소개
파이썬(Python)은 웹 프로그래밍, 과학연구, 인공지능을 포함한 수많은 영역에서 응용 가능한 다중 패러다임 고급 프로그래밍 언어이다. 파이썬은 다른 프로그래밍 언어에 비해 매우 간편하여 프로그래밍 입문자에게 적합하고 커뮤니티가 매우 건재하다. 또한 넘파이, 텐서플로우, OpenCV 등의 다양한 서드 파티 라이브러리 생태계가 잘 갖춰져 있어 광범위한 활용도를 보여주는 강력한 프로그래밍 언어이다.
인터프리터
파이썬 프로그래밍 언어는 인터프리트 언어(interpreted language)이다. 버전은 크게 파이썬 2와 파이썬 3으로 분류되는데, 전자는 2020년 1월 1일부로 서비스가 종료되었다. 파이썬 1이라는 것도 존재하나, 가장 최신 버전 1.6.1이 2000년에 출시된 점을 고려하면 호환성과 실용성이 매우 떨어진다. 그러므로 본문은 파이썬 3을 위주로 프로그래밍을 설명한다.
파이썬 버전은 X.Y.Z 서식으로 매겨진다:
| 버전 | 설명 | 비고 |
|---|---|---|
X 메이저 버전 | 호환이 불가할 정도의 상당한 변화를 거친 업그레이드 | 파이썬 2와 3 분류 |
Y 마이너 버전 | 새로운 기능이 추가될 때마다 증가하는 업데이트 | 마이너 버전 하위호환 보장 |
Z 마이크로 버전 | 버그 수정 및 유지관리 패치 | 안정성 척도 |
프로젝트에 활용될 서드 파티 라이브러리나 소프트웨어 연동에서 발생할 수 있는 호환성 문제를 사전에 방지하기 위해 인터프리터 버전을 신중히 선택해야 한다. 만일 단순히 프로그래밍 언어 공부가 목적이면 가장 최신 버전을 설치하여도 무방하다. 단, 인터프리터는 개발 환경 관리를 위해 버전 업데이트 기능이 자체적으로 결여되어 있다. 새로 출시된 버전을 설치하려면 해당 인터프리터를 별도로 설치해야 한다.
아래는 대표적인 파이썬 인터프리터 일부를 나열한다.
- C파이썬: C 프로그래밍 언어로 개발된 가장 널리 쓰이는 최초의 파이썬 인터프리터
- 자이썬: Java 프로그래밍 언어로 개발된 파이썬 인터프리터
- 아이언파이썬: C# 프로그래밍 언어로 개발된 파이썬 인터프리터
인터프리터 설치
파이썬을 실행하기 위해서는 두 가지 프로그램이 필요하다: (1) 인터프리터(다운로드) 그리고 (2) 통합 개발 환경이다. 리눅스와 macOS는 기본적으로 파이썬 2와 3 인터프리터가 설치되어 있으나, 다른 특정 버전을 원하면 새로 설치해야 한다. 본 장에서는 파이썬 인터프리터와 IDE의 설치 및 연동을 통해 파이썬과 같은 인터프리터 언어가 어떻게 동작하는지 이해를 돕는다.
윈도우 운영체제에서 인터프리터를 설치하는 방법에는 두 가지가 있다:
- 압축파일 (embeddable zip file): 파이썬 인터프리터를 구성하는 파일 전체가 압축된 상태로 존재한다.
- 설치 프로그램 (executable installer): 인터프리터를 설치하는
.EXE확장자 프로그램이다.
일부 윈도우 파이썬 인터프리터는 32비트 및 64비트 빌드가
x86및x86-64로 표시되어 있다. 그러나 x86은 인텔 프로세서라는 특정 아키텍처를 가리키기 때문에, ARM64 아키텍처를 사용하는 윈도우에서는 설치에 제약이 존재하였다. 버전 3.9.1부터는 윈도우 ARM64 지원이 공식화되며 x86-64와 함께 64비트 설치 파일로 통합되었다.
인터프리터 설치 프로그램을 실행하면 아래와 같은 화면이 나타난다.
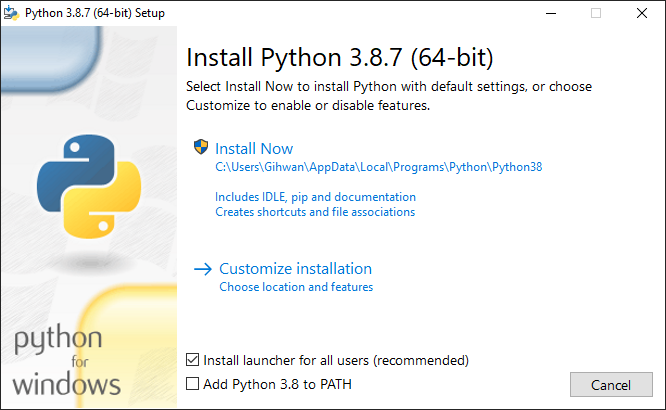
설치 화면에 있는 “Add Python 3.x to PATH” 옵션은 환경 변수(environment variable) 설정 여부를 의미한다: 윈도우의 명령 프롬프트(Command Prompt)나 PowerShell, 리눅스의 터미널 등으로부터 파이썬을 실행할 수 있도록 한다. 필수는 아니지만 차후 파이썬 커뮤니티에서 유용하게 사용되는 패키지를 설치하려면 터미널이 필요하므로 환경 변수 설정을 적극 권장한다. 설치 당시에 해당 옵션을 선택하지 않아도 방법만 알면 재설치 필요없이 손쉽게 설정할 수 있다.
설치 화면에서 “Install Now”를 눌러 인터프리터 설치를 진행하고, 설치가 완료되면 파이썬을 곧바로 실행할 수 있다.
사용자 지정 설치
파이썬을 다른 경로에 설치하거나 오로지 인터프리터만 설치하고 싶다면 “Customize installation”을 클릭해 설치할 내용물을 선택할 수 있다. 가장 먼저 나타나는 “Optional Features” 화면은 인터프리터 동작에 영향을 주지 않는 부가적 설치 사항을 다룬다.
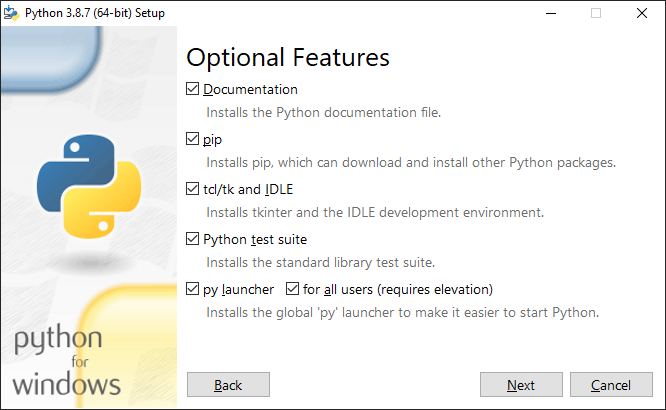
| 옵션 | 설명 |
|---|---|
| Documentation | 파이썬 문서 파일 |
| pip | 파이썬 패키지 관리 소프트웨어 |
| tcl/tk and IDLE | 파이썬으로 프로그램 GUI 제작도구와 코드 편집기 |
| Python test suite | 파이썬 프로그램 동작을 시험하는 프레임워크 |
| py launcher | 파이썬 인터프리터 관리 프로그램 |
필자는 pip와 py launcher만은 반드시 설치한다. 나머지 옵션들은 사용하지 않으며, 사용자 인터페이스를 가진 프로그램을 만든다 하더라도 대표적인 GUI 프레임워크 중 하나인 PySide2를 사용하기 때문에 tcl/tk가 필요하지 않다. 코드 편집기 또한 IDLE보다 편한 것을 곧 소개할 예정이다.
다음에 나타나는 “Advanced Options” 화면은 실질적으로 인터프리터 동작에 영향을 미칠 수 있는 고급 옵션들이다.
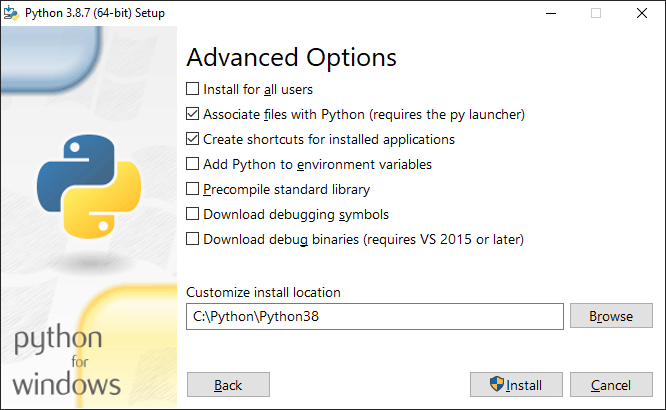
여기서 Download debug binaries (requires VS 2015 or later)는 “디버깅 라이브러리 다운로드” 여부를 묻는데, 이를 필요로 하는 경우로써 OpenCV 라이브러리를 생성할 때가 있다. 하지만 파이썬을 프로그래밍 입문 언어로 배우는 초급자의 입장에서 위의 선택사항들은 공부에 지장을 주지 않아 무시하여도 된다.
통합 개발 환경
통합 개발 환경(integrated development environment; IDE)은 최소한 프로그래밍 언어의 소스 코드 편집, 프로그램 빌드, 그리고 디버깅 기능을 제공하는 소프트웨어 개발 프로그램이다. 인터프리터는 파이썬 코드를 실행하는 소프트웨어이지만, 파이썬 코드 편집기가 아니다. 그러므로 파이썬 코드를 편집하고 곧바로 프로그램으로 실행하여 문제가 발생하면 검토할 수 있는 IDE가 절대적으로 필요하다.
