니면 일반 실행 모드를 사용하는 것을 권장한다.
.NET 6 C# 콘솔 프로젝트
다음은 C# 9.0 업데이트를 기점으로 비주얼 스튜디오에서 C# 콘솔 프로젝트 생성시 제공되는 기본 소스 코드를 비교한다.
-
C# 9.0 이전 (초창기 .NET 5 또는 이전 버전)
프로그램이 시작되는
Main()진입점이 C# 프로젝트 이름의 네임스페이스 안에 위치한다.using,class,static키워드 등이 무슨 역할을 하는지 설명이 필요하며, 객체지향 프로그래밍의 성격이 잘 드러나는 정석적인 코드이다.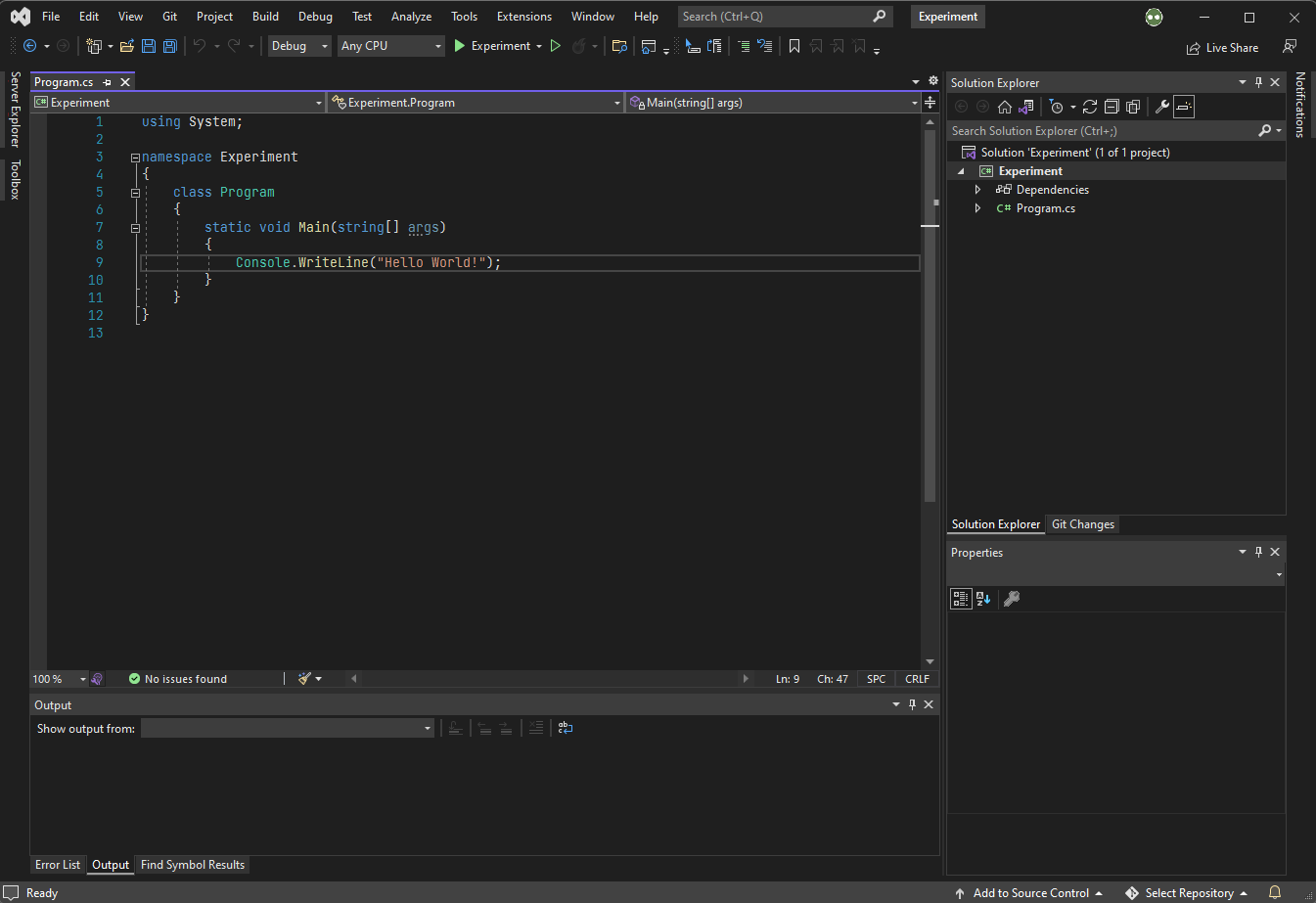
-
C# 9.0 이후 (현재 .NET 5 또는 이후 버전)
프로그램이 시작되는
Main()진입점은 컴파일러가 알아서 전역 네임스페이스에 생성한다. 최상위 문장(top-level statements)에 의해 깔끔하고 간편하지만 암묵적인 규칙들이 존재한다.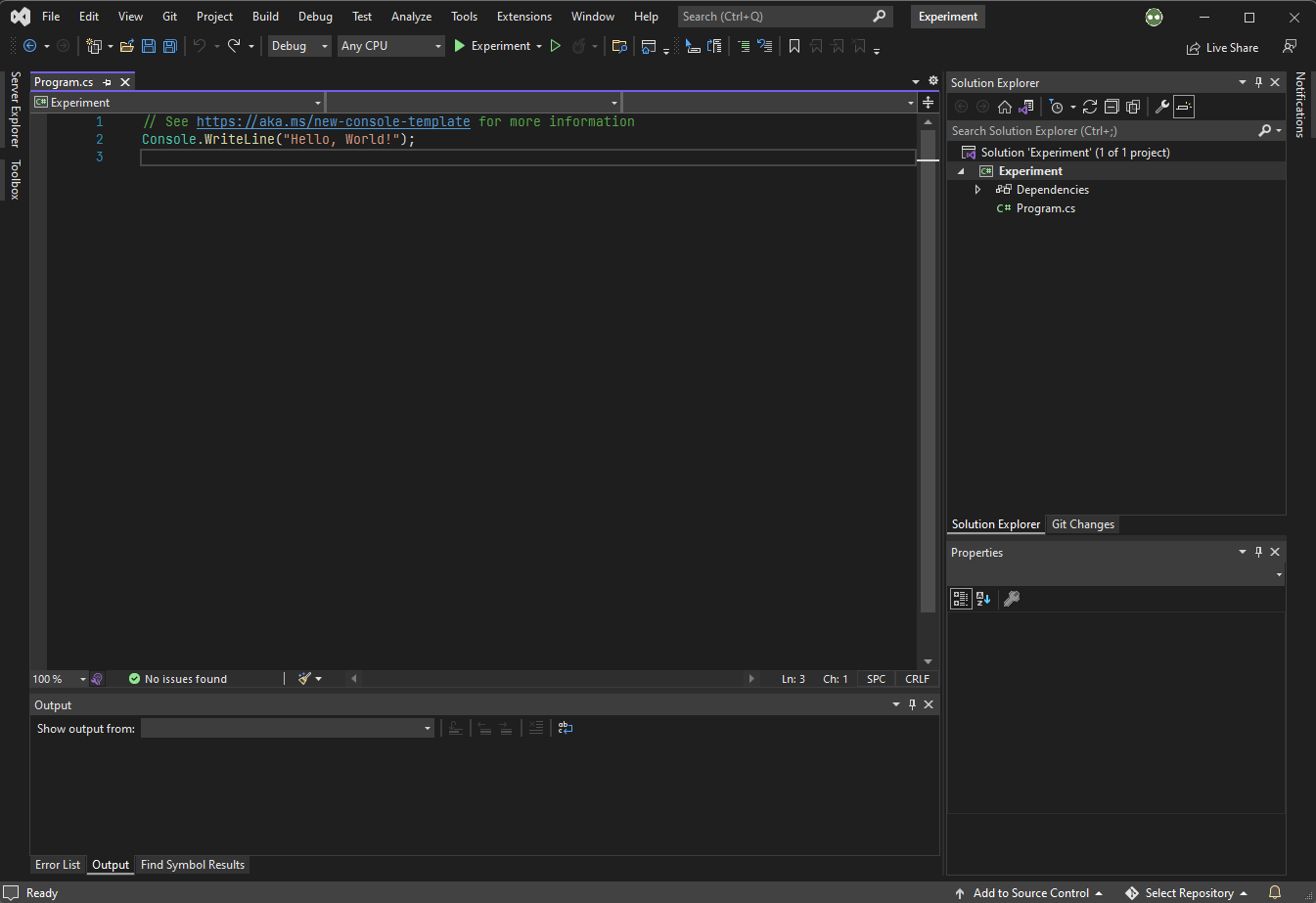
본 문서는 가독성을 위해 후자에서 선보인 최상위 문장이 작용한 코드를 예시로 활용할 예정이다.
기초
각 프로그래밍 언어마다 준수되어야 할 규칙(일명 구문; syntax)과 기반이 되는 데이터들이 존재한다. 이를 어길 시에는 프로그램에 오류가 발생하거나 정상적인 동작을 보장할 수 없다. 실질적인 프로그래밍에 있어, 본 장에서는 C# 프로그램 코딩에 기초적인 정보 제공을 목표로 한다.
주석
주석(comment)은 프로그래밍에 있어 실행되지 않는 부분이며, 흔히 어떠한 정보를 간략히 스크립트 내에 입력하는데 사용된다. C# 프로그래밍 언어에는 두 가지의 주석이 존재하며, 이들은 각각 한줄 주석과 블록 주석이라 부른다.
- 한줄 주석 (line comment): 코드 한 줄을 차지하는 주석이며, 두 개의 슬래시
//로 표시된다. - 범위 주석 (delimited comment): 코드 여러 줄을 차지하는 주석이며, 한 쌍의 슬래시와 별표
/* */로 표시된다.
/*
블록 주석:
코드 여러 줄을 차지하는 주석이다.
*/
// 한줄 주석: 코드 한 줄을 차지하는 주석이다.
문서 주석
문서 주석(documentation comment)은 프로그래머가 직접 자신들의 코드에 XML 형식으로 설명을 덧붙일 수 있도록 한다. 해당 코드 위에 마우스를 올리면 내용을 바로 확인할 수 있어 편리하다. 일반 주석과 유사하게 /// 및 /** */로 표시된다. 단, 문서 주석의 내용은 반드시 <summary>, <param> 등의 정해진 XML 태그 내에서 작성되어야 한다.

/**
<summary>범위 문서 주석:
코드 여러 줄을 차지하는 문서 주석이다.</summary>
*/
/// <summary>한줄 문서 주석: 코드 한 줄을 차지하는 문서 주석이다.</summary>
표현식
프로그래밍에서는 표현식과 문장이 있다.
-
표현식(expression)
값을 반환하는 구문적 존재를 가리킨다. 표현식에 대한 결과를 도출하는 것을 평가(evaluate)라고 부른다.