비주얼 스튜디오 코드
비주얼 스튜디오 코드(다운로드), 일명 VS Code는 마이크로소프트에서 개발한 무료 소스 코드 편집기이다. 비록 기술적으로 IDE는 아니지만, 파이썬 확장도구(다운로드)를 설치하여 인터프리터를 불러오면 파이썬 실행 및 디버깅이 모두 가능한 IDE 역할을 수행한다. 확장도구를 설치하였으면 F1 키를 눌러 Python: Select Interpreter을 입력한다. 컴퓨터에 설치된 파이썬 인터프리터가 자동으로 나열되며 사용할 인터프리터를 선택한다.
VS Code는 두 가지의 실행 방법이 있다: 일반 실행 모드(Ctrl+F5)와 디버그 모드(F5)이다. 디버그(debug)는 프로그램에 발생한 문제를 해결하는 행위로, IDE에서 각 줄의 코드마다 어떠한 변화가 생겼는지 혹은 얼만큼의 시스템 리소스를 소모하는지 등을 확인할 수 있는 정보를 제공한다. 디버깅 목적이 아니면 일반 실행 모드를 사용하는 것을 권장한다.
구문
구문(syntax)은 프로그래밍 언어에서 문자 및 기호들의 조합이 올바른 문장 또는 표현식을 구성하였는지 정의하는 규칙이다. 특히 파이썬은 가독성을 매우 중요하게 여기어 “파이썬의 선(Zen of Python)”이란 프로그래밍 철학을 추구하고, 이에 부합한 구문을 파이썬다운(Pythonic) 코드라고 칭한다.
다음은 파이썬 프로그래밍 언어에서 구문에 관여하는 요소들을 소개한다:
-
표현식(expression)
값을 반환하는 구문적 존재를 가리킨다. 표현식에 대한 결과를 도출하는 것을 평가(evaluate)라고 부른다.
2 + 3 # 숫자 5를 반환 2 < 3 # 논리 참을 반환 -
아톰(atom)
표현식을 구성하는 가장 기본적인 요소이며, 대표적으로 식별자(identifier)와 리터럴(literal)이 있다.
variable # 식별자 2 # 정수 리터럴 -
문장(statement)
실질적으로 무언가를 실행하는 구문적 존재를 가리킨다: 흔히 하나 이상의 표현식으로 구성되지만,
break및continue와 같이 독립적으로 사용되는 문장도 있다. 파이썬 프로그래밍 언어는 기본적으로 줄바꿈(newline)을 기준으로 문장을 분별한다. 아래 기호는 파이썬의 프로그래밍 문장과 줄바꿈을 유연하게 활용할 수 있도록 도와준다.- 세미콜론
;: 여려 문장을 하나의 줄에 한꺼번에 기입하기 위해 사용된다. - 백슬래시
\: 하나의 긴 문장을 연속의 여러 줄로 나누어서 나타내기 위해 사용된다.
variable = 2 + 3 # 숫자 5를 "variable" 변수에 초기화 if 2 < 3: statement # 논리가 참이면 "statement" 문장 실행 - 세미콜론
pass 문
pass 혹은 ... (일명 ellipsis) 키워드는 실행될 때 아무런 작업을 수행하지 않는 문장이다. 차후에 소개할 조건문 및 반복문 등에 아무런 코드를 작성하지 않으면 실행할 코드가 없다는 사유로 오류가 발생하는데, 이러한 상황에서 pass 키워드는 임시 코드로 사용된다.
식별자
식별자(identifier), 일명 네임(name)은 프로그램의 데이터들을 구별하기 위해 사용되는, 즉 프로그래머가 데이터에 직접 붙여준 이름이다. 파이썬에서 식별자 작명에는 다음 규칙을 준수해야 한다:
- 오직 알파벳, 숫자, 밑줄
_만 허용 (그 외 특수문자 및 공백 사용 불가) - 식별자 첫 문자로 숫자 불허
- 대소문자 구분 필수
- 예약어 금지
예약어(reserved identifier)는 프로그래밍 언어에서 정해진 용도가 있어 개발자가 다른 용도로 사용할 수 없는 식별자이다. 위에서 언급한
pass문도 예약어에 해당한다.
주석
주석(comment)은 프로그램의 소스 코드로 취급하지 않아 실행되지 않는 영역이다. 흔히 코드에 대한 간단한 정보를 기입하기 위해 사용되는 데, 파이썬에는 두 가지의 주석이 존재한다.
| 블록 주석(block comment) | 독스트링(docstring) |
|---|---|
해시 기호 #로 표기되며 프로그램이 실행될 때 필터되는 주석이다. | 세 쌍의 따옴표로 표기된 주석은 프로그램이 실행되는 런타임에도 유지된다. |
|
|
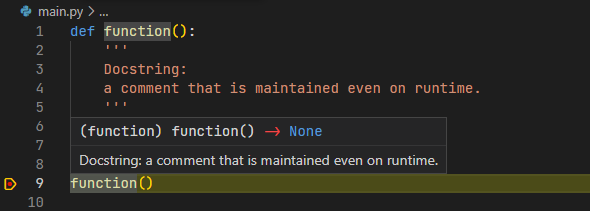
일반 주석과 달리, 사용자가 정의한 데이터에 기입된 독스트링은 __doc__이란 특수한 변수에 저장되어 디버깅 과정에서도 정의된 데이터에 대한 설명을 확인할 수 있는 용도로 사용된다. 이를 기반으로 IDE 및 텍스트 편집기는 아래 사진처럼 데이터를 정의한 소스 코드를 찾아가지 않고서도 곧바로 내용을 살펴볼 수 있다.
콘솔 입출력
파이썬은 다음과 같이 콘솔에서 사용할 수 있는 텍스트 기반의 입력 및 출력 함수를 가진다:
-
입력 함수
input()입력 함수가 실행될 시,
input()의 소괄호()안에 있는 텍스트가 터미널에 나타나며 Enter/Return을 누를 때까지 대기한다. -
출력 함수
print()출력 함수가 실행될 시,
print()의 소괄호()안에 있는 데이터가 터미널에 나타난다.
variable = input("입력: ")
print("출력:", variable) # 동일: print("출력:", input("입력: "))
입력: Hello World!
출력: Hello World!
하나의 print() 함수에서 두 개 이상의 데이터를 한꺼번에 출력하려면 쉼표 ,를 사용하여 연속적으로 데이터를 나열할 수 있다. 단, 각 쉼표가 위치한 곳에는 항상 공백이 놓여진다. 그 외의 다른 방법은 문자열 자료형을 설명하는 부분에서 소개한다.
A = 10.0
B = "파이썬"
# 텍스트와 숫자의 혼합된 데이터를 쉼표(,)를 사용해 나열한다.
print("A는", A , ", \n그리고 B는", B, "이다.")
A는 10.0 ,
그리고 B는 파이썬 이다.
탈출 문자(escape character)는 백슬래시 기호
\를 사용하여 문자열로부터 탈출해 텍스트 내에서 특정 연산을 수행한다:\n탈출 문자를 사용하여 문자열 줄바꿈을 구현한다.
변수
변수(variable)는 할당 기호 =를 사용하여 데이터를 할당(assignment)받을 수 있는 저장공간이다. 아래 예시는 variable이란 식별자의 변수에 숫자 3을 할당한다. 시스템 관점에서 바라보면 variable이란 이름에 숫자 3이란 데이터를 엮는 절차를 네임 바인딩(name binding)이라고 하며, 비로서 해당 식별자가 변수로 “정의(definition)”되었다고 한다.
# 변수 "variable"의 정의
variable = 3
파이썬의 변수는 반드시 네임 바인딩으로부터 정의되어야 하므로, 아무런 데이터가 할당되지 않은 식별자는 변수로 간주되지 않아 오류가 발생한다.
variable
print(variable)
NameError: name 'variable' is not defined
이러한 언어적 특징은 C/C++와 같은 타 프로그래밍에서 자주 인용되는 “선언(declaration)” 및 “초기화(initialization)”란 용어가 파이썬 공식 문서에서 드믈게 언급된다.
거의 모든 프로그래밍 언어는 할당 기호를 기준으로 왼쪽에는 피할당자(변수), 오른쪽에는 할당자(데이터 혹은 변수)가 위치한다. 반대로 놓여질 경우, 오류가 발생하거나 원치 않는 결과가 도출될 수 있다. 파이썬의 변수는 기존과 다른 유형의 데이터를 언제든지 새로 할당받을 수 있다.
variable = 3
variable = "Hello World!"
print(variable)
Hello World!
del 문장
del 문장은 식별자에 바인딩된 데이터를 해제, 즉 변수의 정의를 무효화할 때 사용한다. 차후 동일한 식별자로 변수를 다시 정의할 수 있다.
# 변수 "variable"의 정의
variable = "Hello World!"
print(variable)
# 변수 "variable" 네임 바인딩 해제
del variable
print(variable)
Hello World!
NameError: name 'variable' is not defined
자료형
자료형(data type)은 데이터의 내용물을 결정하는 요소이며, 파이썬에서는 크게 세 개의 자료형으로 나뉘어진다.
숫자 자료형
숫자 자료형(numeric data type)은 숫자로 표현되는 데이터들을 가리키며, 총 세 가지로 세분화된다.
int | float | complex |
|---|---|---|
| 소수점이 없는 정수 | 소수점을 포한한 64비트 실수 | 실수와 허수로 구성된 복소수 |
위의 숫자 자료형들은 산술 연산이 가능하다: 가장 기본적인 +, -, *, / 사칙 연산자부터 나눗셈의 몫 //과 나머지 % 그리고 제곱 **을 구할 수 있다. 산술 연산을 쉽게 읽을 수 있도록 숫자와 산술 연산자 사이에 공백을 넣어도 연산에는 아무런 영향을 주지 않으므로 무관한다.
인플레이스 연산자(in-place operator)는 할당 기호 =와 조합하여 산술 연산을 더욱 간결하게 작성할 수 있도록 한다: +=, -=, *=, /=, %= 등이 존재하며, x += y 문장은 x = x + y와 동일하다.
파이썬은 증가 연산자
++및 감소 연산자--를 지원하지 않는다.
논리 자료형
논리 자료형(Boolean data type)은 문장이 참인지 거짓인지 판별하는 논리 조건에 사용되는 데이터 유형이다.
True | False |
|---|---|
| 논리가 참일 때 반환; 0이 아닌 정수로 대체 가능 | 논리가 거짓일 때 반환; 정수 0으로 대체 가능 |
대표적인 논리 조건으로써 두 데이터를 대조하는 비교 연산자(relational operator)가 있다: 초과 >와 미만 <, 이상 >=과 이하 <=, 그리고 동일 ==와 다름 != 관계 부합 여부에 따라 논리적 참 혹은 거짓이 반환된다. 혹은 일치 여부를 확인하는 is 연산자와 같이 기호가 아닌 단어일 수도 있다.
동일
==과 일치is는 얼핏 비슷하지만 전혀 다른 연산자이다:==연산자는 데이터 유형마다 커스터마이징이 가능하여 무엇을 동일한 데이터로 판단할지 정할 수 있지만,is연산자는 커스터마이징이 불가하며 데이터가 정확히 일치해야 한다. 일부 데이터에서==연산자는is연산자와 동일하게 동작한다.
논리 연산자(logical operator)는 논리 자료형의 조합이 논리적으로 참인지 거짓인지 판별한다.
and: 모든 데이터가 참이면True를 반환하고, 그렇지 않으면False를 반환하는 논리곱이다.or: 하나 이상의 데이터가 참이면True를 반환하고, 그렇지 않으면False를 반환하는 논리합이다.not:True을False로, 혹은 그 반대로 논리값을 반전시키는 부정이다.
문자열 자료형
문자열 자료형(string data type)은 한 쌍의 작은 따옴표 '' 또는 큰 따옴표 ""로 구별되는 텍스트 데이터이다. 파이썬에서 문자열 자료형 데이터는 일반적으로 문자열 객체(string object)라고 부른다.
문자열 객체는 다른 데이터와 더하기 기호 +를 통해 공백없이 하나의 문자열로 연결할 수 있다. 문자열 간에만 사용할 수 있으므로 숫자 및 논리 자료형은 문자열로 변환해야 한다. 그 외에도 파이썬 3.6부터 추가된 접두사 f를 갖는 서식화된 문자열 리터럴(formatted string literal), 일명 f-문자열에서 중괄호 {}를 통해 원하는 위치에 곧바로 데이터 삽입이 가능하다.
| 문자열 연결 | 서식화된 문자열 리터럴 |
|---|---|
|
|
| |
세 쌍의 따옴표는 다중 문자열 객체를 생성하며, 이는 단순히 Enter/Return 키를 눌러 줄바꿈이 가능하다.
# 다중 문자열 객체로 여러 줄의 텍스트 작성 및 출력 print("""Hello World!""")Hello World!
차후에 설명할 예정이지만, 객체(object)에 해당하는 문자열 자료형 데이터는 오로지 자신만이 사용할 수 있는 고유의 기능(일명 메소드)을 갖으며 목록은 여기에서 확인할 수 있다.
# 문자열 객체의 메소드에 대한 몇 가지 예시
print("Hello World!".upper())
print("Hello World!".replace(" ", "-"))
HELLO WORLD!
Hello-World!
None 키워드
None 키워드는 자료형과 관계없이 아무런 값이 없는 데이터이다. 비록 None과 False는 개념적으로 완전히 다른 존재이지만, 논리 조건에서는 None을 False로 사용할 수 있다.
# 조건부 확인: 논리 조건에서 None을 False로 간주할 수 있는가?
if not(None and True):
print(None)
None
자료형 변환
파이썬 프로그래밍 언어는 데이터를 타 자료형으로 변환할 수 있는 함수를 제공한다.
| 자료형 변환 | 예시 |
|---|---|
정수 변환int() |
|
실수 변환float() |
|
문자열 변환str() |
|
들여쓰기
들여쓰기(indentation)는 문장이나 함수(function), 클래스(class) 코드의 경계를 표시하는데 사용된다. 이를 통해 코드가 조건문 혹은 반복문에 속하는지, 또는 어느 조건문 혹은 반복문의 코드인지 구분한다. 들여쓰기는 콜론 :이 시작되는 이후부터 삽입되며 탭(tab)이나 띄어쓰기 2칸 혹은 4칸으로 표현된다.
파이썬의 들여쓰기를 탭이나 띄어쓰기 중 어느 것을 사용하여도 무관하지만, 들여쓰기 방법은 반드시 하나로 통일해야 한다. 만일 탭과 띄어쓰기를 섞어서 사용하면 파이썬에서 들여쓰기를 제대로 구분하지 못하여 아래의 요류를 표시하면 실행되지 않는다.
TabError: inconsistent use of tabs and space in indentation
들여쓰기의 여부에 따라 코드의 내용이 완전히 변경될 수 있으므로 주의해야 한다.
조건
조건문(conditional statement)은 프로그래밍에 주어진 조건의 논리에 따라서 코드 실행 여부를 결정하는 가장 흔히 사용되는 코드 문장(statement) 중 하나이다. 본 장에서는 파이썬 프로그래밍의 조건에 따라 실행하는 조건문에 대하여 소개한다.
if 조건문
if 조건문은 조건 혹은 논리가 참(True)일 경우 코드를 실행하며, 거짓(False)일 경우에는 코드를 실행하지 않는다.
if condition:
...
# 간략화된 문장
if condition: ...
else 조건문
else 조건문은 단독으로 사용될 수 없으며 반드시 if 조건문 이후에 사용되어야 한다. 조건부가 거짓(False)으로 판정되면 실행할 코드를 포함한다.
if condition:
...
else:
...
elif 조건문
elif 조건문은 else와 if 조건문의 조합으로 이전 조건이 거짓(False)일 때 새로운 조건을 제시한다.
if condition:
...
elif condition:
...
else:
...
조건 연산자
조건 연산자(ternary operator)는 세 가지 인수만을 사용하여 조건문을 아래와 같이 간략하게 표현한다. 조건 연산자는 가독성을 감소시키므로 과용해서는 안되지만 변수 할당에 유용하다.
True_return if condition else False_return
match 조건문
본 조건문은 파이썬 3.10부터 추가된 기능으로, 자세한 내용은 PEP 643을 참고한다.
match 조건문은 전달받은 인자를 case의 패턴과 일치하는지 비교하여 논리가 참일 경우 해당 지점부터 코드를 실행하며, 거짓일 경우에는 다음 case로 넘어간다. 그 중에서 밑줄 _ 조건을 와일드카드(wildcard) 패턴이라 하여 무조건 실행되는 지점이다.
match argument:
case pattern1:
...
case pattern2:
...
case pattern3:
...
case _:
...
match 조건문은 타 프로그래밍 언어에서 소개되는 switch 조건문과 유사한 구조와 동작을 수행한다. 그러나 몇 가지 차이점이 있다면 case 문의 코드가 실행된 이후에 자동적으로 match 조건문이 종료되어 별도의 break 문이 필요하지 않다. 또한 패턴 뒤에 if 문을 기입하는 감시(guard) 표현식으로 부가적인 조건 일치여부를 거칠 수 있다.
반복
반복문(loop statement)은 프로그래밍에 주어진 조건의 논리에 따라서 코드를 얼마나 반복적으로 실행할 것인지 결정하는 가장 흔히 사용되는 코드 문장(statement) 중 하나이다. 본 장에서는 파이썬 프로그래밍의 조건에 따라 실행하는 반복문에 대하여 소개한다.
while 반복문
while 반복문은 조건 혹은 논리가 참(True)일 동안 코드를 반복적으로 실행하며, 거짓(False)일 경우에는 반복문을 종료한다.
while condition:
...
# 간략화된 문장
while condition: ...
else 조건문을 while 반복문 다음에 위치시키면 해당 코드는 반복문의 조건에 의해 정상적으로 종료되었을 경우에만 실행된다.
# 루프 종료: 반복 완료
index = 0
while index < 10:
index += 1
if index == 100:
break
else:
print("첫 번째 반복문...완료!")
# 루프 종료: 탈출문으로 강제 처리
index = 0
while index < 10:
index += 1
if index == 5:
break
else:
print("두 번째 반복문...완료!")
첫 번째 반복문...완료!
break 문
break 문(일명 탈출문)은 반복문을 조기 종료시키는데 사용된다. 반복 실행 도중에 탈출문을 마주치는 즉시 가장 인접한 반복문으로부터 탈출한다.
continue 문
continue 문은 반복문의 나머지 실행문을 전부 건너뛰어 다시 반복문의 조건부로 돌아간다. break와 달리 반복문은 종료되지 않고 여전히 살아있다.
for 반복문
for 반복문은 유효한 범위 내에서 코드를 반복적으로 실행하고, 범위의 모든 값이 반복되면 종료한다.
for index in iterable:
statements
# 간략화된 문장
for index in iterable: statement
여기서 지역 변수 index는 iterable에서 값을 얻고, 내부의 실행문은 더 이상 불러올 값이 없을 때까지 하나씩 반복한다. 흔히 반복문에 사용되는 iterable 데이터로 범위 객체, 리스트 객체, 또는 문자열 객체 등이 있다.
else 조건문을 for 반복문 다음에 위치시키면 해당 코드는 반복문의 조건에 의해 정상적으로 종료되었을 경우에만 실행된다.