2 + 3 // 숫자 5를 반환 2 < 3 // 논리 참을 반환 -
문장(statement)
실질적으로 무언가를 실행하는 구문적 존재를 가리킨다: 흔히 하나 이상의 표현식으로 구성되지만,
break및continue와 같이 독립적으로 사용되는 문장도 있다. C# 프로그래밍 언어에서 모든 문장은 문장 종단자(statement terminator)인 세미콜론;으로 마무리 되어야 한다.int variable = 2 + 3; // 숫자 5를 "variable" 변수에 초기화 if (2 < 3) statement; // 논리가 참이면 "statement" 문장 실행 -
블록(block)
소스 코드를 중괄호
{}로 그룹화시키는 프로그래밍 언어의 어휘적 구조이다. 블록의 두 가지 의의는 (1) 여러 문장들을 하나의 문장처럼 다루거나 (2) 데이터가 취급되는 영역을 구분 짓는다.{ int variable = 2 + 3; if (2 < 3) statement; }
입력 및 출력
C# 프로그래밍 언어는 System.Console 클래스에서 입출력 기능을 제공하며, 다음과 같은 텍스트 기반의 출력 함수를 가진다.
| 출력 함수 | 설명 |
|---|---|
Write() |
단순히 데이터를 터미널에 출력한다. |
WriteLine() |
자동 줄바꿈과 함께 데이터를 터미널에 출력한다. |
System.Console.Write("C#");
System.Console.Write(3.14159);
System.Console.WriteLine("Hello World!");
System.Console.WriteLine(2);
C#3.14159Hello World!
2
반면, 입력 함수는 변수(variable)라는 데이터 저장공간이 필요하며 이는 차후에 설명할 예정이다.
| 입력 함수 | 설명 |
|---|---|
Read() |
터미널에 입력된 텍스트 중에서 문자(character) 하나만을 읽는다. |
ReadLine() |
터미널에 입력된 텍스트 한 줄 전체를 읽는다. |
var variable1 = System.Console.Read();
var variable2 = System.Console.Read();
var variable3 = System.Console.ReadLine();
var variable4 = System.Console.ReadLine();
/* 입력:
Hello World!
3.14159
*/
System.Console.WriteLine(variable1);
System.Console.WriteLine(variable2);
System.Console.WriteLine(variable3);
System.Console.WriteLine(variable4);
72
102
llo World!
3.14159
합성 형식지정
합성 형식지정(composite formatting)은 텍스트에 표시된 자리 표시자(placeholder) { 순번 }에 데이터를 형식에 맞추어 기입하는 기법이다. 형식 텍스트 다음에는 자리 표시자에 들어갈 데이터를 순번에 따라 순차적으로 입력한다.
순번은 오로지 음이 아닌 정수만을 사용해야 하며 숫자 0부터 시작되어야 한다.
System.Console.Write("첫 번째: {0}, 두 번째: {1}, 그리고 다시 첫 번째: {0:N2}", 3, 'G');
첫 번째: 3, 두 번째: G, 그리고 다시 첫 번째: 3.00
문자열 보간
문자열 보간(string interpolation)은 데이터를 텍스트의 특정 위치에 나타나도록 하며, 중괄호 {} 사이에 데이터나 표현식을 직접 삽입한다. 합성 형식지정과 유사하지만, 두 가지의 차이점을 가진다.
- 텍스트를 표시하는 큰 따옴표
""앞에 달러 기호$가 붙는다. - 중괄호 안에는 번호가 아닌 실제 나타날 데이터가 삽입된다.
var number = 3;
var character = 'G';
System.Console.Write($"첫 번째: {number}, 두 번째: {character}, 그리고 다시 첫 번째: {number:N2}");
첫 번쨰: 3, 두 번째: G, 그리고 다시 첫 번째: 3.00
탈출 문자
탈출 문자(escape character)는 백슬래시 기호 \를 사용하며, 문자열로부터 탈출하여 텍스트 데이터 내에서 특정 연산을 수행하도록 한다. 이전에 문자열 자료형을 소개할 때, \n 탈출 문자를 사용하여 문자열 줄바꿈을 구현한 것을 보여주었다.
System.Console.Write("Hello\nWorld!");
Hello
World!
식별자
식별자(identifier)는 프로그램을 구성하는 데이터들을 구별하기 위해 사용되는 명칭이다. 즉, 식별자는 개발자가 데이터에 직접 붙여준 이름이다. C# 프로그래밍 언어에서 식별자를 선정하는데 아래의 규칙을 지켜야 한다.
- 오직 영문, 숫자, 밑줄
_만 허용된다. - 첫 문자는 숫자로 시작할 수 없다.
- 공백은 허용되지 않는다.
- 대소문자를 구분한다.
자료형
자료형(data type)은 데이터를 어떻게 표현할 지 결정하는 요소이며, C# 프로그래밍 언어에서는 여러 자료형이 존재한다. 이들은 크게 두 유형으로 나뉘어지는데 값 자료형(value type) 그리고 참조 자료형(reference type)이 있다. 해당 유형들이 의의는 변수를 소개할 때 설명할 예정이다.
아래는 C# 프로그래밍 언어가 갖는 자료형의 일부이며, 자세한 내용은 여기에서 확인할 수 있다:
System.Type은 자료형이 갖는 메타데이터(예. 자료형이 속한 어셈블리, 맴버들에 대한 정보 등)를 자세히 제공할 수 있는 클래스이다.
| 키워드 | System.Type |
자료형 유형 | 설명 |
|---|---|---|---|
byte |
System.Byte |
값 | 8비트 unsigned 정수 |
sbyte |
System.SByte |
값 | 8비트 정수 |
short |
System.Int16 |
값 | 16비트 정수 |
ushort |
System.UInt16 |
값 | 16비트 unsigned 정수 |
int |
System.Int32 |
값 | 32비트 정수 |
uint |
System.UInt32 |
값 | 32비트 unsigned 정수 |
long |
System.Int64 |
값 | 64비트 정수 |
ulong |
System.UInt64 |
값 | 64비트 unsigned 정수 |
float |
System.Single |
값 | 32비트 단정밀도 실수 숫자 리터럴에 f 혹은 F 접미사 필요 |
double |
System.Double |
값 | 64비트 배정밀도 실수 (선택사항) 숫자 리터럴에 d 혹은 D 접미사 사용 |
decimal |
System.Decimal |
값 | 128비트 실수 숫자 리터럴에 m 혹은 M 접미사 필요 |
bool |
System.Boolean |
값 | 논리적 참과 거짓을 true(영이 아닌 정수)와 false(영)로 표시 |
char |
System.Char |
값 | 단일 UTF-16 문자 문자 리터럴은 따옴표 '' 필요 |
string |
System.String |
참조 | 일련의 문자들, 일명 문자열 문자열 리터럴은 쌍따옴표 "" 필요 |
object |
System.Object |
참조 | 아무런 자료형 모든 자료형의 기반이므로 어떠한 자료형이라도 수용 가능 |
void |
System.Void |
보이드 | 자료형 없음 |
var |
- | - | 컴파일 과정에 적합한 자료형으로 자동 결정 |
위의 대부분 자료형은 (참조 자료형의 경우) 클래스 혹은 (값 자료형의 경우) 이와 유사한 구조체여서 자신만의 맴버를 가질 수 있다. 비주얼 스튜디오에서 F12를 누르면 자료형이 어떻게 구성되어 있는지 찾아볼 수 있는데, 대체로 class 혹은 struct 키워드를 사용한 것을 확인할 수 있다. 예를 들어, C# 프로그래밍 언어에서 double 자료형과 숫자 리터럴로 다음을 수행할 수 있다.
/* double 자료형 */
System.Console.WriteLine(double.MaxValue); // 출력: 1.7976931348623157E+308
/* 숫자 리터럴 */
System.Console.WriteLine(3.14.GetType()); // 출력: System.Double
자료형마다 정해진 기본값이 있으며 이는 default 자료형 기본값 표현식(default value expression)으로 알아낼 수 있다.
System.Console.WriteLine(default(bool)); // 출력: False
Null 허용 자료형
null키워드는 데이터가 없음을 의미하는 리터럴이다.
Nullable, 즉 null이 허용된 자료형을 가리키며 자료형 키워드 접미부에 ? 기호가 붙는다.
-
본래
null값을 가질 수 없는 자료형이다.bool?와 같이 nullable 자료형으로 지정하면true,false, 그리고 아무런 데이터가 없는null을 할당받을 수 있다. -
이전부터
null을 할당받을 수 있는 자료형이지만 컴파일러는 초기화가 되지 않은 것으로 인식하여 경고문이 표시된다.string?와 같이 nullable 자료형으로 지정하면null도 하나의 값으로 인정하여 경고가 나타나지 않는다.
sizeof() 연산자
sizeof() 연산자는 데이터나 자료형가 메모리에 할당된 바이트 크기를 반환한다.
바이트(byte)란, 컴퓨터에서 메모리에 저장하는 가장 기본적인 단위이다. 자료형마다 크기가 정해진 이유는 효율적인 메모리 관리 차원도 있으나 CPU 연산과도 깊은 연관성을 갖는다.
sizeof(int); // 크기: 4바이트
sizeof(char); // 크기: 2바이트
변수
변수(variable)는 데이터를 지정된 자료형으로 저장하는 식별자를 갖는 저장공간이다. 아래 예시는 variable이란 식별자를 갖는 정수형 변수에 숫자 3을 할당한다. 시스템적 관점에서 바라보면 variable 정수형 변수의 존재가 컴파일러에 각인되고 메모리가 할당되어 3이란 값이 저장되는 것으로, 이를 변수의 “선언(declaration)”이라고 부른다.
C/C++ 프로그래밍 언어를 접하였으면 선언 외에도 “정의(definition)”에 대하여 인지하였을 것이다. C# 프로그래밍 언어는 ECMA-334 표준에 의하면 선언과 정의의 개념이 명확히 구분되어 있지 않으며, 오히려 선언과 정의를 동일한 개념으로 보고 있다.
/* 변수 "variable"의 선언 */
int variable = 3;
정수형 변수인 variable을 생성한 동시에 값 3을 할당하였는데, 변수로의 최초 할당을 “초기화(initialization)”라고 부른다. 아래는 변수를 선언하는 과정에서 초기화를 나중에 하는 예시 코드이다. 비록 초기화되지 않은 변수는 자료형마다 정해진 기본값(default value)을 갖는데, 안전한 언어를 추구하기 위해 컴파일러 측에서 초기화되지 않은 변수의 사용을 오류로 치부한다. 한 번 선언된 변수는 컴파일러 측에서 이미 존재를 알고 있으므로, 이후 변수에 다른 데이터를 저장하거나 호출할 때 자료형을 함께 언급할 필요가 없다.
/* 변수 "variable"의 선언 */
int variable; // variable = default(int), 즉 0
variable = 3; // variable = 3
단, 값 자료형과 참조 자료형으로 생성된 변수는 데이터 할당에 있어 다소 차이가 존재한다.
| 자료형 | 데이터 소재 메모리 | 설명 |
|---|---|---|
| 값 자료형 | 스택 (stack); 코드 실행용 |
변수는 자신에게 할당된 (스택 영역) 메모리에 데이터를 직접 저장한다. |
| 참조 자료형 | 힙 (heap); 데이터 저장용 |
변수는 별도의 (힙 영역) 메모리에 저장된 데이터를 참조한다. 그러므로 두 개 이상의 변수가 하나의 데이터를 참조하는 것이 가능하다. |
동일한 자료형의 변수 여러 개를 한꺼번에 선언하려면, 식별자마다 쉼표 ,로 구분지을 수 있다.
/* 다수의 정수 자료형 변수 선언 */
int variable1 = 3, variable2 = 4, variable3;
변수는 오로지 지정된 자료형 데이터만을 할당받아야 하지 않다. 아래 예시 코드는 정수형 및 문자형 변수에 값 75로 초기화하였다. 정수형 변수에는 정수 75로 저장되지만, 문자형 변수의 경우 UTF-16 인코딩 코드에 의하여 대문자 ‘K’로 저장된다.
long variable1 = 75; // variable1에는 정수 75가 저장
char variable2 = 75; // variable2에는 문자 'K'가 저장
거의 모든 프로그래밍 언어는 할당 기호를 기준으로 왼쪽에는 피할당자(변수), 오른쪽에는 할당자(데이터 혹은 변수)가 위치한다. 반대로 놓여질 경우, 오류가 발생하거나 원치 않는 결과가 도출될 수 있다.