# 루프 종료: 반복 완료
for index in range(10):
if index is 100:
break
else:
print("첫 번째 반복문...완료!")
# 루프 종료: 탈출문으로 강제 처리
for index in range(10):
if index is 5:
break
else:
print("두 번째 반복문...완료!")
첫 번째 반복문...완료!
이터러블
이터러블(iterable; 반복 가능한)은 저장된 여러 데이터 항목을 하나씩 반환할 수 있는 컨테이너 객체를 가리킨다. 이터러블의 특징인 __iter__() 메소드는 이터레이터(iterator) 객체를 반환하고, 그리고 이터레이터는 __next__() 메소드를 통해 for 반복문에 전달될 다음 데이터 항목을 반환한다. 다시 말해 이터러블 객체의 핵심은 순차적으로 데이터를 반환할 수 있다는 점이며, 다수의 데이터를 하나의 변수로 저장하는 성질은 이를 구현하기 위한 일환이다.
시퀀스 객체
시퀀스(sequence)는 슬라이싱과 같은 추가 기능이 활성화된 이터러블 객체이며, 대괄호 []를 사용하여 저장된 데이터 불러오거나 수정이 가능하다. 대표적인 시퀀스 객체 중 하나로 문자열이 있다.
variable = "Hello World!"
print(variable[1])
e
슬라이싱
슬라이싱(slicing; 자르다)은 시퀀스 객체 원본으로부터 원하는 부분만 추출하는 기능이다.
| 구문 | 예시 |
|---|---|
seq[start : end : interval] | start부터 end 이전까지 interval만큼의 간격으로 데이터를 추출하며, 모든 인수를 채울 필요는 없다. |
print("Hello World!"[2:8]) # 출력: 'llo Wo'
print("Hello World!"[2: ]) # 출력: 'llo World!'
print("Hello World!"[ :8]) # 출력: 'Hello Wo'
print("Hello World!"[2:8:2]) # 출력: 'oW'
시퀀스 언패킹
시퀀스 언패킹(sequence unpacking)은 시퀀스 객체의 요소들을 분할하는 것을 가리킨다. 하나의 시퀀스를 여러 변수에 할당하는 방식으로 언패킹하며, 변수의 접두부에는 별표 *를 기입하여 나머지 요소를 한꺼번에 받을 수 있다.
variable1, *variable2, variable3 = "Python"
variable1 = P
variable2 = ['y', 't', 'h', 'o']
variable3 = n
범위 객체
범위(range) 시퀀스 객체는 시작할 숫자, 끝을 맺을 숫자 그리고 순서 간격을 지정하여 일련의 숫자들을 순서에 맞게 저장하는 객체이며, range() 함수로부터 생성된다.
| 구문 | 예시 |
|---|---|
range(start, end, interval) | start부터 end 이전까지 interval만큼의 간격으로 순서대로 숫자를 나열한 범위 객체를 생성한다. |
for element in range(3, 10, 2):
print(element)
3
5
7
9
리스트 객체
리스트(list) 시퀀스 객체는 자료형과 관계없이 데이터를 나열한 순서대로 인덱스(index) 위치에 저장한다. 리스트의 데이터 할당은 대괄호 [] 내에 항목을 순서대로 쉼표로 나누어 나열한다. 대괄호는 0번부터 시작하는 인덱스 위치의 요소(element)를 호출할 때에도 사용된다.
variable = [value1, value2, value3, value4, ...]
print(variable) # 출력: [value1, value2, value3, value4, ...]
print(variable[0]) # 출력: value1
개별 요소를 재할당하여 데이터를 변경할 수 있다. 리스트 범위를 벗어난 요소를 호출할 수 없으므로, 이러한 경우 오류가 발생한다. 그래도 파이썬의 리스트를 비교적 유연한 편으로 append() 혹은 insert() 메소드를 통해 언제든지 확장할 수 있다. 리스트의 메소드는 여기에서 더 찾아볼 수 있다.
variable = []
print(variable) # 출력: []
variable.append("Python")
print(variable) # 출력: ['Python']
variable[1] = "Hello World!" # IndexError: list assignment index out of range
리스트는 고유의 연산을 통해 항목을 추가하거나 곱할 수가 있다. 아래의 연산들은 리스트 객체에만 제한되지 않으며, 차후에 소개될 다른 시퀀스 객체에도 적용이 가능하다.
-
시퀀스 연결
+print([value1, value2] + [value2, value3, value4]) # 출력: [value1, value2, value2, value3, value4] -
시퀀스 반복
*print([value1, value2] * 3) # 출력: [value1, value2, value1, value2, value1, value2] -
시퀀스 항목 존재여부
inprint(value1 in [value1, value2]) # 출력: True
리스트 컴프리헨션
리스트 컴프리헨션(list comprehension)은 for 반복문 (그리고 if 조건문)을 활용한 프로그램적 규칙에 따라 리스트를 생성한다.
| 구문 | 예시 |
|---|---|
[ for in if ] |
[element for variable in sequence if condition] |
리스트 객체의 element 요소는 sequence 시퀀스 객체 내에서 condition 조건에 부합한 항목을 넘겨받은 variable 변수로부터 할당받는다.
variable = [var**2 for var in range(5)]
variable = [var**2 for var in range(5) if (var ** 2) % 2 == 0]
[0, 1, 4, 9, 16]
[0, 4, 16]
튜플 객체
튜플(tuple) 시퀀스 객체는 리스트와 마찬가지로 항목을 순서대로 저장하는 데이터이나, 초기화 후에는 값을 변경할 수 없다. 이러한 시퀀스 객체의 속성을 불변(immutable)이라고 한다. 튜플을 초기화 할 때 소괄호 ()를 사용하거나 괄호 없이 사용할 수도 있다.
variable = (value1, value2, value3)
''' 동일:
variable = value1, value2, value3
'''
print(variable) # 출력: (value1, value2, value3)
print(variable[0]) # 출력: value1
튜플은 요소의 값을 변경할 수 없으며, 이를 시도할 경우 오류가 발생한다.
tpl = value1, value2, value3
tpl[1] = value4 # TypeError: 'variable' object does not support item assignment
딕셔너리 객체
딕셔너리(dictionary)는 인덱싱 역할의 키(key)와 해당 인덱스에 할당되는 값(value) 쌍을 하나의 요소로 갖는 (시퀀스가 아닌) 이터러블 객체이다. 딕셔너리는 중괄호 {} 안에 key: value을 나열하여 초기화한다. 딕셔너리의 값은 대괄호 안에 해당하는 키를 기입하여 호출한다.
단, 리스트와 딕셔너리 등의 가변(mutable) 이터러블 객체는 키로 사용될 수 없다.
variable = {key1: value1, key2: value2}
print(variable[key1]) # 출력: value1
print(variable[key2]) # 출력: value2
개별 요소를 재할당하여 데이터를 변경할 수 있다. 딕셔너리 범위를 벗어난 요소를 호출할 수 없으므로, 이러한 경우 오류가 발생한다. 그래도 파이썬의 딕셔너리는 비교적 유연한 편으로 새로운 키와 함께 값을 할당하는 것만으로 확장이 가능하다.
variable = {key1: value1, key2: value2}
variable[key3] = value3
print(variable) # 출력: {key1: value1, key2: value2, key3: value3}
딕셔너리 언패킹
딕셔너리 언패킹(dictionary unpacking)은 딕셔너리 객체의 요소들을 분할하는 것을 가리킨다. 단, 언패킹된 key: value 쌍을 활용할 수 있는 곳은 딕셔너리에 한정되므로 결국 타 딕셔너리와 결합하는 용도로 사용된다. 언패킹할 딕셔너리 접두부에 두 개의 별표 **를 기입한다.
variable = {key1: value1, key2: value2}
print({**variable, key3: value3}) # 출력: {key1: value1, key2: value2, key3: value3}
집합 객체
집합(set) 객체는 요소의 고유성을 보장하는, 즉 중복 요소를 허용하지 않는 (시퀀스가 아닌) 이터러블 객체이다. 딕셔너리와 마찬가지로 집합 초기화에는 중괄호 {}를 사용하지만 key: value 형태가 아니다. 집합은 대괄호를 통해 개별 요소를 호출이 불가하다. 집합 객체에서 요소를 추가 혹은 제거하려면 add(), remove() 등의 별도 메소드를 사용해야 한다.
variable = {value1, value2}
variable.add(value3)
print(variable) # {value1, value2, value3}
print(variable[0]) # TypeError: 'variable' object is not subscriptable
빈 집합 객체는 반드시
set()함수로 생성해야 한다; 빈 중괄호{}는 오히려 딕셔너리를 만들기 때문이다.
집합 객체 연산자는 수학의 집합에서 사용되는 연산과 동일하게 작용한다.
| 연산자 | 이름 | 설명 |
|---|---|---|
| |
합집합 | 두 집합의 합을 반환한다. |
& |
교집합 | 두 집합에 존재하는 요소만 반환한다. |
- |
여집합 | 피감수 집합에만 존재하며 감수 집합에 없는 요소를 반환한다. |
^ |
대칭차 | 한 집합에는 존재하나 둘 다 속하지 않는 요소를 반환한다. |
variable1 = {1, 2, 3, 4, 5, 6}
variable2 = {4, 5, 6, 7, 8, 9}
print(variable1 | variable2) # 출력: {1, 2, 3, 4, 5, 6, 7, 8, 9}
print(variable1 & variable2) # 출력: {4, 5, 6}
print(variable1 - variable2) # 출력: {1, 2, 3}
print(variable1 - variable2) # 출력: {7, 8, 9}
print(variable1 ^ variable2) # 출력: {1, 2, 3, 7, 8, 9}
제너레이터 함수
제너레이터(generator)는 yield 키워드와 반복문을 통해 요소들을 프로그램적으로 직접 생성할 수 있는 함수이다. 요소들이 메모리에 저장되는 것이 아니라 코드를 통해 생성되는 것이기 때문에, 제너레이터 함수는 메모리 제한이 없는 점에서 무한한 개수의 데이터를 담을 수 있는 이점을 가진다.
제너레이터에서 가장 중요한 것은
yield키워드로 이터러블 객체로써 반환될 데이터를 지정한다.
# 제네레이터 함수
def generator_function():
variable = 0
while variable < 5
yield var
var += 1
# 제너레이터 반복으로 각 요소 반환
for variable in generator_function():
print(variable)
# 리스트 객체로 변환
lst = list(generator_function())
print(lst)
0
1
2
3
4
[0, 1, 2, 3, 4]
함수
함수(function)는 독립적인 코드 블록으로써 데이터를 처리하며, 재사용이 가능하고 호출 시 처리된 데이터를 보여주어 유동적인 프로그램 코딩을 가능하게 한다. 함수는 이름 뒤에 소괄호가 있는 function() 형식으로 구별된다.
variable = [0, 3, 5, 9]
print(len(variable))
# "print()" 출력 함수, 그리고 리스트 객체를 인자로 받아 리스트 길이를 반환하는 "len()" 함수
4
함수의 기능을 정의(definition)하기 위해 def 키워드를 사용한다. 만일 사용자가 함수를 정의하기도 전에 호출하면, 순차적으로 실행되는 파이썬의 특성에 의해 존재하지 않는 함수를 호출하는 것으로 간주하여 오류가 발생한다.
# 함수 정의
def function():
...
# 함수 호출
function()
함수명 뒤에 소괄호 () 기입여부에 따라 의미하는 바가 다르다.
-
function()은 함수에 정의된 코드를 실행한다.def function(): print("Hello World!") variable = function() print("반환:", variable)Hello World! 반환: None -
function은 함수 자체를 가리킨다.def function(): print("Hello World!") variable = function print("반환:", variable)반환: <function function at 0x0000027FB6A57160>
return 반환문
return 반환문은 함수로부터 데이터를 반환하는 함수 전용 문장이다. 반환문이 실행되면 하단에 코드가 남아 있음에도 불구하고 함수는 즉시 종료된다. 함수는 반환문을 반드시 필요로 하지 않으며, 이러한 경우에는 None 값이 반환되어 변수에 전달된다.
# return 반환문이 있는 사용자 정의 함수
def function():
print("Hello World!")
return 1 + 2
print(function())
Hello World!
3
지역 변수 및 전역 변수
파이썬 프로그래밍 언어에서 변수가 코드 중에서 어디에 정의되었는지에 따라 두 가지의 종류로 구분된다.
-
지역 변수(local variable)
함수나 클래스 내부에서 정의된 변수이다. 지역 변수에 저장된 데이터는 함수 (또는 클래스) 밖에서는 소멸되므로 외부에서 사용할 수 없다. 지역 변수의 특징을 활용하면 함수 (또는 클래스) 외부에서 정의된 변수 이름을 그대로 가져와 함수 (또는 클래스) 내부에서 동일한 이름이지만 전혀 다른 존재의 변수를 새롭게 정의할 수 있다.
variable = "Hello World!" def function(): variable = "Python" return variable print(function()) # 출력: Python print(variable) # 출력: Hello World! -
전역 변수(global variable)
함수나 클래스에 속하지 않은 외부에 정의된 변수이다. 전역 변수는 어느 함수 (또는 클래스)에서도 호출만으로 지역 변수와 함께 사용할 수 있다. 단, 변수의 충돌로 인한 예상치 못한 결과와 오류를 방지하기 위해 가급적 전역 변수의 사용은 피하도록 한다.
variable = "Hello World!" def function(): print(variable) function() # 출력: Hello World! variable = "Python" function() # 출력: Python함수 (또는 클래스) 내에서 해당 변수가 지역 변수가 아니라 전역 변수임을 확실하게 명시하려면
global키워드를 사용한다. 하지만 가장 안전한 방법은 전역 변수를 함수의 인자로 전달하는 것이다.variable = "Hello World!" def function(): global variable variable = "Python" return variable print(function()) # 출력: Python print(variable) # 출력: Python
매개변수 및 전달인자
다음은 함수에 대해 논의할 때 중요하게 언급되는 매개변수와 전달인자의 차이에 대하여 설명한다.
- 전달인자 (argument): 간략하게 “인자”라고도 부르며, 함수로 전달되는 데이터이다.
- 매개변수 (parameter): 전달인자를 할당받는 함수 내의 지역 변수이다. 그러므로 매개변수는 함수 외부에서 호출이 불가능하다. 매개변수 선언은 함수의 소괄호
()내에서 이루어진다.
매개변수와 전달인자는 개념적으로 다른 존재이지만, 동일한 데이터를 가지고 있는 관계로 흔히 두 용어는 혼용되어 사용하는 경우가 많다.
다음은 매개변수에 사용되는 연산자로 전달인자을 받는데 유연성을 제공한다. 이들은 프로그래밍 구문상 명확한 구별이 가능해야 하므로 반드시 일반 매개변수 뒤에 위치해야 한다.
| 연산자 | 구문 | 설명 |
|---|---|---|
= |
arg=value |
전달인자가 없으면 기본값 value가 대신 매개변수에 할당된다. |
* |
*args |
시퀀스 언패킹으로 여러 개의 전달인자들을 하나의 튜플로 전달받는다. |
** |
**kwargs |
딕셔너리 언패킹으로 여러 개의 key = value 형식 전달인자들을 하나의 딕셔너리로 전달받는다. |
''' 예시. arg = value '''
def function(arg = "Python"):
print(arg)
function() # 출력: Python
function("Hello World!") # 출력: Hello World!
''' 예시. *args '''
def function(*args):
print(args)
function(1, 2, 3, 4) # 출력: (1, 2, 3, 4)
''' 예시. **kwargs '''
def function(**kwargs):
print(kwargs)
function(param1 = 3, param2 = "Hello World!") # 출력: {param1: 3, param2: 'Hello World!'}
순수 함수
순수 함수(pure function)는 동일한 인자를 전달하면 항상 같은 데이터가 반환되며, 전역변수와 같은 외부적 부작용(side effect) 영향이 없는 함수이다. 예를 들어, 코사인 함수 cos(x)의 반환값은 오로지 x 전달인자에만 의존하며 동일한 숫자가 입력되면 항상 같은 결과값이 나온다. 그러므로 코사인 함수는 순수 함수이다.
고차 함수
고차 함수(higher-order function)는 다른 함수를 전달인자로 사용하거나 함수를 반환하는 함수이다. 전달되거나 반환되는 함수들은 뒤에 소괄호 ()가 없어 실행되지는 않고, 하나의 변수처럼 여겨저 참조될 뿐이다.
고차 함수의 인자로 전달되는 함수를 콜백 함수(callback function)라고 부른다.
map() 함수
map() 함수는 이터러블 객체와 매개변수를 갖는 함수를 인자로 갖는 고차 함수이다. map() 함수는 이터러블 객체를 매개변수 함수의 인자로 전달하여 얻은 결과값으로 구성된, 즉 함수로 맵핑(mapping)된 리스트를 반환한다.
| 구문 |
|---|
map(function, iterable1, iterable2, ...) |
고차 map() 함수에서 이터러블 객체 iterable1와 iterable2가 function의 인자로 전달된다. |
SyntaxError와 같은 오류를 방지하려면 리스트나 튜플과 같은 이터러블 객체로 변환해야 한다.
lst1 = [1, 2, 3, 4, 5]
lst2 = [0, 9, 8, 7, 6, 5]
variable1 = map(lambda arg1, arg2: arg1 ** 2 + arg2, lst1, lst2)
variable2 = map(lambda arg2, arg1: arg1 ** 2 + arg2, lst2, lst1)
print(list(variable1))
print(list(variable2))
[1, 13, 17, 23, 31]
[1, 83, 67, 53, 41]
filter() 함수
filter() 함수는 이터러블 객체와 조건 함수(일명 술어; predicate)를 인자로 갖는 고차 함수이다. 술어의 조건에 만족하는 데이터만 필터링되어 구성된 이터러블 객체를 반환한다.
| 구문 |
|---|
filter(predicate, iterable) |
고차 filter() 함수에서 이터러블 객체 iterable는 predicate의 인자로 전달된다. |
SyntaxError와 같은 오류를 방지하려면 리스트나 튜플과 같은 이터러블 객체로 변환해야 한다.
lst = [1, 2, 3, 4, 5]
variable = filter(lambda arg: arg % 2 is 0, lst)
print(list(variable))
[2, 4]
데코레이터
데코레이터(decorator)는 함수의 기능을 수정하기 위해 사용되는 함수이며, 값을 반환하는 게 아니라 함수 자체를 반환한다. 데코레이터 고차 함수의 작업으로 반환된 함수를 차후에 사용하기 위해 이를 받아줄 변수가 필요하다.
# 본래 함수
def function():
...
# 데코레이터 생성
def decorator(func):
def modified_function():
"""
func() 함수를 포함한 문
"""
return modified_function
# 함수 수정하기(데코레이팅)
variable = decorator(function)
variable() # 실제로는 "variable"라는 이름의 변수에 할당된 함수이다.
# 함수 수정하기(데코레이팅): 함수 이름 유지
function = decorator(function)
function()
위의 데코레이터는 function()를 수정하였고 변수 variable 그리고 function에 할당하였으며, 후자의 경우는 함수명이 유지되었다고 볼 수 있다.
@ 기호
데코레이터의 @ 기호는 적용될 데코레이터 이름과 함께 수정될 함수 앞에 놓여 사용된다.
| 연산자 | 예시 | 설명 |
|---|---|---|
@ |
@decorator |
@decorator 는 function = decorator(function)를 대체한다. |
# 데코레이터 생성
def decorator(func):
def modified_function():
"""
func() 함수를 포함한 문
"""
return modified_function
# 함수 수정하기: @ 기호 사용
@decorator
def function(): # "function()"의 본래 함수
...