상수
상수(constant)는 한 번 데이터를 할당한 후 변경할 수 없는 특별한 변수이며, const 혹은 readonly 키워드와 함께 선언된다.
-
const한정자초기화 이후 변동이 불가한 정적 상수(static constant) 맴버를 선언한다. 컴파일 상수이므로 선언 당시에 초기화되지 않으면 컴파일 오류가 발생한다.
/* const 컴파일 상수 선언 */ const int variable = 3; -
readonly한정자초기화 이후 변동이 불가한 비정적 비완전상수(non-static semi-constant) 맴버를 선언한다. 런타임 상수이므로 생성자를 통한 유연한 초기화가 허용된다.
/* readonly 런타임 상수 선언 */ readonly int variable = 3;
지역 변수 및 전역 변수
C# 프로그래밍 언어에서 변수가 코드 중에서 어디에 선언되었는지에 따라 두 가지의 종류로 구분된다.
-
지역 변수(local variable)
블록 내부에서 선언된 변수이다. 지역 변수에 저장된 데이터는 블록 밖에서는 소멸되므로 외부에서 사용할 수 없다.
class Program { static void Main(int[] args) { /* 지역 변수 */ int variable; } } -
전역 변수(global variable)
이론적으로 블록 내에 속하지 않은 외부에 선언된 변수로써 어느 블록에서도 호출만으로 지역 변수와 함께 사용할 수 있는 변수이다. 허나 객체지향 프로그래밍은 클래스 외부에 별도의 변수를 선언하는 게 불가능한 구조이므로 전역 변수를 지원하지 않는다.
네임스페이스
네임스페이스(namespace)는 식별자의 유일성을 보장하기 위한 데이터 분류 공간으로, namespace 키워드를 통해 생성하여 (1) 블록 {} 안에 데이터들을 분류하거나 (2) C# 10.0 이후부터 블록을 생략하여 해당 스크립트 파일 전체를 네임스페이스로 분류할 수 있다. 네임스페이스 안에 또 다른 네임스페이스를 선언할 수 있으며, 이를 네스티드 네임스페이스(nested namespace)라고 부른다. 그러나 네임스페이스 또한 유일한 식별자를 가져야 하기 때문에 동일한 영역범위(scope)에 놓여진 네임스페이스는 이름이 중복되어서는 안된다.
서로 다른 이름의 폴더(네임스페이스) 안에 동명의 파일(데이터) 혹은 폴더(네스티드 네임스페이스)를 보관할 수 있는 것과 같은 개념이다.
네임스페이스에 들어있는 데이터 및 네스트디 네임스페이스를 접근하기 위해서는 .을 활용하는 맴버 접근 표현식(member access expression)을 사용한다.
System.Console.WriteLine(namespace1.nested.cls.variable);
System.Console.WriteLine(namespace2.nested.cls.variable);
/* 네임스페이스 1 선언 */
namespace namespace1
{
namespace nested
{
class cls
{
int variable = 3;
}
}
}
/* 네임스페이스 2 선언 */
namespace namespace2
{
namespace nested
{
class cls
{
int variable = 7;
}
}
}
3
7
터미널 입력 및 출력의 System.Console 클래스에서 System이 바로 네임스페이스에 해당한다.
전역 네임스페이스
전역 네임스페이스(global namespace)는 어느 네임스페이스에도 속하지 않는 최외각 영역범위이다. 전역 네임스페이스는 global 키워드와 함께 네임스페이스 별칭 한정자(namespace alias qualifier) :: 연산자를 식별자의 접두부에 기입하여 명시한다.
global::System.Console;
/* 동일:
System.Console;
*/
using 키워드
using 키워드는 네임스페이스 내의 데이터를 간편하게 접근할 수 있도록 한다. 즉, 네임스페이스를 별도로 명시하지 않아도 데이터 호출이 가능하게 한다. 하지만 using 키워드의 무분별한 남용은 컴파일러가 어느 네임스페이스의 데이터를 호출하는 것인지 구별하지 못하게 하여 오류가 발생할 위험이 높다.
-
using지시문(using-directive)스크립트 파일에서 해당 네임스페이스 전체를 생략한다. 만일 프로젝트에 암묵적
using지시문이 활성화되어 있으면System을 포함한 흔히 사용되는 일부 네임스페이스가 자동으로 생략될 수 있다./* System 네임스페이스 생략 */ using System; Console.WriteLine("Hello World!"); -
using별칭(using-alias)네임스페이스에 별칭을 부여하여 코드 길이를 단축시키거나 가독성을 높인다. 네임스페이스 별칭으로부터 맴버들은
.토큰 혹은::연산자를 통해 접근할 수 있으나, 후자는 좌측의 식별자가 반드시 네임스페이스임을 보장하여 권장된다./* System 네임스페이스 별칭 */ using alias = System; alias::Console.WriteLine("Hello World!"); /* 대안: alias.Console.WriteLine("Hello World!"); */반면 별칭은 클래스까지 내포할 수 있으며, 이때는 오로지
.토큰만을 사용하여 맴버를 호출해야 한다./* Console 클래스 별칭 */ using alias = System.Console; alias.WriteLine("Hello World!");
자료형 변환
자료형 변환(type casting)은 상수 혹은 변수로부터 호출한 데이터를 강제로 다른 자료형으로 바꾸는 작업이다.
-
암묵적 자료형 변환(implicit type casting)
변환 시 데이터 손실이 없어 컴파일러에서 자연적으로 처리되는 변환이다. 흔히 유사한 자료형을 작은 크기에서 큰 크기로 키울 때 자동적으로 발생한다.
short A = 1; // 2바이트 정수형 int B = A; // 4바이트 정수형 -
명시적 자료형 변환(explicit type casting)
변환 시 데이터 손실의 위험을 감수하며 데이터의 자료형을 바꾼다. C 형식 캐스팅은 소괄호
()안에 자료형을 기입한다.float A = 1.9; // 4바이트 부동소수점 int B = (int)A; // 4바이트 정수형 - 완전 호환 불가: 정수 부분만 반환된다. -
Convert클래스Convert클래스는 특정 기능을 제공하므로써 도와주는 일종의 도우미 클래스(helper class)에 해당하며 자료형 변환에 사용된다./* 도우미 클래스: 정수 자료형 변환 */ int ivalue = System.Convert.ToInt32("123");
자료형 확인 연산자
다음은 C# 프로그래밍 언어에서 제공하는 자료형을
-
is연산자데이터가 비교하고자 하는 자료형과 호환되면 참(
true)을 반환하고, 그렇지 않으면 거짓(false)을 반환한다.variable is T; -
as연산자데이터를 주어진 자료형으로 캐스팅하여 반환하는데, 만일 호환성 문제로 변환이 불가하면
null을 반환한다.variable as T; /* 동일: variable is Type ? (T)variable : (T)null; */ -
typeof연산자자료형의
System.Type을 반환한다. 흔히 자료형의 일치 여부를 확인하기 위해 사용된다.자료형이 아닌 데이터의 경우에는
GetType()메소드로 확인한다.variable.GetType() == typeof(T);
연산자
연산자(operator)는 피연산 데이터를 조작할 수 있는 가장 간단한 형태의 데이터 연산 요소이다. 연산자는 피연산자의 접두부, 접미부, 혹은 두 데이터 사이에 위치시켜 사용한다.
산술 연산자
산술 연산자(arithmetic operator)는 정수나 부동소수점 자료형 산술 연산에 사용된다: 가장 기본적인 +, -, *, / 사칙 연산자부터 나눗셈의 나머지 %를 구할 수 있다. 산술 연산을 쉽게 읽을 수 있도록 숫자와 산술 연산자 사이에 공백을 넣어도 연산에는 아무런 영향을 주지 않으므로 무관한다.
증가 연산자(increment operator) ++ 및 감소 연산자(decrement operator) --는 데이터를 1만큼 증가 혹은 감소하는데 간략하게 한 줄로 표현할 수 있도록 한다.
-
접두부
해당 변수를 1만큼 증가/감소시킨 다음에 표현식을 평가한다.
x = ++y; // 동일: y = y + 1; x = y; x = --y; // 동일: y = y - 1; x = y; -
접미부
표현식을 평가한 다음에 해당 변수를 1만큼 증가/감소시킨다.
x = y++; // 동일: x = y; y = y + 1; x = y--; // 동일: x = y; y = y - 1;
할당 연산자
할당 연산자(assignment operator)는 할당 기호 =와 조합하여 산술 연산 코드를 더욱 간결하게 작성할 수 있도록 한다.
| 연산자 | 예시 | 동일 |
|---|---|---|
= |
x = y |
x = y; x 변수에 y 변수의 값을 할당하고, 할당된 값을 반환한다. |
+= |
x += y |
x = x + y |
-= |
x -= y |
x = x - y |
*= |
x *= y |
x = x * y |
/= |
x /= y |
x = x / y |
%= |
x %= y |
x = x % y |
여기서
=연산자가 할당된 값을 반환한다는 것을 통해 다음과 같은 표현식을 구현할 수 있다.int variable; System.Console.WriteLine(variable = 3);3
비교 연산자
비교 연산자(relational operator)는 두 데이터를 대조하는데 사용된다: 초과 >와 미만 <, 이상 >=과 이하 <=, 그리고 동일 ==와 다름 != 관계 부합 여부에 따라 논리적 참 혹은 거짓이 반환된다.
논리 연산자
논리 연산자(logical operator)는 논리 자료형의 조합이 논리적으로 참인지 거짓인지 판별한다.
| 연산자 | 논리 | 설명 |
|---|---|---|
&& |
논리곱 | 모든 데이터가 참이면 true를 반환하고, 그렇지 않으면 false을 반환한다. |
|| |
논리합 | 하나 이상의 데이터가 참이면 true를 반환하고, 그렇지 않으면 false을 반환한다. |
! |
보수 | 참을 거짓으로, 또는 거짓을 참으로 변경한다. |
조건 및 루프
조건문(conditional statement) 및 반복문(loop statement)은 프로그래밍에 가장 흔히 사용되는 코드 문장(statement) 중 하나이다. 여기서 문장이란, 실질적으로 무언가를 실행하는 코드를 의미한다. 본 장에서는 C# 프로그래밍의 조건에 따라 실행하는 조건문과 반복적으로 실행하는 반복문을 소개한다.
if 조건문
if 조건문은 조건 혹은 논리가 참(true)일 경우 코드를 실행하며, 거짓(false)일 경우에는 코드를 실행하지 않는다.
if (condition)
{
statements;
}
// 간략화된 문장
if (condition) statement;
else 조건문
else 조건문은 단독으로 사용될 수 없으며 반드시 if 조건문 이후에 사용되어야 한다. 조건부가 거짓(false)으로 판정되면 실행할 코드를 포함한다.
if (condition)
{
statements;
}
else
{
statements;
}
else if 조건문
else if 조건문은 else와 if 조건문의 조합으로 이전 조건이 거짓(false)일 때 새로운 조건을 제시한다.
if (condition)
{
statements;
}
else if (condition)
{
statements;
}
else
{
statements;
}
조건 연산자
조건 연산자(ternary operator) ?:는 세 가지 인수만을 사용하여 조건문을 아래와 같이 간략하게 표현한다. 조건 연산자는 가독성을 감소시키므로 과용해서는 안되지만 변수 할당에 유용하다.