# 함수 이름은 그대로 유지된다.
function()
추가적으로, 수정될 함수에는 하나 이상의 데코레이터를 적용 할 수 있다.
@decorator1
@decorator2
def function():
...
수정될 함수로부터 가장 가까운 데코레이터가 우선적으로 적용된다. 그러므로 function() 함수는 먼저 @decorator2 다음 @decorator1 데코레이터 순서로 적용된다.
람다 표현식
람다 표현식(lambda expression), 일명 람다 함수(lambda function) 혹은 익명 함수(anonymous function)는 이름이 없는 (즉, 익명) 함수로써 단일 표현식으로만 값을 반환한다. 익명 함수는 lambda 키워드로 생성되어 흔히 일회용 함수 또는 고차 함수의 전달인자로 사용된다. 비록 식별자가 필요하지 않는 익명 함수일지라도, 람다 표현식은 재호출을 위해 일반 함수처럼 식별자를 가질 수 있다.
| 구문 |
|---|
lambda arg1, arg2 ∶ expression |
익명 함수는 매개변수 arg와 이를 반환하는 표현식 expression으로 구성된다. |
# 람다 표현식
variable = lambda arg1, arg2: 2 * arg1 + arg2
variable(2, 3) # 출력: 7
재귀 함수
재귀 함수(recursive function)는 스스로를 호출하는 함수이다. 재귀 함수는 반드시 스스로를 호출하는 반복으로부터 탈출하는 기저 조건(base case)이 필요하다. 기저 조건이 없으면 무한 재귀가 발생하는데 프로그램 실행에 기여하는 메모리가 부족하여 런타임 오류가 발생한다.
# 예제: 펙토리얼 "!"
def factorial(arg):
# 기저 조건: 재귀로부터 탈출하는 조건
if arg == 1:
return 1
else:
return arg * factorial(arg - 1)
클래스
클래스(class)는 객체를 생성하는데 사용된다.
객체(object 혹은 instance)는 데이터를 저장할 수 있는 변수와 처리할 수 있는 함수를 하나로 묶은 데이터이다. 객체의 변수와 함수는 각각 속성(attribute)과 메소드(method)라고 불리며, 이를 통틀어 맴버(member)라고 칭하고 다음과 같이 접근한다.
- 속성:
instance.attribute- 메소드:
instance.method()현재까지 다룬 내용 중에서 객체에 해당되는 데이터로는 문자열 객체와 시퀀스 객체가 있다.
variable = [0, 3, 5, 9] print(variable.index(5)) # "variable" 리스트 객체의 "index()" 메소드를 사용하여 값 5에 대한 위치를 반환한다.
클래스는 class 키워드를 사용하여 속성 및 메소드와 함께 정의된다. 클래스로부터 객체를 생성하는 것을 “객체화(instantiation)”라 부르는데, 이때 클래스에 정의된 맴버들은 캡슐화(encapsulation)되어 다음 특징을 갖는다:
- 변수와 함수가 하나의 객체로 결합된다.
- 우연치 않은 수정을 방지하기 위해 변수 및 함수에 대한 직접적인 접근을 외부로부터 제한할 수 있다.
객체 속성 및 메소드
객체 속성 및 메소드(instance attribute & method)는 클래스 내부에서 self 변수가 명시되어 정의된 변수와 함수이며, 오로지 객체만이 접근할 수 있다. self가 명시되지 않은 변수와 함수는 객체의 일부가 아니므로 지역 변수에 그치거나 접근이 불가하고, 이를 시도할 시 AttributeError 오류가 발생한다.
self변수는 객체 스스로를 지칭하는 변수이다. 여기서self란 이름은 관습적인 명칭일 뿐이며, 다른 식별자를 사용하여도 무관하다.
객체 속성을 정의하려면 반드시 self 변수를 사용할 수 있는 객체 메소드 내에서만 정의될 수 있다. 또한 객체 속성은 네임 바인딩이 되지 않은 채 선언만 되면 AttributeError 오류가 발생한다.
# 클래스 정의
class CLASS:
# 객체 메소드
def method(self, arg1, arg2):
# 객체 속성
self.attr1 = arg1
self.attr2 = arg2
variable = self.attr1 + self.attr2
print(f"{self.attr1} + {self.attr2} = {variable}")
# 클래스 객체화
instance = CLASS()
instance.method(2, 3) # 출력: 2 + 3 = 5
print(instance.attr1) # 출력: 2
print(instance.variable) # AttributeError: 'CLASS' object has no attribute 'variable'
__init__() 메소드
__init__()는 클래스 객체화가 이루어질 때마다 자동적으로 실행되는 특수한 메소드이다. 객체 속성을 초기화(initialization)하는 용도로 사용되며 객체화 과정에서 객체로 전달할 인자의 개수를 결정하는 요인으로 작용한다. 해당 메소드는 선택사항으로 객체화 시 초기화 및 인자 전달이 필요하지 않으면 생략하여도 된다.
# 클래스 정의
class CLASS:
# 객체 초기화 메소드
def __init__(self, arg1, arg2):
self.attr1 = arg1
self.attr2 = arg2
# 클래스 객체화
instance = CLASS(value1, value2)
클래스 속성 및 메소드
클래스 속성 및 메소드(class attribute & method)는 객체와 클래스로부터 직접 접근이 가능한 클래스 내부에 정의된 변수와 함수이다. 객체 메소드가 객체 스스로를 가리키는 self 변수가 있다면, 클래스 메소드는 클래스 스스로를 가리키는 cls 변수를 갖는다. 단, 클래스 메소드를 정의하기 위해서는 데코레이터가 필요하다.
| 구문 | 설명 |
|---|---|
@classmethod |
클래스 메소드를 선언하는데 사용되는 데코레이터이다. |
클래스 속성은 class 키워드 하에 곧바로 정의되거나, 혹은 cls 변수를 사용할 수 있는 클래스 메소드 내에서 정의될 수 있다. 또한 객체 속성은 네임 바인딩이 되지 않은 채 선언만 되면 AttributeError 오류가 발생한다.
객체 메소드를 정의할 때,
self변수를 통해 클래스 속성 및 메소드를 호출할 수 있다.
# 클래스 정의
class CLASS:
def __init__(self, arg):
self.method1(arg)
# 클래스 속성
attr1 = value1
# 클래스 메소드
@classmethod
def method1(cls, arg):
cls.attr2 = arg
# 클래스 메소드: 객체 생성
@classmethod
def method2(cls, arg):
return cls(cls.attr1 + cls.attr2 - arg)
# 클래스 객체화
instance1 = CLASS(value2)
print(f"{instance1.attr1}, {instance1.attr2}") # 출력: 2, 3
CLASS.method1(7)
print(f"{CLASS.attr1}, {CLASS.attr2}") # 출력: 2, 7
instance2 = CLASS.method2(1)
print(f"{instance2.attr1}, {instance2.attr2}") # 출력: 2, 8
정적 메소드
정적 메소드(static method)는 클래스에서만 직접 접근이 가능한 클래스 내부에 정의된 함수이다. 정적 메소드는 객체나 클래스를 가리키는 변수가 없어, 객체 및 클래스 맴버 호출이 불가하다. 즉, 정적 메소드는 단순히 클래스에 묶여있는 일반 함수와 같다. 정적 메소드를 정의하기 위해서는 데코레이터가 필요하다.
| 구문 | 설명 |
|---|---|
@staticmethod |
정적 메소드를 선언하는데 사용되는 데코레이터이다. |
# 클래스 정의
class CLASS:
# 정적 메소드 정의
@staticmethod
def method(arg1, arg2, arg3):
return arg1 + arg2 - arg3
print(CLASS.method(2, 3, 1)) # 출력: 4
매직 메소드
매직 메소드(magic method)는 특수한 목적을 가진 메소드로 식별자 양측에 던더(dunder; double underscore)가 있는 게 특징이다. 대표적으로 객체 초기화를 위한 __init__() 메소드가 있으며, 그 외에도 연산자 오버로딩에 흔히 사용된다.
| 연산자 | 이름 | 매직 메소드 |
|---|---|---|
+ |
산술: 덧셈 | __add__(self, arg) |
- |
산술: 뺄셈 | __sub__(self, arg) |
* |
산술 : 곱셈 | __mul__(self, arg) |
/ |
산술 : 나눗셈 | __truediv__(self, arg) |
& |
논리: AND | __and__(self, arg) |
^ |
논리: XOR | __xor__(self, arg) |
| |
논리: OR | __or__(self, arg) |
() |
인자호출 | __call__(self, arg) |
연산자 오버로딩
연산자 오버로딩(operator overloading)은 특정 클래스에서 연산자가 어떻게 동작할 지 정의하는 작업이다. 이를 위해 매직 메소드가 사용되며, 오버로드된 연산자는 해당 클래스에서만 적용된다.
# 클래스 정의
class CLASS:
def __init__(self, arg):
self.attr = arg
# 연산자 오버로딩: 덧셈
def __add__(self, arg):
return CLASS(self.attr + " " + arg.attr)
# 클래스 객체화
instance1 = CLASS("Hello")
instance2 = CLASS("World!")
instance3 = instance1 + instance2
''' 동일:
instance3 = instance1.__add__(instance2)
'''
print(instance3.attr) # 출력: Hello World!
상속
상속(inheritance)은 기반 클래스(base class)가 파생 클래스(derived class; 일명 서브클래스)에게 속성과 메소드를 제공하는 행위이다. 기반 클래스와 파생 클래스에 동일한 이름의 맴버가 존재할 경우, 기반 클래스의 맴버는 파생 클래스에 의해 묻힌다. 파생 클래스는 여러 기반 클래스로부터 동시에 상속받을 수 있다.