condition ? true_return : false_return;
조건 연산자는 가독성을 감소시키므로 과용해서는 안되지만 변수 할당에 유용하다.
switch 조건문
switch 조건문은 전달받은 인자를 case의 상수와 동일한지 비교하여 논리가 참일 경우 해당 지점부터 코드를 실행하며, 거짓일 경우에는 다음 case로 넘어간다. 선택사항으로 default 키워드를 통해 어떠한 case 조건에도 부합하지 않으면 실행될 지점을 지정한다.
switch (argument)
{
case value1:
statements;
break;
case value2:
statements;
break;
case value3:
statements;
break;
default:
statements;
}
switch 조건문이 어느 case 코드를 실행할지 결정하는 것이라고 쉽사리 착각할 수 있으나, 이는 사실상 break 탈출문 덕분이다. 탈출문이 없었더라면 아래 예시 코드처럼 해당 조건의 case 코드 실행을 마쳤어도 다음 case 코드로 계속 진행하는 걸 확인할 수 있다. 즉, case 키워드는 코드 실행 영역을 분별하는 것이 아니라 진입 포인트 역할을 한다.
int variable = 2;
// switch 조건문의 동작 예시
switch (variable)
{
case 1:
System.Console.WriteLine("Statement 1");
case 2:
System.Console.WriteLine("Statement 2");
case 3:
System.Console.WriteLine("Statement 3");
default:
System.Console.WriteLine("Statement 4");
}
Statement 2
Statement 3
Statement 4
while 반복문
while 반복문은 조건 혹은 논리가 참(true)일 동안 코드를 반복적으로 실행하며, 거짓(false)일 경우에는 반복문을 종료한다.
while (condition)
{
statements;
}
// 간략화된 문장
while (condition) statement;
do 반복문
do 반복문은 코드를 우선 실행하고 조건 혹은 논리가 참(true)일 경우 코드를 반복하며, 거짓(false)일 경우에는 반복문을 종료한다.
do
{
statements;
} while (condition);
break 문
break 문(일명 탈출문)은 반복문을 조기 종료시키는데 사용된다. 반복 실행 도중에 탈출문을 마주치는 즉시 가장 인접한 반복문으로부터 탈출한다.
continue 문
continue 문은 반복문의 나머지 실행문을 전부 건너뛰어 다시 반복문의 조건부로 돌아간다. break와 달리 반복문은 종료되지 않고 여전히 살아있다.
for 반복문
for 반복문은 조건 혹은 논리가 참(true)일 동안 코드를 반복적으로 실행하며, 거짓(false)일 경우에는 반복문을 종료한다. for 반복문은 조건 평가 외에도 지역 변수를 초기화 및 증감할 수 있는 인자가 있다.
for (initialize; condition; increment)
{
statements;
}
// 간략화된 문장
for (initialize; condition; increment) statement;
for 반복문의 우선 initialize에서 반복문 지역 변수를 선언하거나 외부 변수를 불러와 반복문을 위한 초기값을 할당한 다음 condition에서 조건을 평가한다. 논리가 참이면 코드를 반복적으로 실행하며, 거짓일 경우에는 반복문을 종료한다. 블록 내의 코드가 마무리되었거나 continue 문을 마주하면 increment에서 변수를 증감하고, condition으로 돌아가 절차를 반복한다.
foreach 반복문
foreach 반복문은 조건 만족 여부에 따라 반복하는 게 아니라 주어진 범위 내에서 반복한다. 범위로 사용되는 데이터는 요소를 하나씩 나열할 수 있는 컬렉션(collection)을 일반적으로 사용한다.
foreach (element in range)
{
statements;
}
// 간략화된 문장
foreach (element in range) statement;
goto 이동문
goto 이동문은 다른 문장으로써는 절대로 접근이 불가한 코드에 도달할 수 있도록 한다 (일명 제어 전달; control transfer). goto 키워드에 명시된 레이블로 제어를 전달하나, 이 둘은 반드시 동일한 함수 내에 위치해야 한다. 레이블은 goto 문 이전이나 이후에 위치하여도 무관하다.
// 제어 전달: "label"로 이동
goto label;
// "label" 레이블
label:
statements;
컬렉션
C# 프로그래밍 언어는 여러 데이터를 하나의 변수로 저장하는 컬렉션(collection)을 제공한다. 본 장은 .NET에서 활용할 수 있는 몇 가지의 컬렉션 유형들을 소개한다.
배열
배열(array)은 동일한 자료형의 데이터를 일련의 순서로 담는 저장공간이다. 선언 시 자료형 뒤에는 대괄호 []가 위치하여 배열임을 명시해야 한다. 비록 배열이 갖는 자료형이 값 자료형(예. int, double, char 등)일지라도 배열 자체는 Array 추상 기반 클래스로부터 파생된 참조 자료형이다. 초기화되지 않은 배열은 null을 기본값으로 가지며, new 키워드와 함께 자료형 및 크기를 정수로 지정하여 객체로 생성된 배열을 할당하므로써 초기화한다.
/* 배열 선언 및 객체화 */
int[] variable = new int[size];
/* 동일:
Array variable = Array.CreateInstance(typeof(int), size);
*/
new 키워드로 객체화된 배열은 초기화가 이루어지지 않을 시, 요소들은 배열 자료형의 기본값으로 채워진다. 배열 객체의 초기화는 중괄호 {}를 사용하여 데이터를 순번에 맞게 배열 요소에 할당한다.
-
방법 1: 반드시 크기만큼 요소의 값을 지정해야 한다.
int[] variable = new int[size] {value1, value2, ... }; -
방법 2: C/C++와 동일하게 곧바로 집합 초기화를 적용한다.
int[] variable = {value1, value2, ... }; /* 동일: int[] variable = new int[] {value1, value2, ... }; */
배열의 각 요소에 할당된 데이터는 대괄호 []를 사용해 0번부터 시작하는 인덱스 위치를 호출할 수 있다. 그러나 배열 자체를 호출하면 배열 자체의 자료형이 반환된다. 단, 자료형이 char 문자인 배열은 문자들을 하나씩 나열한 게 문자열처럼 반환된다.
int[] variable = new int[3] {value1, value2, value3};
Console.WriteLine(arr); // 출력: System.Int32[]
Console.WriteLine(arr[0]); // 출력: value1
이러한 배열의 특징으로 인해 배열은 선언 외에 한꺼번에 할당이 불가능하다. 그렇지만 개별 요소를 재할당하여 데이터를 변경할 수 있다.
int[] variable = new int[3];
/* 배열의 개별 요소 할당 */
variable[0] = value1;
variable[1] = value2;
variable[2] = value3;
new 연산자
new 연산자는 자료형의 객체를 생성, 즉 객체화(instantiation)에 사용되는 연산자이다.
/* 자료형 객체화 */
object variable = new object();
만일 변수와 동일한 자료형의 객체를 생성하려면 아래와 같이 구문을 간략화할 수 있다.
object variable = new();
다차원 배열
배열은 또 다른 배열을 요소로 가질 수 있으나, 자료형이 동일해야 하며 요소로 작용하는 배열들의 크기는 모두 같아야 하는 제약을 갖는다. 다차원 배열은 한 번의 객체화로 생성되었기 때문에, 비록 배열 안에 또 다른 배열이 있다 하더라도 전부 하나의 데이터로 간주된다.
-
방법 1: 반드시 크기만큼 요소의 값을 지정해야 한다.
int[,] variable = new int[size1, size2] { {value1, value2}, {value3, value4}, ... }; -
방법 2: C/C++와 동일하게 곧바로 집합 초기화를 적용한다.
int[,] variable = { {value1, value2}, {value3, value4}, ... }; /* 동일: int[,] variable = new int[,] { {value1, value2}, {value3, value4}, ... }; */
가변 배열
가변 배열(jagged array)은 크기와 상관없이 또 다른 동일 자료형 배열을 요소로써 가질 수 있다. 이미 메모리가 할당된 배열을 요소로 가지므로, 가변 배열은 두 개 이상의 배열 데이터가 활용되는 것이다.
int[][] variable = new int[size][] {
new int[] { ... },
new int[] { ... },
new int[] { ... },
...
};
컬렉션
본 내용은 차후에 소개될 제네릭과 연관이 깊은 부분이므로, 필수는 아니지만 해당 장을 읽으면 이해에 도움이 된다.
컬렉션(collection)은 크기를 가변할 수 있는 또 다른 배열 형식의 데이터이며, 컬렉션마다 고유의 특징과 기능이 탑재되어 있다. 제네릭 및 비제네릭 컬렉션으로 나뉘어지는데, 간단히 설명하자면 제네릭은 컬렉션이 수용할 자료형을 직접 객체화 과정에서 지정이 가능한 클래스를 일컫는다.
-
List<T>클래스배열과 성질이 가장 유사하지만 비교적 높은 유연성이 요구될 때 사용되는 제네릭 컬렉션이다. 이와 유사한 데이터 구조로 C++의 벡터 클래스 또는 파이썬의 리스트가 있다.
List<int> variable = new List() {3, 1, 4, 1, 5}; Console.WriteLine(variable[0]); // 출력: 3 -
배열 요소가
{key, value}형식으로 구성된 크기 확장이 유연한 제네릭 컬렉션이다.value값을 호출하려면 대괄호[]안에 정수 인덱스가 아닌key식별자를 기입한다.Dictionary<string, int> variable = new() { {"Beta", 3}, {"Alpha", 1} }; Console.WriteLine(variable["Beta"]); // 출력: 3 -
SortedList<TKey,TValue>,SortedDictionary<TKey,TValue>클래스배열 요소가
{key, value}형식으로 구성되고key순서대로 정렬된 크기 확장이 유연한 제네릭 컬렉션이다. 두 클래스는 메모리 활용과 데이터 삽입 및 제거 속도에서 차이가 나타난다:-
SortedList<TKey,TValue>는IList<T>에 기반한 리스트 성질이 반영되어 인덱스로 요소 값을 호출할 수 있으며 메모리를 적게 사용한다.SortedList<string, int> variable = new() { {"Beta", 3}, {"Alpha", 1} }; Console.WriteLine(variable["Beta"]); // 출력: 3 -
SortedDictionary<TKey,TValue>는IDictionary<TKey,TValue>에 기반한 딕셔너리의 성질이 반영되며 데이터 삽입 및 제거 작업이 빠르다.SortedDictionary<string, int> variable = new() { {"Beta", 3}, {"Alpha", 1} }; Console.WriteLine(variable["Beta"]); // 출력: 3
-
-
Stack<T>클래스선형적 LIFO(Last-In-First-Out), 즉 마지막에 입력된 데이터가 먼저 출력되는 스택 구조를 따르는 제네릭 컬렉션이다. 해당 컬렉션은 대괄호
[]를 통해 요소를 인덱싱 할 수 없다.Stack<int> variable = new(); variable.Push(1); variable.Push(2); variable.Push(3); Console.WriteLine(variable.Pop()); // 출력: 3 Console.WriteLine(variable.Pop()); // 출력: 2 Console.WriteLine(variable.Pop()); // 출력: 1 -
Queue<T>클래스선형적 FIFO(First-In-First-Out), 즉 먼저 입력된 데이터가 먼저 출력되는 큐 구조를 따르는 제네릭 컬렉션이다. 해당 컬렉션은 대괄호
[]를 통해 요소를 인덱싱 할 수 없다.Queue<int> variable = new(); variable.Enqueue(1); variable.Enqueue(2); variable.Enqueue(3); Console.WriteLine(variable.Dequeue()); // 출력: 1 Console.WriteLine(variable.Dequeue()); // 출력: 2 Console.WriteLine(variable.Dequeue()); // 출력: 3 -
HashSet<T>클래스중복 요소를 허용하지 않는 제네릭 컬렉션이다. 해당 컬렉션은 수학의 집합에서 사용되는 연산과 동일하게 작용하나, 대괄호
[]를 통해 요소를 인덱싱 할 수 없다.HashSet<int> variable = new(new int[] {3, 1, 4, 1, 5}); foreach(var element in variable) Console.Write(element); // 출력: 3145 -
BitArray클래스오로지 논리적 참(
false) 혹은 거짓(true)만을 저장하여 자료형이 논리형으로 고정된 비제네릭 컬렉션이다. 논리형 배열과 달리 각 요소는 오로지 한 비트만을 차지하여 메모리를 적게 사용하지만, 데이터 정렬에 의해 인덱스 탐색이 다소 느린 단점을 가진다. 비제네릭 컬렉션은 제네릭과 다른 네임스페이스에 속하므로 다음 코드와 같이using지시문을 기입하였다.using System.Collections; BitArray variable = new(new bool[] {false, true, true, false}); Console.WriteLine(variable[0]); // 출력: False
함수
함수(function)는 독립적인 코드 블록으로써 데이터를 처리하며, 재사용이 가능하고 호출 시 처리된 데이터를 보여주어 유동적인 프로그램 코딩을 가능하게 한다. 함수는 이름 뒤에 소괄호가 있는 Function() 형식으로 구별된다.
double variable = 3.14159
Console.WriteLine(Math.Round(variable));
// 터미널에 텍스트를 출력하는 "Console.WriteLine()", 그리고 소수점을 반올림하는 "Math.Round()" 함수
3
함수의 기능을 선언(declaration)하기 위해서는 두 가지의 구성요소가 반드시 필요하다:
/* 함수 선언 */
void Function()
{
Console.WriteLine(1 + 2);
}
/* 함수 호출 */
Function(); // 출력: 3
C# 프로그래밍 언어와 같은 객체지향에서는 캡슐화(encapsulation)에 의해 함수의 선언과 호출 순서는 사실상 무의미하다. 즉, 위의 예시 코드와 달리 스크립트상 함수가 호출에 비해 나중에 선언되어도 정상적으로 동작한다.
최상위 문장의 암묵적 규칙은
using System; class Program { static void Main(string[] args) { Function(); } static void Function() { Console.WriteLine(1 + 2); { }
함수명 뒤에 소괄호 () 기입여부에 따라 의미하는 바가 다르다.
-
Function()은 함수에 정의된 코드를 실행한다.void Function() { Console.WriteLine(1 + 2); } Function(); Console.WriteLine("반환: {0}", Function()); // [CS1503] 2 인수: 'void'에서 'object?'(으)로 변환할 수 없습니다.3 -
Function은 함수의 Type을 반환한다.void Function() { Console.WriteLine(1 + 2); } Function; // [CS0201] 할당, 호출, 증가, 감소 및 새 개체 식만 문으로 사용할 수 있습니다. Console.WriteLine("반환: {0}", Function);반환: System.Action
return 반환문
return 반환문은 함수로부터 데이터를 함수에 지정된 자료형으로 반환하는 함수 전용 문장이다. 반환문이 실행되면 하단에 코드가 남아 있음에도 불구하고 함수는 즉시 종료된다. 함수의 자료형이 void이면 반환문은 필요가 없으나, 흔히 함수를 조기에 종료하기 위해서도 사용된다.
// return 반환문이 있는 사용자 정의 함수
int Function()
{
Console.WriteLine("Hello World!");
return 1 + 2;
}
Console.WriteLine(Function());
Hello World!
3
매개변수 및 전달인자
다음은 함수에 대해 논의할 때 중요하게 언급되는 매개변수와 전달인자의 차이에 대하여 설명한다.
- 전달인자 (argument): 전달인자, 혹은 간략하게 “인자”는 함수로 전달되는 데이터이다.
- 매개변수 (parameter): 전달인자를 할당받는 함수 내의 지역 변수이다. 그러므로 매개변수는 함수 외부에서 호출이 불가능하다. 매개변수 선언은 함수의 소괄호
()내에서 이루어진다.
매개변수와 전달인자는 개념적으로 다른 존재이지만, 동일한 데이터를 가지고 있는 관계로 흔히 두 용어는 혼용되어 사용하는 경우가 많다.
다음은 매개변수에 사용되는 연산자로 전달인자을 받는데 유연성을 제공한다. 이들은 프로그래밍 구문상 명확한 구별이 가능해야 하므로 반드시 일반 매개변수 뒤에 위치해야 한다.
| 연산자 | 구문 | 설명 |
|---|---|---|
= |
arg=value |
전달인자가 없으면 기본값 value가 대신 매개변수에 할당된다. |
: |
arg:value |
전달인자 value를 매개변수 arg로 넘겨주며, 매개변수의 순서는 중요하지 않다. |
/* 함수 선언 */
int Function(int arg1, double arg2 = 2.0)
{
return arg1 + arg2;
}
/* 함수 호출 */
Function(1); // 반환: 3
Function(1, 3.14); // 반환: 4 (= 1 + 3.14의 정수만 추출)
Function(arg2: 2.71, arg1: 5); // 반환: 7 (= 5 + 2.71의 정수만 추출)
참조에 의한 전달
매개변수로 인자를 전달하는 방법에는 크게 두 가지가 있다: 값에 의한 전달(pass by value) 그리고 참조에 의한 전달(pass by reference)이 있다. 전자는 데이터의 값만이 매개변수로 전달되는 반면, 후자는 데이터 자체가 매개변수로 전달되어 본래 데이터에도 영향을 미치는 특징을 갖는다. 현재까지 본문에서 다룬 함수들은 전부 값에 의한 전달을 사용하였다.
다음은 C# 프로그래밍 언어에서 참조에 의한 전달을 위해 사용되는 키워드를 소개한다.
-
ref키워드가장 일반적인 참조에 의한 전달이다.
/* 참조에 의한 전달: ref 키워드 */ void Function(ref int arg) { arg *= 2; } int variable = 3; Function(ref variable); Console.WriteLine(variable); // 출력: 6 -
out키워드오로지 초기화되지 않은 변수만 매개변수로 전달될 수 있으며, 함수가 종료되기 전에 해당 매개변수는 반드시 초기화되어야 한다.
/* 참조에 의한 전달: out 키워드 */ void Function(out int arg) { arg *= 2; // [CS0269] Use of unassigned out parameter 'arg' } int variable = 3; Function(out variable); Console.WriteLine(variable); -
in키워드매개변수는 읽기 전용이 되어 변동이 불가능하다.
/* 참조에 의한 전달: in 키워드 */ void Function(in int arg) { arg *= 2; // [CS8331] Cannot assign to variable 'in int' because it is a readonly variable } int variable = 3; Function(in variable); Console.WriteLine(variable);
함수 오버로딩
함수 오버로딩(function overloading)은 동일한 이름 및 반환 자료형을 갖는 함수가 전달받은 인자의 자료형 및 개수에 따라 달리 동작하는 것을 의미한다. 이들은 각 인자 전달의 경우에 따라 제각각의 정의를 갖는다.
/* 오버로딩된 함수 선언 1 */
double Function(int arg1, double arg2) {
return arg1 + arg2;
}
/* 오버로딩된 함수 선언 2 */
double Function(double arg1, double arg2) {
return arg1 - arg2;
}
Function(1, 3.0); // 반환: 4.0
Function(1.0, 3.0); // 반환: -2.0
진입점
진입점(entry point)는 프로그램이 시작되는 부분을 의미하며, C# 프로그래밍 언어의 경우 Main() 함수에서부터 코드가 실행된다. 진입점은 반드시 static 키워드가 명시되어야 하며, 유일해야 하므로 복수의 Main() 함수가 존재하거나 찾지 못하면 요류가 발생하여 컴파일이 불가하다.
class Program
{
/* C# 프로그래밍 언어 진입점: Main() */
static void Main(string[] args)
{
}
}
C# 9.0부터 소개된 최상위 문장은 이를 모두 함축시켜 스크립트를 간략하게 만든다. 최상위 문장에서 별도의
Main()함수를 선언할 수 있으나 이는 절대 진입점으로 동작하지 않는다.
Main() 진입점의 args 매개변수는 터미널 명령창을 통해 전달된 텍스트 데이터를 문자열 배열로 전달받는다.
./app.exe option1 option2
| 매개변수 | args[0] |
args[1] |
|---|---|---|
| 데이터 | option1 |
option2 |
delegate 자료형
delegate 키워드, 일명 대리자(delegate)는 특정 매개변수 및 반환 자료형의 함수를 참조하는 자료형이다. 다시 말해, 함수 자체를 저장하여 호출(invoke)할 수 있는 변수의 “자료형”을 선언하는데 사용된다. 다음은 한 개의 문자열 매개변수를 가지며 반환 자료형이 없는 함수를 위임받을 수 있는 자료형을 지정한다.
/* delegate 자료형 선언 */
delegate void Del(string arg);
delegate 자료형은 지정된 매개변수 및 반환 자료형의 함수만을 위임받을 수 있으며, 그 외에는 컴파일 오류가 발생한다. 해당 자료형의 변수는 언제든지 다른 함수를 할당받아 호출할 수 있다.
종합하자면 C/C++ 프로그래밍 언어의 함수 포인터와 동일한 역할을 수행한다. 다만, 함수 포인터는 해당 함수만을 참조한다면
delegate자료형은 함수가 속해있는 객체를 함께 캡슐화한다.
void Function1(string arg)
{
Console.WriteLine(arg.ToUpper());
}
void Function2(string arg)
{
Console.WriteLine(arg.ToLower());
}
Del handle;
handle = Function1;
handle("Hello World!"); // 출력: HELLO WORLD!
handle = Function2;
handle("Hello World!"); // 출력: hello world!
/* delegate 자료형 선언 */
delegate void Del(string arg);
콜백 함수
콜백 함수(callback function)는 인자로 전달되는 함수이다. 콜백 함수를 전달받는 함수, 일명 호출 함수(calling function)는 블록 내에서 매개변수 호출을 통해 콜백 함수를 실행한다.
여기서 콜백이란, 전달인자로 전달된 함수가 다른 함수에서 언젠가 다시 호출(call back)되어 실행된다는 의미에서 붙여진 용어이다.
아래는 delegate 자료형을 사용한 콜백 함수의 예시이다.
/* 호출 함수 */
double calling(Del function, int arg)
{
// 콜백 함수의 호출
return function(arg, 3.14159);
}
/* 콜백 함수 */
double callback(int arg1, double arg2)
{
return (double)arg1 + arg2;
}
Console.WriteLine(calling(callback, 1));
delegate double Del(int arg1, double arg2);
4.141590
람다 표현식
람다 표현식(lambda expression), 일명 람다 함수(lambda function) 혹은 익명 함수(anonymous function)는 이름이 없는 (즉, 익명) 함수로써 흔히 일회용 함수로 사용된다. 람다 연산자 =>를 통해 선언되지만 그 유형은 크게 두 가지로 나뉘어진다.