# 기반 클래스 정의
class BASECLASS:
attr1 = 3
attr2 = "Python"
def __init__(self):
print("초기화: 기반 클래스")
def method(self, arg1, arg2):
return arg1 + arg2
# 파생 클래스 정의
class DERIVEDCLASS(BASECLASS):
attr2 = "Hello World!"
attr3 = True
def __init__(self):
print("초기화: 파생 클래스")
def method(self, arg1, arg2):
return arg1 * arg2
# 클래스 객체화
instance = DERIVEDCLASS()
print(instance.attr1, instance.attr2, instance.attr3)
print(instance.method(2, 3))
초기화: 파생 클래스
3 Hello World! True
6
super() 함수
super() 함수는 파생 클래스에 묻혀진 기반 클래스의 속성 및 메소드를 호출하는데 사용된다.
# 기반 클래스 정의
class BASECLASS:
attr1 = 3
attr2 = "Python"
def __init__(self):
print("초기화: 기반 클래스")
def method(self, arg1, arg2):
return arg1 + arg2
# 파생 클래스 정의
class DERIVEDCLASS(BASECLASS):
attr2 = "Hello World!"
attr3 = True
def __init__(self):
super().__init__() # 기반 클래스 초기화
self.attr2 = super().attr2 # 기반 클래스의 attr2 속성
print("초기화: 파생 클래스")
def method(self, arg1, arg2):
return super().method(arg1, arg2) # 기반 클래스의 method() 메소드
# 클래스 객체화
instance = DERIVEDCLASS()
print(instance.attr1, instance.attr2, instance.attr3)
print(instance.method(2, 3))
초기화: 기반 클래스
초기화: 파생 클래스
3 Python True
5
프로퍼티
프로퍼티(property)는 하나의 속성을 getter, setter, 그리고 deleter 영역으로 나누어 데이터 숨기기(data hiding)을 지원한다.
| 프로퍼티 | 데코레이터 | 설명 |
|---|---|---|
| Getter | @property |
프로퍼티로부터 값을 반환받는 맴버이다. |
| Setter | @<프로퍼티명>.setter |
프로퍼티의 값을 설정하는 맴버이다. |
| Deleter | @<프로퍼티명>.deleter |
프로퍼티가 제거될 때 실행되는 맴버이다. |
속성을 나누므로써 수정되어서는 안될 민감한 코드를 setter 및 deleter 영역에 숨기고 getter만을 통해서 데이터를 반환한다. 정의된 형태는 메소드와 유사하지만 실제로 사용할 때는 소괄호 () 없이 속성처럼 사용된다. 프로퍼티의 setter와 deleter는 선택사항이지만, getter는 반드시 정의되어야 한다.
# 클래스 정의
class CLASS:
# Getter 프로퍼티 정의
@property
def method(self):
return self.attr ** 2
# Setter 프로퍼티 정의
@method.setter
def method(self, arg):
print("프로퍼티: attr 객체 속성 설정")
self.attr = arg + 1
# Deleter 프로퍼티 정의
@method.deleter
def method(self):
print("프로퍼티: attr 객체 속성 제거")
del self.attr
# 클래스 객체화
instance = CLASS()
instance.method = 3 # Setter 프로퍼티 호출
print(instance.method) # Getter 프로퍼티 호출
del instance.method # Deleter 프로퍼티 호출
프로퍼티: attr 속성 설정
16
프로퍼티: attr 속성 제거
예외 처리
예외(exception)는 잘못된 코딩이나 입력으로 인해 프로그램상 실행 불가능 코드 오류이다. 인터프리터에서 걸러지는 오류가 아니기에 정상적인 프로그램이 실행될 수 있으나, 예외가 발생하면 프로그램은 즉시 중단된다. 예외 처리는 실행된 프로그램이 예외로 인해 프로그램 실행이 중단되는 것을 방지하여 안정적으로 실행되는 것을 주목표로 한다.
try-except 예외 처리문
try-except 쌍은 예외를 감지하고 발생한 예외 유형에 따라 기입된 코드를 실행하여 처리된다. 예외 처리된 파이썬 프로세스는 도중에 중단되지 않고 계속 실행된다.
-
try문코드에 예외가 발생하는지 확인한다. 예외가 발생하였을 시, 나머지 코드는 실행되지 않고 예외 유형에 따라 해당하는
except문으로 넘어간다. -
except문try문에서 발생한 예외에 따라 실행되는 코드를 포함한다. 하나의try문에 여러except문을 사용하여 다양한 예외에 대비할 수 있다. 예외 유형을 기입하지 않으면 모든 유형의 예외를 처리하는 처리한다. 예외 유형의 목록은 여기에서 확인할 수 있다.
try:
...
except IndexError: # 예외 유형: 시퀀스 객체 범위를 초과하여 호출
...
except NameError: # 예외 유형: 존재하지 않은 식별자의 데이터 호출
...
except: # 예외 유형: 모든 유형의 예외 처리
...
다음은 try-except 예외 처리문 쌍을 보조하는 문장이며, 이들은 선택사항이다.
| 키워드 | 설명 |
|---|---|
else |
try 문에서 예외가 발생하지 않으면 실행되는 코드를 포함한다. |
finally |
try 문에서 예외가 발생 여부와 무관하게 마지막에 반드시 실행되는 코드를 포함한다. |
raise 문
raise 문은 의도적으로 예외를 발생시키는데 사용된다. 자체 제작 함수나 클래스에서 설계되지 않은 방식으로 접근하거나 사용하려는 경우, 해당 문으로 오류를 일으켜서 프로세스 실행을 즉시 중단시키는 용도로 활용된다.
# 명시적 예외 발생: 위의 'except' 문 내에서도 단독으로 사용할 수 있다.
raise
# 명시적으로 발생된 예외에 대한 자세한 설명을 제공한다.
raise "예외에 대한 설명 기입"
파일 관리
여러 데이터를 파이썬 프로세스에 전달하거나, 혹은 데이터를 외부로 출력하기 위해 파일을 불러와 read 혹은 write 하여 처리할 수 있다. 본 장은 파이썬에서 파일을 관리하는 방법에 대하여 소개한다.
파일 열기 및 닫기
파이썬에서 파일을 열고 닫으려면 open() 함수와 close() 메소드를 사용한다.
# 파일 열기: 읽기 전용
file = open("filename.txt", "r")
# 파일 닫기
file.close()
open() 함수에는 열고자 하는 파일경로 외에도 파일을 열기 위한 옵션을 설정할 수 있다.
| 전달인자 | 설명 |
|---|---|
r |
읽기 모드 (기본값) |
w |
덮어쓰기 모드 (새로 쓰기) |
a |
덧붙이기 모드 (내용 추가) |
rb |
바이너리 읽기 모드 (비텍스트 파일) |
wb |
바이너리 쓰기 모드 (비텍스트 파일) |
close() 메소드로 더 이상 사용하지 않는 파일을 닫아주는 습관은 리소스 낭비를 줄여주므로 매우 중요하다. 예외가 발생하여도 정상적으로 파일을 닫을 수 있도록 try/except 예외 처리문 혹은 with 문을 함께 사용할 것을 권장한다.
with 문
with 문은 해당 코드 블록 안에서만 사용할 수 있는 임시 변수를 생성한다. with 문으로 파일을 열었을 경우, 코드 블록이 종료되면 파일은 자동적으로 닫힌다.
with open("filename.txt") as file:
...
이를 가능케 하는 문맥 관리자(context manager)는 with 문을 지원하는 인터페이스 역할을 담당한다. 함수나 메소드에 문맥 관리자를 설정하는 방법은 두 가지가 있다:
-
__enter__()와__exit__()메소드# 컨텍스트 관리자 1 class CLASS: def __init__(self): pass # "with" 문 시작 시 실행 def __enter__(self): self.attr = expression return self.attr # "with" 문 종료 시 실행 def __exit__(self): ... -
contextlib모듈from contextlib import contextmanager # 컨텍스트 관리자 2 class CLASS: def __init__(self): ... # "with" 문 지원 함수 혹은 메소드 @contextmanager def method(self): self.attr = expression yield self.attr ...
문맥 관리자는 return 혹은 yield 문으로 반환/양도된 데이터를 with 문에서 처리할 수 있는 리소스로 제공한다. 해당 리소스는 as 키워드로 별도의 명칭을 지정하지 않는 이상 암묵적으로 처리 대상으로 지목된다.
# 클래스 객체화
instance = CLASS()
with instance.method():
# attr 객체 속성을 위주로 처리
...
대표적인 컨텍스트 관리자의 실제 적용 예시로는 머신러닝 프레임워크의 일부인 텐서보드(TensorBoard)에서 확인할 수 있다.
절대경로 및 상대경로
컴퓨터에는 두 종류의 경로 탐색법이 존재한다.
- 절대경로(absolute path): 시스템의 루트경로(예. 윈도우의
C:\혹은 리눅스의/)로부터 시작하여 탐색하는 방식이다. - 상대경로(relative path): 실행되고 있는 프로세스의 현 위치를 기준으로 경로를 탐색하는 방식이다.
경로를 지정할 때에는 백슬래시 두 개 \\로 폴더 및 파일을 구분한다. 하나만 사용하면 탈출 문자가 되어 원치 않은 텍스트 연산이 수행될 수 있다.
file = open("path\\filename.txt")
파일 읽기
파이썬에서 텍스트 기반 파일을 열었으면 read() 메소드로 파일 내용을 읽을 수 있다. 메소드의 인자로 정수를 건네면 파일로부터 지정한 바이트만큼 읽는다. 하나의 파일에서 read() 메소드는 여러 번 사용할 수 있으며, 마지막으로 읽은 부분에서부터 이어서 읽는다. 메소드에 인자를 전달하지 않으면 내용의 나머지 전부를 읽는다.
with open("path\\filename.txt") as file:
print(file.read(16)) # 내용 시작 부분에서부터 16 바이트를 읽는다.
print(file.read(4)) # 16 바이트 이후로부터 4 바이트를 읽는다.
print(file.read()) # 4 바이트 이후로부터 나머지 바이트를 읽는다.
print(file.read()) # 더 이상 읽을 내용이 없어 아무런 텍스트를 반환하지 않는다.
readlines() 메소드는 각 줄의 내용을 하나의 요소로 갖는 리스트 객체를 반환한다. 메소드의 인자로 정수를 건네면 파일로부터 지정한 바이트만큼 읽는다. 그러나 한 줄만 읽는 readline() 메소드와 혼돈하지 않도록 주의한다.
<filename.txt>
첫 번째 줄은 여기에.
두 번째 줄은 저기에.
마지막 줄은 어딘가에.
with open("path\\filename.txt") as file:
print(file.readlines())
print(file.readline())
['첫 번째 줄은 여기에.\n','두 번째 줄은 저기에.\n','마지막 줄은 어딘가에.']
첫 번째 줄은 여기에.
반복문을 이용한 내용 출력
각 줄의 텍스트 기반 파일 내용은 for 반복문을 다음과 같은 방법으로 사용해 출력할 수 있다.
for variable in file:
print(file)
파일 쓰기
파이썬에서 텍스트 기반 파일을 열었으면 write() 메소드로 파일 내용을 작성할 수 있다. 파일을 작성하는 모드에는 두 가지가 존재하며, 아래의 가상의 텍스트 파일을 예시로 든다:
<filename.txt>
첫 번째 줄은 여기에.
두 번째 줄은 저기에.
마지막 줄은 어딘가에.
-
덮어쓰기(overwrite) 모드
w는 기존의 모든 내용들을 삭제하여 처음부터 새로 작성한다.with open("path\\filename.txt", "w") as file: file.write("텍스트 덮어쓰기!")<filename.txt> 텍스트 덮어쓰기! -
덧붙여 쓰기(append) 모드
a는 기존의 모든 내용들을 유지한 채 맨 끝 단락에서부터 작성한다.with open("path\\filename.txt", "a") as file: file.write("텍스트 덧붙여 쓰기!")<filename.txt> 첫 번째 줄은 여기에. 두 번째 줄은 저기에. 마지막 줄은 어딘가에.텍스트 덧붙여 쓰기!
성공적으로 파일 작성을 완료하였으면 write() 메소드는 작성된 내용의 바이트 개수를 반환한다.
파일 생성
파이썬 파일의 write() 메소드는 기존 파일을 작성할 뿐만 아니라, 해당하는 이름의 파일을 찾을 수가 없다면 새로운 파일을 생성한다.
with open("path\\NEW_filename.txt", "w") as file:
file.write("새 파일 생성!")
<NEW_filename.txt>
새 파일 생성!
모듈
모듈(module)은 부가적인 기능 및 데이터를 제공하는 파이썬 소스 코드이며, 이들은 일반 스크립트와 마찬가지로 .PY 확장자를 갖는다. 파이썬 모듈을 불러오는 방법에는 두 가지가 있다:
-
import키워드에 모듈명을 기입하여 모듈에 정의된 모든 변수, 함수, 그리고 클래스를 불러온다.# 모듈 불러오기 import module # 모듈에 정의된 함수 호출 module.function() -
from키워드로 모듈명을 기입한 다음import키워드로 불러오고자 하는 변수, 함수, 혹은 클래스를 지정한다.만일 모든 변수, 함수, 그리고 클래스를 불러오려면
from module import *로 작성한다.# 모듈 불러오기: 선택적 from module import variable, function, classes # 모듈에 정의된 함수 호출 function()
불러온 모듈이나 변수, 함수, 그리고 클래스는 as 키워드를 통해 별칭을 지정할 수 있다. 이는 복잡하거나 긴 모듈명을 간단한 이름으로 호출하거나, 혹은 기존 데이터의 식별자와 중복되어 발생할 수 있는 문제를 방지하기 위해 사용된다.
# 모듈 별칭 지정
import module as alias
# 모듈 데이터 별칭 지정
from module import variable as alias1, function as alias2
진입점
진입점(entry point)는 프로그램이 시작되는 부분을 의미하지만, 파이썬 프로그래밍 언어는 단일 스크립트에서 상단에서부터 순차적으로 실행하므로 진입점에 대한 개념이 무색하다. 그 대신에 구동되고 있는 파이썬 프로세스가 해당 스크립트로부터 실행된 것인지, 아니면 모듈로써 불러온 것인지 판별이 가능하다.
# 진입점
if __name__ == "__main__":
...
절대로 비교 연산자
==는 논리 연산자is로 대체되어서는 안된다.
import 문으로 불러온 모듈이 정의된 변수, 함수, 그리고 클래스를 제공하기 위해서는 스크립트 내부에 작성된 코드를 실행해야 한다. 예를 들어, 정의와 상관없는 print() 출력 함수가 모듈에 작성되어 있으면 터미널에 해당 텍스트가 나타난다. 하지만 위의 조건문 하에 스크립트 코드를 작성하면 모듈로 불러올 때에는 실행되지 않는다. 그리고 파이썬 프로그래밍 언어에서는 이를 “진입점”이라고 부른다.
패키지
패키지(package)는 여러 모듈들을 하나의 공간으로 분류하는 일종의 네임스페이스(namespace)이다.
파이썬의 패키지는 폴더 형태를 취하고 있으며, 이는 인터프리터 설치 경로로부터
.\Lib\site-packages에서 찾아볼 수 있다.
모든 파이썬 패키지는 __init__.py라는 특수한 파이썬 파일을 반드시 가져야 한다. 비록 안에는 아무런 내용이 없더라도, 파이썬 인터프리터가 이를 패키지로 인식하도록 하는 중요한 역할을 한다.
import package.module
PyPI
PyPI(Python Package Index; 파이썬 패키지 목록)는 온라인 패키지 저장소로 파이썬 커뮤니티에서 제작한 상당수의 패키지를 보유한다. PyPI로부터 패키지를 설치하려면 pip 소프트웨어가 필요하다.
pip
pip는 파이썬 패키지 관리 소프트웨어이며 기본적으로 파이썬 인터프리터와 함께 설치된다. pip는 GUI가 갖춰진 프로그램이 아니므로 패키지 설치 및 관리는 명령 프롬프트 또는 파워셸과 같은 터미널에서 처리되어야 한다.
| 옵션 | 설명 | 명령어 |
|---|---|---|
install |
패키지 설치 | pip install 패키지 |
uninstall |
패키지 제거 | pip uninstall 패키지 |
list |
설치된 패키지 목록 | pip list |
윈도우 OS에서 pip를 사용할 경우, 단독적인 pip가 아닌 python -m pip 명령어를 사용하는 것을 권장한다(macOS 및 리눅스 제외).
python -m pip
특히 원도우 10 이상의 운영체제를 사용하는 경우 python을 입력하는 것만으로 마이크로소프트 스토어로 이동하게 되는데, 해결 방법은 두 가지가 있다.
python을py로 대체 (Python Launcher 프로그램 사용)- 컴퓨터에서 “설정 → 앱 → 앱 및 기능 → 앱 실행 별칭 관리”에서
python.exe및python3.exe을 해제 (본질적 문제 해결)
위의 명령어는 컴퓨터 환경설정에서 지정된 파이썬 인터프리터의 pip를 접속한다는 것을 의미한다. 이를 통해 인터프리터 간의 패키지 관리에 혼돈을 줄일 수 있다. 만일 32비트 파이썬 3.8 인터프리터가 설치되었다면 Python Launcher로 다음과 같이 접근한다.
py -3.8-32 -m pip
가상환경
가상환경(virtual environment)은 각 파이썬 프로젝트마다 런타임 환경을 고립시켜 타 프로젝트에 영향을 주지 않도록 한다. pip로 설치한 패키지들은 전부 인터프리터 경로에 설치되는데, 파이썬 프로젝트마다 서로 다른 버전의 패키지가 요구될 때 매우 골치아픈 상황이 발생한다. 바로 다른 버전의 동일한 패키지 설치가 불가하기 때문이다. 가상환경은 패키지를 프로젝트에 국한된 런타임 환경에 설치하므로 패키지 관리가 훨씬 용이하다.
본 장은 파이썬 3에 기본적으로 제공하는 venv 가상환경 패키지를 위주로 설명한다.
가상환경 생성
파이썬 프로젝트란, 단순히 개발 중인 파이썬 스크립트가 위치한 폴더를 가리킨다. 터미널에서 가상환경을 설정하려는 경로로 이동해 아래 명령어를 입력한다.
py -m venv .venv
이는 .venv라는 폴더를 생성하는데, 가상환경을 통해 설치한 패키지들은 전부 해당 폴더에 저장된다.
가상환경 활성
가상환경에 패키지를 설치하려면 우선 사용 중인 터미널에 가상환경을 활성시켜야 한다. 그렇지 않으면 설치한 패키지들은 가상환경이 아닌 시스템에 설치된 인터프리터 경로에 패키지가 설치된다.
명령줄 좌측에 (.venv)라는 표시가 나타났으면 가상환경 접속에 성공한 것이다.
가상환경 비활성
터미널에 가상환경을 비활성화하려면 아래의 명령어를 입력한다.
deactivate
이는 .venv\Scripts\deactivate 명령어를 입력하는 것과 동일하다. 그러므로 프로젝트 경로를 다른 위치로 옮기면 deactivate 명령어가 동작하지 않아 손수 경로를 찾아 deactivate 파일을 실행해야 한다.