-
표현식 람다(expression lambda)
람다 연산자
=>이후에 표현식이 위치하면 평가된 값 혹은 데이터가 반환된다.() => expression; -
문장 람다(statement lambda)
람다 연산자
=>이후에 문장이 위치하면 중괄호{}안에 문장들이 실행된다. 단일 문장일 경우 중괄호를 생략할 수 있으며,return문으로 값 혹은 데이터를 반환할 수 있다.() => { statements; }
람다 연산자로 사용된
=>토큰은 그 외에도 표현식 혹은 단일 문장을 갖는 간단한 함수 선언을 간략화하는 표현식 본문 정의(expression body definition)에도 활용된다.void Function() => Console.WriteLine("Hello World!");
비록 식별자가 필요하지 않는 익명 함수일지라도, 람다 표현식은 재호출을 위해 일반 함수처럼 식별자를 가질 수 있다. 람다 표현식을 수용할 수 있는 대리자는 데이터 반환 여부에 따라 Func<T, TResult> 혹은 Action<T1, T2>를 사용할 수 있으며, 이들은 간편히 var 자료형으로 컴파일러에서 자동 결정하도록 하는 것도 방법이다.
var lambda = (int arg1, char arg2) => $"{arg1}, {arg2}";
/* 동일:
Func<int, char, string> lambda = (arg1, arg2) => $"{arg1}, {arg2}";
*/
Console.WriteLine(lambda(3, 'A')); // 출력: 3, A
재귀 함수
재귀 함수(recursive function)는 스스로를 호출하는 함수이다. 재귀 함수는 반드시 스스로를 호출하는 반복으로부터 탈출하는 기저 조건(base case)이 필요하다. 기저 조건이 없으면 무한 재귀가 발생하는데 프로그램 실행에 기여하는 메모리가 부족하여 충돌이 발생한다.
/* 예제: 펙토리얼 "!" */
int factorial(int arg) {
// 기저 조건: 재귀로부터 탈출하는 조건
if (arg == 1)
return 1;
else
return arg * factorial(arg - 1);
}
클래스
클래스(class)는 객체를 생성하는데 사용자 정의 자료형이다.
객체(object 혹은 instance)는 데이터를 저장할 수 있는 변수와 처리할 수 있는 함수를 하나로 묶은 데이터이다. 객체의 변수와 함수를 통틀어 맴버(member)라고 칭하는데, 이들은 각각 필드(field; 맴버 변수)과 메소드(method; 맴버 함수)라고 불리며 다음과 같이 접근한다.
- 필드:
instance.Field- 메소드:
instance.Method()현재까지 다룬 내용 중에서 객체에 해당되는 데이터로는 문자열 객체와 배열 및 벡터가 있다.
List<int> variable = new() {0, 3, 5, 9}; Console.WriteLine(variable.IndexOf(5)); // "variable" 리스트 객체의 "IndexOf()" 메소드를 사용하여 값 5를 갖는 요소의 인덱스를 반환한다.
클래스는 class 키워드를 사용하여 속성 및 메소드와 함께 선언된다. 클래스로부터 객체를 생성하는 것을 “객체화(instantiation)”라 부르는데, 이때 클래스에 선언된 맴버들은 캡슐화(encapsulation)되어 다음 특징을 갖는다:
- 변수와 함수가 하나의 객체로 결합된다.
- 우연치 않은 수정을 방지하기 위해 변수 및 함수에 대한 직접적인 접근을 외부로부터 제한할 수 있다.
CLASS instance = new CLASS();
Console.WriteLine(instance.Field1); // 출력: 2
Console.WriteLine(instance.Method(1)); // 출력: 4
/* 클래스 선언 */
class CLASS {
/* 필드 맴버 */
public int Field1 = 2;
public double Field2 = 3.14;
/* 메소드 맴버 */
public int Method()
{
return Field1 * Field2;
}
/* 메소드 맴버 (오버로딩) */
public int Method(int arg)
{
return Field1 + Field2 - arg;
}
}
접근 한정자
접근 한정자(access modifier)는 외부 코드 및 상속으로부터 맴버 접근 권한을 지정한다.
| 키워드 | 설명 |
|---|---|
public |
클래스 외부 코드로부터 맴버 접근이 자유롭다. |
private |
클래스 내부에서만 맴버 접근이 가능하다; class 키워드의 기본 접근 한정자이다. |
protected |
맴버 접근이 가능한 외부 코드가 해당 클래스로부터 상속된 파생 클래스로 제한된다. |
internal |
맴버 접근이 가능한 외부 코드가 해당 클래스가 속한 어셈블리로 제한된다. |
생성자
생성자(constructor)는 객체화마다 자동으로 실행되는 특수한 void 자료형 메소드이다. 비록 생성자는 선택사항이지만, 선언한다면 반드시 클래스명과 동일해야 한다. 외부 코드로부터 객체화되기 때문에 생성자를 public 혹은 internal 접근 한정자로 설정한다. 흔히 객체화 단계에서 맴버들을 초기화하는 용도로 사용된다.
CLASS instance = new CLASS(2, 3.14);
/* 클래스 선언 */
class CLASS
{
/* 생성자: 맴버 초기화 */
public CLASS(int arg1, double arg2)
{
Field1 = arg1;
Field2 = arg2;
statements;
}
private int Field1;
private double Field2;
}
생성자는 오버로딩될 수 있어 한 개 이상이 선언될 수 있다. 그 중에서 아무런 전달인자를 받지 않는 생성자를 기본 생성자(default constructor)라고 칭한다.
객체 초기자
객체 초기자(object initializer)는 외부 코드로부터 접근이 가능한 (public, internal 등) 아무런 필드 맴버들을 한 번에 초기화하는데 사용된다. 그러므로 생성자에서 초기화가 필요한 필드마다 데이터를 할당하는 코드를 일일이 기입할 수고를 줄이는 장점을 지닌다. 객체 초기자는 생성자가 실행된 이후에 동작한다.
/* 객체 초기자 */
CLASS instance = new CLASS() { Field1 = 2, Field2 = 3.14 };
종료자
종료자(finalizer), 혹은 소멸자(destructor)는 객체가 메모리로부터 소멸되기 직전에 자동으로 실행되는 특수한 void 자료형 메소드이다. 비록 종료자는 선택사항이지만, 선언한다면 접두부에는 물결표 ~와 함께 반드시 클래스명과 동일해야 한다. 종료자에는 접근 한정자가 설정될 수 없다.
/* 클래스 선언 */
class CLASS {
/* 소멸자 */
~CLASS()
{
statements;
}
}
소멸자는 매개변수를 가질 수 없으므로 오버로딩될 수 없다. 그러므로 클래스는 오로지 하나의 소멸자만 선언할 수 있다.
this 키워드
this 키워드는 객체가 자신의 메모리 주소를 반환하는데 사용된다. 객체의 비정적(non-static) 메소드로부터 자신의 맴버 호출을 this-> 표현식으로 명시적으로 나타낼 수 있어, 흔히 필드 맴버를 매개변수 또는 지역변수와 구분짓는데 활용된다.
/* 클래스 선언 */
class CLASS {
/* 필드 맴버 */
public int Field1 = 2;
public double Field2 = 3.14;
/* 메소드 맴버 */
public int Method() {
return this.Field1 * this.Field2;
}
/* 메소드 맴버 (오버로딩) */
public int Method(int arg) {
return this.Field1 + this.Field2 - arg;
}
}
정적 맴버
정적 맴버(static member)는 클래스로부터 생성된 객체의 개수와 무관하게 오로지 하나의 데이터만 존재하여 공유되는 static 키워드로 명시된 맴버이다. 해당 유형의 맴버는 객체화가 필요없이 클래스로부터 직접 호출이 가능하다.
파이썬 프로그래밍 언어와 비교하자면 클래스 속성 및 메소드에 대응한다.
객체지향에 해당하는 C# 프로그래밍 언어는 정적 필드 맴버가 전역 변수의 대안으로 사용된다.
Console.WriteLine(CLASS.Field); // 출력: 7
/* 클래스 객체화 */
CLASS instance = new CLASS();
CLASS.Method(2);
Console.WriteLine(instance.Field); // 출력: 9
/* 클래스 선언 */
class CLASS
{
/* 정적 필드 선언 */
public static int Field = 7;
/* 정적 메소드 선언 */
public static void Method(int arg) => CLASS.Field += arg;
}
정적 클래스
정적 클래스(static class)는 정적 맴버만을 가지는 객체화가 불가한 클래스이다. 해당 유형의 클래스는 객체를 생성하기보다 유사한 목적의 기능성과 데이터를 하나로 묶는 역할을 한다. 이는 사실상 일반 클래스를 전부 정적 맴버로 선언하는 것과 동일하지만, 정적 클래스를 사용하므로써 불필요한 객체의 생성을 방지할 수 있다. 대표적인 예시로 터미널 입출력 등을 제공하는 System.Console 클래스가 있다.
/* 클래스 객체화 */
CLASS instance = new CLASS(); // [CS0712] Cannot create an instance of the static class 'CLASS'
/* 정적 클래스 선언 */
static class CLASS
{
public static int Field = 7;
public static void Method(int arg) => CLASS.Field += arg;
}
정적 생성자
정적 생성자(static constructor)는 정적 클래스의 맴버가 호출될 때마다 실행되는 생성자이다. 정적 생성자는 선택사항이며, 매개변수를 가질 수 없으므로 오버로딩될 수 없다. 그러므로 정적 클래스는 오로지 하나의 정적 생성자만 선언할 수 있다.
/* 정적 클래스 선언 */
static class CLASS
{
/* 정적 생성자 선언 */
public static CLASS()
{
statements;
}
}
partial 키워드
partial 자료형은 하나의 클래스를 분할하여 선언할 수 있도록 한다. 이는 심지어 서로 다른 파일 간에도 적용이 가능하여, 윈도우 폼(WinForms) 혹은 WPF(Windows Presentation Foundation) 등의 규모가 큰 C# 프로젝트에 흔히 사용된다.
/* partial 클래스 */
partial class CLASS
{
int Field;
}
partial class CLASS
{
void Method()
{
...
}
}
상속
상속(inheritance)은 기반 클래스(base class)가 파생 클래스(derived class)에게 필드 및 메소드 맴버를 제공하는 행위이다. 기반 클래스와 파생 클래스에 동일한 이름의 맴버가 존재할 경우, 기반 클래스의 맴버는 파생 클래스에 의해 묻힌다. 파생 클래스는 여러 기반 클래스로부터 동시에 상속받을 수 없는 대신, 대안으로 인터페이스를 사용할 수 있다.
/* 클래스 객체화 */
DERIVEDCLASS instance = new DERIVEDCLASS();
Console.WriteLine("{0} {1} {2}", instance.Field1, instance.Field2, instance.Field3);
Console.WriteLine(instance.Method(2, 3));
/* 기반 클래스 선언 */
class BASECLASS
{
public BASECLASS() => Console.WriteLine("생성자: 기반 클래스");
~BASECLASS() => Console.WriteLine("종료자: 기반 클래스");
public int Field1 = 3;
public string Field2 = "C#";
public int Method(int arg1, int arg2) => arg1 + arg2;
}
/* 파생 클래스 선언 */
class DERIVEDCLASS : BASECLASS
{
public DERIVEDCLASS() => Console.WriteLine("생성자: 파생 클래스");
~DERIVEDCLASS() => Console.WriteLine("종료자: 파생 클래스");
public string Field2 = "Hello World!";
public bool Field3 = true;
public int Method(int arg1, int arg2) => arg1 * arg2;
}
생성자: 기반 클래스
생성자: 파생 클래스
3 Hello World! 1
6
소멸자: 파생 클래스
소멸자: 기반 클래스
만일 의도적으로 기반 클래스의 맴버를 숨기려고 한다면
new키워드를 사용하여 오버라이딩과 확실히 구분짓도록 한다./* 파생 클래스 선언: 올바른 맴버 숨기기 */ class DERIVEDCLASS : BASECLASS { ... public new string Field2 = "Hello World!"; ... public new int Method(int arg1, int arg2) => arg1 * arg2; }
base 키워드
base 키워드는 파생 클래스로부터 기반 클래스의 맴버를 접근하기 위해 사용되며, 다음과 같은 용도로 활용된다 (단, 정적 메소드에서 사용 불가).
-
base.표현식파생 클래스로부터 원하는 기반 클래스 맴버를 호출한다.
DERIVEDCLASS instance = new(); instance.Method(); // 출력: Hello, World! /* 기반 클래스 선언 */ class BASECLASS { public void Method() { Console.Write("Hello, "); } } /* 파생 클래스 선언 */ class DERIVEDCLASS : BASECLASS { public void Method() { // 기반 클래스 메소드 호출 base.Method(); Console.WriteLine("World!"); } } -
:base()표현식객체화 과정에서 호출할 기반 클래스의 생성자를 선택한다.
DERIVEDCLASS instance1 = new(); // 출력: 클래스 생성자 1! DERIVEDCLASS instance2 = new(3); // 출력: 클래스 생성자 3? /* 기반 클래스 선언 */ class BASECLASS { protected int value; public BASECLASS() => value = 1; public BASECLASS(int arg) => value = arg; } /* 파생 클래스 선언 */ class DERIVEDCLASS : BASECLASS { public DERIVEDCLASS() : base() => Console.WriteLine($"클래스 생성자 {value}!"); public DERIVEDCLASS(int arg) : base(arg) => Console.WriteLine($"클래스 생성자 {value}?"); }
sealed 한정자
sealed 한정자는 클래스 혹은 그 맴버가 파생 클래스에 상속되지 못하도록 제한한다.
sealed int Field = 0;
다형성
다형성(polymorphism)은 “여러가지의 형태를 가진”이란 사전적 의미를 가지며, 프로그래밍 언어에서는 상황과 용도에 따라 달리 동작하는 것을 가리킨다.
- 컴파일타임 다형성(compile-time polymorphism): 컴파일 시 이루어지는 다형성 (일명 정적 다형성; static polymorphism)
- 런타임 다형성(run-time polymorphism): 프로그램 실행 시 이루어지는 다형성 (일명 동적 다형성; dynamic polymorphism)
이전 장에서 소개한 적이 있는 함수 오버로딩은 컴파일타임 다형성 중 하나이다.
연산자 오버로딩
연산자 오버로딩(operator overloading)은 연산자가 특정 클래스 및 해당 객체에서 어떻게 동작할 지 operator 키워드로 재정의하는 컴파일타임 다형성 중 하나이다. 연산자 오버로딩에서는 public 및 static 한정자가 필수이며, 한 개의 연산자에 전달받은 인자의 자료형 및 개수에 따라 여러 선언이 가능하다. 단, [] 와 같이 오버로딩이 불가한 연산자도 존재하므로 유의하도록 한다.
CLASS obj1 = new(2), obj2 = new(3);
CLASS instance = obj1 + obj2;
Console.WriteLine(!instance);
/* 클래스 선언 */
class CLASS {
public CLASS(int arg) => Field = arg;
public int Field;
/* 연산자 오버로딩: + 선언 */
public static CLASS operator +(CLASS arg1, CLASS arg2) => new(arg1.Field + arg2.Field);
/* 연산자 오버로딩: 단항 ! 선언 */
public static string operator !(CLASS arg1) => $"{arg1.Field}!";
}
5!
메소드 오버라이딩
메소드 오버라이딩(method overriding)은 상속된 기반 클래스의 맴버 함수 (일명 메소드)를 파생 클래스에서 재정의하는 런타임 다형성이다.
동일한 이름 하에 선언된 여러 함수 중에서 하나를 택하여 실행하는 메소드 오버로딩과 전혀 다른 개념이다.
오버라이딩이 되는 기반 클래스의 메소드는 virtual 한정자로 선언된 가상 메소드(virtual method)이다. 선언된 가상 메소드는 기반 클래스를 객체화하여 곧바로 사용할 수 있으며, 또는 파생 클래스에서 오버라이딩을 하지 않은 채 객체화하여 사용될 수 있다. 오버라이딩을 하려면 반드시 override 한정자를 명시해야 하며, 그렇지 않으면 상속에서 보여준 예시 코드처럼 단순히 파생 클래스에 묻힐 뿐이다.
/* 기반 클래스 선언 */
class BASECLASS
{
/* 가상 함수 선언 */
public virtual void method()
{
}
}
/* 파생 클래스 선언 */
class DERIVEDCLASS : BASECLASS
{
/* 메소드 오버라이딩 */
public override void method()
{
}
}
기반 클래스의 가상 메소드 중에서 abstract 한정자로 선언된 추상 메소드(abstract method)로 선언될 수 있으며, 이는 블록 {}이나 => 토큰을 지니지 않은 빈 메소드이다. 그리고 최소한 한 개 이상의 추상 메소드를 갖는 클래스를 추상 클래스(abstract class)라고 부른다.
/* 추상 클래스 선언 */
abstract class BASECLASS
{
/* 추상 메소드 선언 */
public abstract void method();
}
추상 메소드는 아무런 정의가 없으므로 추상 클래스는 객체화가 불가하며, 오로지 상속 목적으로만 사용된다. 동일한 맴버 구조를 갖는 파생 클래스들을 생성해야 한다면 추상 클래스를 사용하여 효율을 높일 수 있다.
프로퍼티
프로퍼티(property)는 하나의 속성을 get와 set 영역으로 나누어 데이터 숨기기(data hiding)을 지원한다.
| 접근자 | 설명 |
|---|---|
get |
프로퍼티의 데이터를 반환한다. |
set |
프로퍼티에 데이터를 할당한다. |
init |
프로퍼티를 객체 초기자로부터 초기화한다 (C# 9.0부터 소개). |
프로퍼티는
set와init접근자를 동시에 가질 수 없다: 전자는 재할당이 가능하지만, 후자는 초기화 이후에 변동이 불가하다.
필드를 나누므로써 수정되어서는 안될 민감한 코드를 set 혹은 init 접근자에 숨기고 get 접근자만을 통해서 데이터를 반환한다. 선언된 형태는 메소드와 유사하지만 실제로 사용할 때는 소괄호 () 없이 필드처럼 사용된다. 프로퍼티는 오로지 하나의 전달인자만 받을 수 있으며 value 키워드를 통해 프로퍼티로 전달된다.
CLASS instance = new CLASS();
instance.Property = 3;
Console.WriteLine(instance.Property); // 출력: 16
/* 클래스 선언 */
class CLASS
{
private int property;
/* 프로퍼티 선언 */
public int Property
{
get => property * property;
set => property = value + 1;
/* 동일:
get { return property; }
set { property = value; }
*/
}
}
자동 구현 프로퍼티
자동 구현 프로퍼티(auto-implemented property)는 간략화된 프로퍼티이지만 get 및 set 영역의 코드를 수정할 수 없다.
public int Property { get; set; }
/* 동일:
private int property;
public int Property
{
get => property;
set => property = value;
}
*/
인덱서
인덱서(indexer) 맴버는 객체를 배열처럼 사용할 수 있게 한다. 프로퍼티와 유사하게 get 및 set 접근자를 사용하고, 데이터를 private 필드에 선언된 컬렉션에 저장한다.
CLASS instance = new CLASS();
instance[0] = 1;
instance[1] = 3;
/* 클래스 선언 */
class CLASS
{
/* 인덱서를 위한 컬렉션 */
private int[] arr = new int[2];
/* 인덱서 선언 */
public int this[int index]
{
get => arr[index];
set => arr[index] = value;
}
}
사용자 정의 자료형
사용자 정의 자료형(custom type)은 흔히 int, float, char 등의 기존하는 자료형으로부터 개발자가 특정 목적을 위해 제작한 새로운 자료형이다. 정의된 자료형은 또 다른 사용자 정의 자료형을 구성하는데 사용될 수 있다. 대표적인 예시로 클래스가 있으며, 본 장에서는 그 외에 C# 프로그래밍 언어가 제공하는 다양한 사용자 정의 자료형을 소개한다.
구조체
구조체(structure)는 자료형과 무관하게 필드 맴버를 하나의 단일 데이터로 통합시킨 struct 키워드로 선언된 사용자 정의 자료형이다.
/* 구조체 선언 */
struct STRUCTURE
{
/* 필드 맴버 선언 */
public char Field1;
public int Field2;
/* 메소드 맴버 선언 */
public string method() => $"{Field1}, {Field2}";
}
선언된 구조체로부터 new 연산자를 통해 객체화하며, 필드 맴버를 초기화하는 방법으로 (1) 생성자를 선언하거나 (2) 객체 초기자를 사용한다.
/* 구조체 객체화 및 초기화 */
STRUCTURE variable = new STRUCTURE() { Field1 = 'A', Field2 = 3 };
클래스와 상당히 유사한 특징을 지니지만, 이 둘은 확실한 차이점이 존재한다.
| 자료형 | 유형 | 상속 허용 여부 | 용도 |
|---|---|---|---|
| 클래스 | 참조 자료형 | ⭕ | 기능성 제공 위주의 자료형 |
| 구조체 | 값 자료형 | ❌ | 소규모의 데이터 중심 자료형 |
레코드
레코드(record)는 C# 9.0에 처음으로 소개되었으며, 데이터 캡슐화에 추가 기능성을 제공하는 참조 자료형으로 record (혹은 record class) 키워드로 선언된다. 레코드는 본래 데이터 불변(immutable) 모델을 지원하기 위한 자료형으로 일반 프로퍼티 혹은 위치 매개변수(positional parameters) 레코드 전용 구문으로 선언된다.
일반 프로퍼티 구문에서
set접근자를 사용하거나, 혹은record struct키워드를 사용하여 데이터 변경이 가능한 가변(mutable) 속성을 맴버로 갖는 레코드를 선언할 수 있다.
var instance = new RECORD() { Property1 = 'A', Property2 = 3 };
/* 일반 프로퍼티 구문 */
record RECORD
{
public char Property1 { get; init; } = default!;
public int Property2 { get; init; } = default!;
}
var instance = new RECORD('A', 3);
/* 위치 매개변수 구문 */
record RECORD(char Property1, int Property2);
비록 레코드는 참조 자료형이지만 (record struct는 값 자료형에 해당), 데이터 위주의 유용한 기능들이 내재되어 있다.
-
레코드 객체의 자료형 및 저장된 값이 동등한지
==연산자로 확인할 수 있다. 클래스의 경우에는 메모리에 동일한 객체를 참조하고 있을 때에만 동등하다고 판단하며, 구조체는 자료형과 데이터를 비교하려면Object.Equals(Object)메소드를 활용하거나 연산자 오버로딩이 필요하다는 점을 빗대어 보면 레코드는 자료 비교에서 매우 유용하다. -
레코드 객체 자체를 출력하면 필드 및 프로퍼티에 저장된 값이 표시된 형식으로 나타난다.
Console.WriteLine(new RECORD('A', 3)); /* 출력: RECORD { Property1 = A, Property = 3 } */ -
클래스와 마찬가지로 상속이란 개념이 동일하게 적용된다 (단,
record struct키워드는 제외)./* 기반 레코드 선언 */ record BASERECORD(char Property1, int Property2); /* 파생 레코드 선언 */ record DERIVEDRECORD(char Property1, int Property2, bool Property3) : BASERECORD(Property1, Property2);
with 표현식
with 표현식은 객체 초기자를 활용하여 일부 프로퍼티 및 필드 맴버만을 수정한 채 복사본을 생성한다. 본래 레코드에만 한정되었으나, 현재는 구조체에도 사용할 수 있다.
RECORD instance = new RECORD(3, 'A', true);
Console.WriteLine(instance with { Property2 = 'C', Property3 = false });
/* 출력:
RECORD { Property1 = 3, Property2 = C, Property3 = False }
*/
인터페이스
인터페이스(interface)는 클래스, 구조체, 그리고 레코드 측에서 코드 구현이 반드시 충족되어야 할 맴버들을 제공하는 “계약형” 자료형이다. 인터페이스는 객체화 될 수 없으며, 클래스와 같은 타 사용자 정의 자료형에 인터페이스를 구성요소로써 제공하는 행위를 도입(implement)라고 하는데 이는 동일한 자료형 간에 맴버를 전달하는 상속과 다른 개념이다. 이와 별개로 인터페이스는 다른 여러 인터페이스로부터 상속받을 수 있다.
인터페이스 내에 선언될 수 있는 맴버는 제한적이며, 아래의 표는 C# 버전에 따른 인터페이스에 선언될 수 있는 맴버 유형을 나열한다.
| 버전 | 맴버 |
|---|---|
| C# 8.0 이전 | 메소드, 프로퍼티, 인덱서, 이벤트 |
| C# 8.0 이후 | 상수, 연산자, 정적 맴버, 정적 생성자 |
인터페이스는 기본적으로 public 접근 한정자가 맴버에 적용되는데, 만일 다른 접근 한정자를 지정하려면 별도로 명시해야 한다.
CLASS instance = new CLASS();
instance.Property = 3;
instance.Method(); // 출력: 10
/* 인터페이스 선언 */
interface INTERFACE1
{
int Property { get; set; }
}
interface INTERFACE2
{
void method();
}
/* 인터페이스 도입 */
class CLASS : INTERFACE1, INTERFACE2
{
private int property;
public int Property
{
get => property + 1;
set => property = value * value;
}
public void method() => Console.WriteLine("{0}", Property);
}
만일 인터페이스의 멤버 중 하나라도 코드가 구현되지 않았더라면 컴파일러 오류가 발생한다.
인터페이스 안에 맴버가 구현될 수 있으나, 이는 오버라이딩이 되지 않은 가상 메소드처럼 인터페이스에 정의된 코드를 대신 실행할 수 있도록 한다 (일명 기본 인터페이스 메소드; default implementation). 그러므로 인터페이스를 도입한 사용자 정의 자료형에서 해당 맴버에 대한 코드 구현이 없어도 컴파일러 오류가 발생하지 않는다.
INTERFACE instance = new CLASS(); instance.Method(); // 출력: Hello World! /* 인터페이스 선언 */ interface INTERFACE { void Method() => Console.WriteLine("Hello World!"); } /* 인터페이스 도입 */ class CLASS : INTERFACE { }
제네릭
제네릭(generic)은 자료형을 나중에 지정하여 사용할 수 있는 함수 및 클래스 틀이며 식별자 뒤에 <> 구문과 함께 선언된다. 유사한 코드를 수행하는 함수 및 클래스를 각 자료형 조합마다 별도로 정의하지 않고 제네릭으로 통합시키므로써 관리가 편해지고 작업효율을 높일 수 있다. 대표적인 예시로 제네릭 컬렉션들이 있다.
제네릭 메소드
제네릭 메소드(generic method)는 자료형 지정이 가능한 메소드이다. 선언된 제네릭 메소드를 사용하기 위해서는 홑화살괄호 <> 안에 자료형을 지정하여 객체화한다.
/* 제네릭 메소드 객체화 */
Method<int, double>(1, 3.14);
/* 제네릭 메소드 선언 */
U Method<T, U>(T arg1, U arg2)
{
...
}
제네릭 클래스
제네릭 클래스(generic class)는 자료형 지정이 가능한 클래스이다. 선언된 제네릭 클래스를 사용하기 위해서는 홑화살괄호 <> 안에 자료형을 지정하여 객체화한다.
/* 제네릭 클래스 객체화 */
CLASS<int, double> instance = new() { Field1 = 1, Field2 = 3.14 };
/* 제네릭 클래스 선언 */
class CLASS<T, U>
{
T Field1;
U Field2;
U Method(T arg1, U arg2)
{
...
}
}
제네릭 인터페이스
제네릭 인터페이스(generic interface)는 자료형 지정이 가능한 인터페이스이다. 선언된 제네릭 인터페이스를 사용하기 위해서는 홑화살괄호 <> 안에 자료형을 지정하여 도입한다.
/* 제네릭 인터페이스 선언 */
interface INTERFACE<T, U>
{
T Property { get; set; }
U Property { get; set; }
U Method(T arg1, U arg2);
}
/* 제네릭 인터페이스 도입 */
class CLASS<T, U> : INTERFACE<T, U>
{
...
}
열거형
열거형(enumeration)은 열거된 항목, 일명 열거형 맴버(enum member)들을 정수로 순번을 매기는 enum 키워드로 선언된 자료형이다. 맴버들은 기본적으로 정수 0부터 시작하여 다음 맴버마다 1만큼 증가한다. 맴버에 할당 연산자 =로 정수를 직접 지정하지 않는 이상, 이러한 규칙은 계속 유지된다. 그러나 열거형 선언 이후에 열거형 맴버를 추가하거나, 혹은 맴버의 값을 바꾸는 건 불가하다.
/* 열거형 선언 */
enum ENUMERATION
{
member1, // = 0
member2, // = 1
member3 = 7, // = 7
member4 // = 8
}
열거형이 가질 수 있는 정수의 범위는 기본적으로
int로 지정되어 있다. 만일 이를 정수 0 ~ 255까지만 수용할 수 있는byte로 변경하려면 다음과 같이 기입한다.enum ENUMERATION : byte { ... }
열거형 자료형으로 선언된 변수는 오로지 주어진 열거형 맴버만을 할당받을 수 있다. 해당 맴버들은 열거형의 정적 맴버인 마냥 호출되는데, 이러한 국부적 영역범위 특성은 서로 다른 열거형에도 동명의 맴버들을 선언할 수 있도록 한다. 만일 타 열거형의 열거자나 범위 외의 정수로 할당하려면 자료형 변환이 필요하다.
/* 열거형 변수 선언 */
ENUMERATION variable = ENUMERATION.member1;
예외 처리
예외(exception)는 잘못된 코딩이나 입력으로 인해 프로그램상 실행 불가능 코드 오류이다. 컴파일러에서 걸러지는 오류가 아니기에 정상적인 프로그램이 실행될 수 있으나, 예외가 발생하면 프로그램은 즉시 중단된다. 예외 처리는 실행된 프로그램이 예외로 인해 프로그램 실행이 중단되는 것을 방지하여 안정적으로 실행되는 것을 주목표로 한다.
try-catch 예외 처리문
try-catch 쌍은 예외를 감지하고 발생한 예외 유형에 따라 기입된 코드를 실행하여 처리된다. 예외 처리된 파이썬 프로세스는 도중에 중단되지 않고 계속 실행된다.
-
try문블록 내의 코드에 예외가 발생하는지 확인한다. 예외가 발생하였을 시, 나머지 코드는 실행되지 않고 예외 종류에 따라 해당하는
catch블록으로 넘어간다. -
catch문try블록에서 예외가 발생하면 실행되는 코드를 포함한다. 하나의try블록에 여러catch블록을 사용하여 다양한 예외에 대비할 수 있다. 만일catch블록이 없으면 컴파일 오류가 발생한다 (컴파일 오류는 예외가 아니다).
try
{
statements;
}
catch(IndexOutOfRangeException e)
{
// 예외 유형: 범위를 벗어난 요소 접근
}
catch(DivideByZeroException e)
{
// 예외 유형: 숫자를 0으로 나누기
}
catch(Exception e)
{
// 예외 유형: 모든 유형의 예외 처리
}
finally 블록
finally 블록은 try 블록에서의 예외 발생 여부와 무관하게 마지막에 무조건 실행되는데, 이러한 특성을 활용하여 try-finally 혹은 try-catch-finally 조합으로 예외 처리문에서 할당된 리소스를 정리하는데 사용된다.
throw 키워드
throw 키워드는 프로그램 실행 도중에 예외 발생을 알리는 역할을 담당하며, 아래 두 예시 코드는 throw 키워드의 대표적인 활용법이다.
-
의도적 예외 발생
try블록 내에서 의도적으로 예외를 발생시키는데 사용된다. 함수나 자료형을 설계되지 않은 방식으로 접근하여 발생할 수 있는 문제를 원천적으로 방지하기 위해 일부러 오류를 발생시켜 프로세스 실행을 즉시 중단시키는 용도로 활용된다.try { throw new IndexOutOfRangeException("ERROR!"); Console.WriteLine("Hello World!"); // 예외 발생으로 실행되지 않음! } catch(Exception e) { Console.WriteLine(e); }System.IndexOutOfRangeException: ERROR! at Program.<Main>$(String[] args) in D:\Workspace\Csharp\Experiment\Program.cs:line 3 -
예외 건네주기
try-catch예외 처리문에서 감지한 예외는 또 다른 예외 처리문으로 넘겨줄 수 있다.void Function(int arg) { try { var variable = 100 / arg Console.WriteLine(variable); } catch(Exception e) { throw; // 예외 건네주기: Function() -> Main() } } try { Function(0); // 예외 건네받기: Function() -> Main() } catch(Exception e) { Console.WriteLine(e.Message); }Attempted to divide by zero.
파일 관리
여러 데이터를 C# 프로그래밍 언어로 개발된 프로세스에 전달하거나, 혹은 데이터를 외부로 출력하기 위해 파일을 불러와 read 혹은 write 하여 처리할 수 있다. 본 장은 C# 프로그래밍 언어에서 파일을 관리하는 방법에 대하여 소개한다. 외부 파일을 읽고 쓰기 위해서 System.IO.File 클래스를 활용한다.
절대경로 및 상대경로
컴퓨터에는 두 종류의 경로 탐색법이 존재한다.
- 절대경로(absolute path): 시스템의 루트경로(예. 윈도우의
C:\혹은 리눅스의/)로부터 시작하여 탐색하는 방식이다. - 상대경로(relative path): 실행되고 있는 프로세스의 현 위치를 기준으로 경로를 탐색하는 방식이다.
경로를 지정할 때에는 백슬래시 두 개 \\로 폴더 및 파일을 구분한다. 하나만 사용하면 탈출 문자가 되어 원치 않은 텍스트 연산이 수행될 수 있다.
파일 생성
C# 프로그래밍 언어에서 텍스트 기반 파일을 File.Create() 메소드로 파일을 생성할 수 있다.
var file = File.Create("path\\filename.txt");
파일 읽기
C# 프로그래밍 언어에서 텍스트 기반 파일을 File.ReadAllText() 메소드로 파일 내용을 곧바로 읽을 수 있다.
string output = File.ReadAllText("path\\filename.txt");
파일 쓰기
C# 프로그래밍 언어에서 텍스트 기반 파일을 File.WriteAllText() 메소드로 파일 내용을 곧바로 작성할 수 있다. 파일이 이미 존재하면 기존의 내용은 덮어쓴다.
File.WriteAllText("path\\filename.txt", "Hello World!");